Логистическая регрессия - Logistic regression
В статистика, то логистическая модель (или же логит модель) используется для моделирования вероятности существования определенного класса или события, например, пройден / не пройден, выиграл / проиграл, жив / мертв или здоров / болен. Это может быть расширено для моделирования нескольких классов событий, таких как определение наличия на изображении кошки, собаки, льва и т. Д. Каждому обнаруживаемому на изображении объекту будет присвоена вероятность от 0 до 1 с суммой, равной единице.
Логистическая регрессия - это статистическая модель который в своей основной форме использует логистическая функция моделировать двоичный зависимая переменная, хотя многие более сложные расширения существовать. В регрессивный анализ, логистическая регрессия[1] (или же логит-регрессия) является оценка параметры логистической модели (форма бинарная регрессия ). Математически бинарная логистическая модель имеет зависимую переменную с двумя возможными значениями, такими как годен / не годен, которая представлена индикаторная переменная, где два значения помечены как «0» и «1». В логистической модели логарифмические шансы (в логарифм из шансы ) для значения с меткой "1" является линейная комбинация одного или нескольких независимые переменные («предсказатели»); каждая независимая переменная может быть двоичной переменной (два класса, кодируемых индикаторной переменной) или непрерывная переменная (любое реальное значение). Соответствующие вероятность значения, помеченного «1», может варьироваться от 0 (обязательно значение «0») до 1 (безусловно, значение «1»), отсюда и маркировка; функция, которая преобразует логарифмические шансы в вероятность, является логистической функцией, отсюда и название. В единица измерения для логарифмической шкалы шансов называется логит, из бревноИстик ООНЭто, отсюда и альтернативные имена. Аналогичные модели с другим сигмовидная функция вместо логистической функции также может использоваться, например пробит модель; Определяющей характеристикой логистической модели является то, что увеличение одной из независимых переменных мультипликативно увеличивает шансы данного результата на постоянный ставка, при этом каждая независимая переменная имеет свой собственный параметр; для двоичной зависимой переменной это обобщает отношение шансов.
В модели бинарной логистической регрессии зависимая переменная имеет два уровня (категоричный ). Выходы с более чем двумя значениями моделируются полиномиальная логистическая регрессия и, если несколько категорий упорядоченный, к порядковая логистическая регрессия (например, порядковая логистическая модель пропорциональных шансов[2]). Сама модель логистической регрессии просто моделирует вероятность выхода с точки зрения входных данных и не выполняет статистическая классификация (это не классификатор), хотя его можно использовать для создания классификатора, например, путем выбора порогового значения и классификации входных данных с вероятностью больше порогового значения как один класс, ниже порогового значения как другой; это обычный способ сделать двоичный классификатор. Коэффициенты обычно не вычисляются с помощью выражения в закрытой форме, в отличие от линейный метод наименьших квадратов; видеть § Примерка модели. Логистическая регрессия как общая статистическая модель была первоначально разработана и популяризирована в первую очередь Джозеф Берксон,[3] начиная с Берксон (1944), где он изобрел «логит»; видеть § История.
| Часть серии по |
| Регрессивный анализ |
|---|
 |
| Модели |
| Оценка |
| Фон |
|
Приложения
Логистическая регрессия используется в различных областях, включая машинное обучение, большинство областей медицины и социальных наук. Например, оценка травмы и тяжести травмы (ТРИСС ), который широко используется для прогнозирования смертности травмированных пациентов, изначально был разработан Бойдом. и другие. с помощью логистической регрессии.[4] Многие другие медицинские шкалы, используемые для оценки степени тяжести состояния пациента, были разработаны с использованием логистической регрессии.[5][6][7][8] Логистическая регрессия может использоваться для прогнозирования риска развития данного заболевания (например, сахарный диабет; ишемическая болезнь сердца ) на основе наблюдаемых характеристик пациента (возраст, пол, индекс массы тела, результаты различных анализы крови, так далее.).[9][10] Другой пример может заключаться в прогнозировании того, проголосует ли непальский избиратель за Конгресс Непала, Коммунистическую партию Непала или любую другую партию, исходя из возраста, дохода, пола, расы, государства проживания, голосов на предыдущих выборах и т. Д.[11] Техника также может быть использована в инженерное дело, особенно для прогнозирования вероятности отказа данного процесса, системы или продукта.[12][13] Он также используется в маркетинг такие приложения, как прогнозирование склонности клиента к покупке продукта или прекращению подписки и т. д.[14] В экономика его можно использовать для прогнозирования вероятности того, что человек выберет рабочую силу, а бизнес-приложение может предсказать вероятность того, что домовладелец не выполнит свои обязательства по ипотека. Условные случайные поля, расширение логистической регрессии на последовательные данные, используются в обработка естественного языка.
Примеры
Логистическая модель
Эта секция может содержать чрезмерное количество сложных деталей, которые могут заинтересовать только определенную аудиторию. В частности, действительно ли нам нужно использовать а другие не общие базы в примере?. (Март 2019 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |

Давайте попробуем понять логистическую регрессию, рассмотрев логистическую модель с заданными параметрами, а затем посмотрим, как можно оценить коэффициенты на основе данных. Рассмотрим модель с двумя предикторами, и , и одна бинарная (Бернулли) переменная ответа , который мы обозначим . Мы предполагаем линейная связь между переменными-предикторами и логарифм (также называемое логитом) события, которое . Эта линейная зависимость может быть записана в следующей математической форме (где ℓ это логарифм шансов, является основанием логарифма, а параметры модели):







Мы можем восстановить шансы возведением в степень логарифма шансов:
- .

Путем простых алгебраических манипуляций вероятность того, что является
- .

Где это сигмовидная функция с базой Приведенная выше формула показывает, что однажды фиксированы, мы можем легко вычислить либо логарифмические шансы, что для данного наблюдения или вероятность того, что для данного наблюдения. Основным вариантом использования логистической модели является наблюдение. , и оценим вероятность который . В большинстве приложений база логарифма обычно принимается равным е. Однако в некоторых случаях проще сообщить результаты, работая с основанием 2 или основанием 10.



Рассмотрим пример с , а коэффициенты , , и . Чтобы быть конкретным, модель





куда вероятность того, что .
Это можно интерпретировать так:
- это у-перехват. Логарифмические шансы события , когда предикторы . Возведя в степень, мы можем увидеть, что когда шансы того, что от 1 до 1000, или . Аналогично вероятность того, что когда можно вычислить как .
- означает, что увеличение на 1 увеличивает логарифмические шансы на . Так что если увеличивается на 1, вероятность того, что увеличиться в раз . Обратите внимание, что вероятность из также увеличилось, но не настолько, насколько увеличились шансы.
- означает, что увеличение на 1 увеличивает логарифмические шансы на . Так что если увеличивается на 1, вероятность того, что увеличиться в раз Обратите внимание, как эффект на логарифм вдвое больше, чем эффект , но влияние на шансы в 10 раз больше. Но влияние на вероятность из не в 10 раз больше, это только влияние на шансы в 10 раз больше.







Для оценки параметров исходя из данных, необходимо провести логистическую регрессию.
Вероятность сдачи экзамена по сравнению с часами обучения
Чтобы ответить на следующий вопрос:
Группа из 20 студентов тратит от 0 до 6 часов на подготовку к экзамену. Как количество часов, потраченных на обучение, влияет на вероятность сдачи студентом экзамена?
Причина использования логистической регрессии для этой проблемы заключается в том, что значения зависимой переменной, пройден и не пройден, хотя и представлены «1» и «0», не являются Количественные числительные. Если задача была изменена таким образом, что «годен / не годен» был заменен оценкой 0–100 (количественные числа), то простой регрессивный анализ может быть использован.
В таблице показано количество часов, проведенных каждым учащимся, и указано, прошли они (1) или не прошли (0).
| Часы | 0.50 | 0.75 | 1.00 | 1.25 | 1.50 | 1.75 | 1.75 | 2.00 | 2.25 | 2.50 | 2.75 | 3.00 | 3.25 | 3.50 | 4.00 | 4.25 | 4.50 | 4.75 | 5.00 | 5.50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Проходить | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
График показывает вероятность сдачи экзамена в зависимости от количества часов обучения, с кривой логистической регрессии, подобранной к данным.
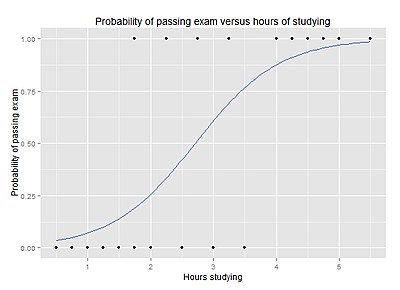
Логистический регрессионный анализ дает следующий результат.
| Коэффициент | Std.Error | z-значение | P-значение (Вальд) | |
|---|---|---|---|---|
| Перехватить | −4.0777 | 1.7610 | −2.316 | 0.0206 |
| Часы | 1.5046 | 0.6287 | 2.393 | 0.0167 |
Вывод показывает, что количество часов обучения в значительной степени связано с вероятностью сдачи экзамена (, Тест Вальда ). Вывод также предоставляет коэффициенты для и . Эти коэффициенты вводятся в уравнение логистической регрессии для оценки шансов (вероятности) сдачи экзамена:




Предполагается, что один дополнительный час учебы увеличит логарифмическую вероятность успешного прохождения теста на 1,5046, таким образом, умножая шансы пройти мимо Форма с Икс-перехват (2.71) показывает, что эта оценка равные шансы (логарифм-шансы 0, шансы 1, вероятность 1/2) для студента, который учится 2,71 часа.

Например, для студента, который учится 2 часа, введите значение в уравнении дает оценочную вероятность сдачи экзамена 0,26:


Аналогичным образом, для студента, который учится 4 часа, оценочная вероятность сдачи экзамена составляет 0,87:

В этой таблице показана вероятность сдачи экзамена для нескольких значений часов обучения.
| Часы исследования | Сдача экзамена | ||
|---|---|---|---|
| Лог-шансы | Шансы | Вероятность | |
| 1 | −2.57 | 0.076 ≈ 1:13.1 | 0.07 |
| 2 | −1.07 | 0.34 ≈ 1:2.91 | 0.26 |
| 3 | 0.44 | 1.55 | 0.61 |
| 4 | 1.94 | 6.96 | 0.87 |
| 5 | 3.45 | 31.4 | 0.97 |
Результат анализа логистической регрессии дает p-значение , который основан на z-оценке Вальда. Вместо метода Вальда рекомендуемый метод[нужна цитата ] для расчета p-значения для логистической регрессии критерий отношения правдоподобия (LRT), что для этих данных дает .

Обсуждение
Логистическая регрессия может быть биномиальной, порядковой или полиномиальной. Биномиальная или бинарная логистическая регрессия имеет дело с ситуациями, в которых наблюдаемый результат для зависимая переменная может иметь только два возможных типа: «0» и «1» (которые могут представлять, например, «мертвый» против «живого» или «выигрышный» против «проигрышного»). Полиномиальная логистическая регрессия имеет дело с ситуациями, когда результат может иметь три или более возможных типа (например, «болезнь A» против «болезни B» против «болезни C»), которые не упорядочены. Порядковая логистическая регрессия имеет дело с упорядоченными зависимыми переменными.
В бинарной логистической регрессии результат обычно кодируется как «0» или «1», поскольку это приводит к наиболее простой интерпретации.[15] Если конкретный наблюдаемый результат для зависимой переменной является заслуживающим внимания возможным результатом (называемым «успехом», «экземпляром» или «случаем»), он обычно кодируется как «1», а противоположный результат (называемый «сбой» или «неэкземпляр» или «не случай») как «0». Бинарная логистическая регрессия используется для прогнозирования шансы быть случаем, основанным на ценностях независимые переменные (предикторы). Шансы определяются как вероятность того, что конкретный исход является случаем, деленный на вероятность того, что это не случай.
Как и другие формы регрессивный анализ логистическая регрессия использует одну или несколько переменных-предикторов, которые могут быть непрерывными или категориальными. Однако, в отличие от обычной линейной регрессии, логистическая регрессия используется для прогнозирования зависимых переменных, которые принимают членство в одной из ограниченного числа категорий (рассматривая зависимую переменную в биномиальном случае как результат Бернулли суд ), а не постоянный результат. Учитывая эту разницу, предположения линейной регрессии нарушаются. В частности, остатки не могут быть нормально распределены. Кроме того, линейная регрессия может делать бессмысленные прогнозы для двоичной зависимой переменной. Что необходимо, так это способ преобразования двоичной переменной в непрерывную, которая может принимать любое реальное значение (отрицательное или положительное). Для этого биномиальная логистическая регрессия сначала вычисляет шансы события, происходящего на разных уровнях каждой независимой переменной, а затем принимает логарифм для создания непрерывного критерия в виде преобразованной версии зависимой переменной. Логарифм шансов - это логит вероятности логит определяется следующим образом:

Хотя зависимой переменной в логистической регрессии является Бернулли, логит имеет неограниченный масштаб.[15] Функция logit - это функция ссылки в такой обобщенной линейной модели, т.е.

Y - переменная отклика, распределенная по Бернулли, и Икс - переменная-предиктор; в β значения - линейные параметры.
В логит вероятности успеха затем подгоняется к предикторам. Прогнозируемое значение логит преобразуется обратно в предсказанные шансы через обратный натуральный логарифм - экспоненциальная функция. Таким образом, хотя наблюдаемая зависимая переменная в бинарной логистической регрессии представляет собой переменную 0 или 1, логистическая регрессия оценивает шансы, как непрерывную переменную, того, что зависимая переменная является «успехом». В некоторых приложениях все, что нужно, - это ставки. В других случаях требуется конкретный прогноз типа «да» или «нет» для определения того, является ли зависимая переменная «успехом»; это категориальное предсказание может быть основано на вычисленных шансах на успех, при этом предсказанные шансы выше некоторого выбранного значения отсечения переводятся в предсказание успеха.
Предположение о линейных предсказательных эффектах можно легко ослабить с помощью таких методов, как сплайновые функции.[16]
Логистическая регрессия против других подходов
Логистическая регрессия измеряет взаимосвязь между категориальной зависимой переменной и одной или несколькими независимыми переменными путем оценки вероятностей с использованием логистическая функция, которая является кумулятивной функцией распределения логистическая дистрибуция. Таким образом, он рассматривает тот же набор проблем, что и пробит регрессия используя аналогичные методы, причем последний использует вместо этого кумулятивную кривую нормального распределения. Точно так же в интерпретации скрытых переменных этих двух методов первый предполагает стандартную логистическая дистрибуция ошибок и второй эталон нормальное распределение ошибок.[17]
Логистическую регрессию можно рассматривать как частный случай обобщенная линейная модель и таким образом аналогично линейная регрессия. Однако модель логистической регрессии основана на совершенно иных предположениях (о взаимосвязи между зависимыми и независимыми переменными) от предположений линейной регрессии. В частности, ключевые различия между этими двумя моделями можно увидеть в следующих двух особенностях логистической регрессии. Во-первых, условное распределение это Распределение Бернулли а не Гауссово распределение, потому что зависимая переменная является двоичной. Во-вторых, предсказанные значения являются вероятностями и поэтому ограничены (0,1) через функция логистического распределения потому что логистическая регрессия предсказывает вероятность конкретных результатов, а не самих результатов.

Логистическая регрессия - альтернатива методу Фишера 1936 года, линейный дискриминантный анализ.[18] Если допущения линейного дискриминантного анализа верны, обусловленность может быть отменена для получения логистической регрессии. Однако обратное неверно, потому что логистическая регрессия не требует многомерного нормального допущения дискриминантного анализа.[19]
Скрытая интерпретация переменных
Логистическую регрессию можно понять просто как нахождение параметры, которые лучше всего подходят:


куда ошибка, распространяемая стандартом логистическая дистрибуция. (Если вместо этого используется стандартное нормальное распределение, это пробит модель.)

Связанная скрытая переменная . Срок ошибки не соблюдается, и поэтому также ненаблюдаемый, поэтому называется «скрытым» (наблюдаемые данные представляют собой значения и ). Однако в отличие от обычной регрессии параметры не могут быть выражены какой-либо прямой формулой и значения в наблюдаемых данных. Вместо этого они должны быть найдены с помощью итеративного процесса поиска, обычно реализуемого программой, которая находит максимум сложного «выражения вероятности», которое является функцией всех наблюдаемых и значения. Подход к оценке объясняется ниже.




Логистическая функция, шансы, отношение шансов и логит




Определение логистической функции
Объяснение логистической регрессии можно начать с объяснения стандарта. логистическая функция. Логистическая функция - это сигмовидная функция, который принимает любые настоящий Вход , () и выводит значение от нуля до единицы;[15] для логита это интерпретируется как ввод логарифм и имея выход вероятность. В стандарт логистическая функция определяется следующим образом:



График логистической функции на т-интервал (−6,6) показан на рисунке 1.
Предположим, что является линейной функцией одного объясняющая переменная (случай, когда это линейная комбинация множественных независимых переменных рассматривается аналогично). Затем мы можем выразить следующее:

И общая логистическая функция теперь можно записать как:


В логистической модели интерпретируется как вероятность зависимой переменной приравнивается к успеху / кейсу, а не к провалу / отсутствию дела. Понятно, что переменные ответа не одинаково распределены: отличается от одной точки данных другому, хотя они независимы матрица дизайна и общие параметры .[9]





Определение обратной логистической функции
Теперь мы можем определить логит (логарифмические шансы) функционируют как обратная стандартной логистической функции. Легко видеть, что он удовлетворяет:


и, что то же самое, после возведения в степень обе стороны имеем шансы:

Толкование этих терминов
В приведенных выше уравнениях используются следующие члены:
- это функция логита. Уравнение для показывает, что логит (т.е. логарифм шансов или натуральный логарифм шансов) эквивалентен выражению линейной регрессии.
- обозначает натуральный логарифм.
- - вероятность того, что зависимая переменная соответствует случаю, при некоторой линейной комбинации предикторов. Формула для иллюстрирует, что вероятность того, что зависимая переменная приравнивается к случаю, равна значению логистической функции выражения линейной регрессии. Это важно, поскольку показывает, что значение выражения линейной регрессии может изменяться от отрицательной до положительной бесконечности, и все же после преобразования результирующее выражение для вероятности колеблется от 0 до 1.
- это перехватить из уравнения линейной регрессии (значение критерия, когда предиктор равен нулю).
- - коэффициент регрессии, умноженный на некоторое значение предиктора.
- основание обозначает экспоненциальную функцию.






Определение шансов
Шансы зависимой переменной равны случаю (при некоторой линейной комбинации предикторов) эквивалентна экспоненциальной функции выражения линейной регрессии. Это показывает, как логит служит связующей функцией между вероятностью и выражением линейной регрессии. Учитывая, что логит находится в диапазоне от отрицательной до положительной бесконечности, он обеспечивает адекватный критерий для проведения линейной регрессии, а логит легко конвертируется обратно в шансы.[15]
Итак, мы определяем шансы зависимой переменной, равной случаю (при некоторой линейной комбинации предикторов) следующим образом:

Отношение шансов
Для непрерывной независимой переменной отношение шансов можно определить как:

Эта экспоненциальная зависимость дает интерпретацию : Шансы умножаются на на каждую единицу увеличения x.[20]


Для двоичной независимой переменной отношение шансов определяется как куда а, б, c и d клетки в 2 × 2 Таблица сопряженности.[21]

Несколько независимых переменных
Если есть несколько независимых переменных, приведенное выше выражение может быть изменен на . Затем, когда это используется в уравнении, связывающем логарифм шансов успеха со значениями предикторов, линейная регрессия будет множественная регрессия с м толкователи; параметры для всех j = 0, 1, 2, ..., м все оцениваются.



Опять же, более традиционные уравнения:

и

где обычно .

Примерка модели
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Октябрь 2016) |
Логистическая регрессия - важная машинное обучение алгоритм. Цель состоит в том, чтобы смоделировать вероятность случайной величины. 0 или 1 с учетом экспериментальных данных.[22]
Рассмотрим обобщенная линейная модель функция параметризована ,


Следовательно,

и с тех пор , Мы видим, что дан кем-то Теперь рассчитаем функция правдоподобия предполагая, что все наблюдения в выборке независимо распределены по Бернулли,




Обычно логарифмическая вероятность максимальна,

который максимизируется с помощью таких методов оптимизации, как градиентный спуск.
Если предположить пары выбираются равномерно из основного распределения, то в пределе большихN,

![{ displaystyle { begin {align} & lim limits _ {N rightarrow + infty} N ^ {- 1} sum _ {i = 1} ^ {N} log Pr (y_ {i} mid x_ {i}; theta) = sum _ {x in { mathcal {X}}} sum _ {y in { mathcal {Y}}} Pr (X = x, Y = y) log Pr (Y = y mid X = x; theta) [6pt] = {} & sum _ {x in { mathcal {X}}} sum _ {y in { mathcal {Y}}} Pr (X = x, Y = y) left (- log { frac { Pr (Y = y mid X = x)} { Pr (Y = y mid X = x; theta)}} + log Pr (Y = y mid X = x) right) [6pt] = {} & - D _ { text {KL}} (Y parallel Y _ { theta}) - H (Y mid X) end {выравнивается}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b300972d40831096c1ab7bdf34338a71eca96d9)
куда это условная энтропия и это Дивергенция Кульбака – Лейблера. Это приводит к интуиции, что, максимизируя логарифмическую вероятность модели, вы сводите к минимуму отклонение KL вашей модели от максимального распределения энтропии. Интуитивно ищите модель, которая делает наименьшее количество предположений в своих параметрах.


«Правило десяти»
Широко используемое эмпирическое правило "правило один из десяти ", заявляет, что модели логистической регрессии дают стабильные значения для независимых переменных, если они основаны как минимум на примерно 10 событиях на каждую независимую переменную (EPV); где мероприятие обозначает случаи, относящиеся к менее частой категории в зависимой переменной. Таким образом, исследование предназначено для использования независимые переменные для события (например, инфаркт миокарда ) ожидается в пропорции участников исследования потребуется в общей сложности участников. Тем не менее, есть серьезные споры о надежности этого правила, которое основано на исследованиях моделирования и не имеет надежного теоретического обоснования.[23] По мнению некоторых авторов[24] правило слишком консервативно, некоторые обстоятельства; при этом авторы заявляют: «Если мы (несколько субъективно) считаем охват доверительного интервала менее 93 процентов, ошибку типа I более 7 процентов или относительную систематическую ошибку более 15 процентов как проблемные, наши результаты показывают, что проблемы довольно часты с 2–4 EPV, редко встречается при 5–9 EPV и все еще наблюдается при 10–16 EPV. Наихудшие случаи каждой проблемы не были серьезными при 5–9 EPV и обычно сопоставимы с таковыми при 10–16 EPV ».[25]


Другие получили результаты, которые не согласуются с вышеизложенным, с использованием других критериев. Полезным критерием является то, будет ли подобранная модель, как ожидается, достичь той же прогностической дискриминации в новой выборке, которую она достигла в образце для разработки модели. Для этого критерия может потребоваться 20 событий для каждой переменной-кандидата.[26] Кроме того, можно утверждать, что 96 наблюдений необходимы только для оценки точки пересечения модели с достаточной точностью, чтобы предел ошибки в предсказанных вероятностях составлял ± 0,1 при уровне достоверности 0,95.[16]
Оценка максимального правдоподобия (MLE)
Коэффициенты регрессии обычно оцениваются с использованием оценка максимального правдоподобия.[27][28] В отличие от линейной регрессии с нормально распределенными остатками, невозможно найти выражение в замкнутой форме для значений коэффициентов, которые максимизируют функцию правдоподобия, поэтому вместо этого следует использовать итерационный процесс; Например Метод Ньютона. Этот процесс начинается с предварительного решения, его немного изменяют, чтобы посмотреть, можно ли его улучшить, и повторяют это изменение до тех пор, пока улучшения не прекратятся, после чего процесс считается сходимым.[27]
В некоторых случаях модель может не достичь сходимости. Несходимость модели указывает на то, что коэффициенты не имеют смысла, потому что итерационный процесс не смог найти подходящие решения. Неспособность сойтись может произойти по ряду причин: большое отношение предикторов к случаям, мультиколлинеарность, редкость, или заполнить разделение.
- Большое отношение переменных к наблюдениям приводит к чрезмерно консервативной статистике Вальда (обсуждается ниже) и может привести к несходимости. Регулярный логистическая регрессия специально предназначена для использования в этой ситуации.
- Мультиколлинеарность означает недопустимо высокие корреляции между предикторами. По мере увеличения мультиколлинеарности коэффициенты остаются несмещенными, но увеличиваются стандартные ошибки и уменьшается вероятность сходимости модели.[27] Чтобы обнаружить мультиколлинеарность между предикторами, можно провести линейный регрессионный анализ с интересующими предикторами с единственной целью - изучить статистику толерантности. [27] используется для оценки недопустимо высокой мультиколлинеарности.
- Разреженность данных означает наличие большой доли пустых ячеек (ячеек с нулевым счетчиком). Нулевое количество ячеек особенно проблематично с категориальными предикторами. С непрерывными предикторами модель может вывести значения для нулевого количества ячеек, но это не относится к категориальным предикторам. Модель не будет сходиться при нулевом количестве ячеек для категориальных предикторов, потому что натуральный логарифм нуля является неопределенным значением, поэтому окончательное решение модели не может быть достигнуто. Чтобы решить эту проблему, исследователи могут свернуть категории теоретически значимым образом или добавить константу ко всем ячейкам.[27]
- Другой числовой проблемой, которая может привести к отсутствию сходимости, является полное разделение, которое относится к случаю, когда предикторы идеально предсказывают критерий - все случаи точно классифицируются. В таких случаях следует повторно проверить данные, поскольку, вероятно, есть какая-то ошибка.[15][требуется дальнейшее объяснение ]
- Можно также использовать полупараметрический или непараметрический подходы, например, с помощью методов локального правдоподобия или непараметрических методов квази-правдоподобия, которые избегают предположений о параметрической форме для индексной функции и устойчивы к выбору функции связи (например, пробит или логит).[29]
Функция потери кросс-энтропии
В приложениях машинного обучения, где для двоичной классификации используется логистическая регрессия, MLE минимизирует Перекрестная энтропия функция потерь.
Метод наименьших квадратов с итеративным перевесом (IRLS)
Бинарная логистическая регрессия ( или же ) можно, например, рассчитать с помощью методом наименьших квадратов с повторным взвешиванием (IRLS), что эквивалентно максимальному увеличению логарифмическая вероятность из Бернулли распределил процесс с использованием Метод Ньютона. Если задача записана в векторной матричной форме, с параметрами , объясняющие переменные и математическое ожидание распределения Бернулли , параметры можно найти с помощью следующего итеративного алгоритма:


![{ displaystyle mathbf {w} ^ {T} = [ beta _ {0}, beta _ {1}, beta _ {2}, ldots]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/daccbf84c2c936e0559016491efe98eaf0eca430)
![{ Displaystyle mathbf {x} (я) = [1, x_ {1} (я), x_ {2} (я), ldots] ^ {T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8fc5f11bdd42f672417a3f4e44b3a4e5be28faa)



куда диагональная матрица весов, вектор ожидаемых значений,

![{ Displaystyle { boldsymbol { mu}} = [ mu (1), mu (2), ldots]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/800927e9be36f4cac166a68862c04234cffd67b8)

Матрица регрессора и вектор переменных ответа. Более подробную информацию можно найти в литературе.[30]
![{ Displaystyle mathbf {y} (я) = [y (1), y (2), ldots] ^ {T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33cbd315328b6ccfc7f216d65e39f92a8ec48694)
Оценка степени соответствия
Доброту соответствия в моделях линейной регрессии обычно измеряется с помощью р2. Поскольку у этого нет прямого аналога в логистической регрессии, различные методы[31]:глава 21 вместо этого можно использовать следующее.
Тесты на отклонение и отношение правдоподобия
В линейном регрессионном анализе речь идет о разделении дисперсии с помощью сумма площадей расчеты - дисперсия критерия по существу делится на дисперсию, учитываемую предикторами, и остаточную дисперсию. В логистическом регрессионном анализе отклонение используется вместо вычисления суммы квадратов.[32] Отклонение аналогично вычислению суммы квадратов в линейной регрессии.[15] и является мерой несоответствия данным в модели логистической регрессии.[32] Когда доступна «насыщенная» модель (модель с теоретически идеальным соответствием), отклонение рассчитывается путем сравнения данной модели с насыщенной моделью.[15] Это вычисление дает критерий отношения правдоподобия:[15]

В приведенном выше уравнении D представляет отклонение, а ln представляет собой натуральный логарифм. Логарифм этого отношения правдоподобия (отношение подобранной модели к насыщенной модели) даст отрицательное значение, следовательно, потребуется отрицательный знак. D можно показать, чтобы следовать приблизительному распределение хи-квадрат.[15] Меньшие значения указывают на лучшее соответствие, поскольку подобранная модель меньше отклоняется от насыщенной модели. При оценке по распределению хи-квадрат незначительные значения хи-квадрат указывают на очень небольшую необъяснимую дисперсию и, следовательно, хорошее соответствие модели. И наоборот, значительное значение хи-квадрат указывает на то, что значительная величина дисперсии необъяснима.
Когда насыщенная модель недоступна (общий случай), отклонение рассчитывается просто как −2 · (логарифмическая вероятность подобранной модели), и ссылка на логарифмическую вероятность насыщенной модели может быть без вреда для всех последующих.
В логистической регрессии особенно важны два показателя отклонения: нулевое отклонение и отклонение модели. Нулевое отклонение представляет собой разницу между моделью только с точкой пересечения (что означает «без предикторов») и насыщенной моделью. Отклонение модели представляет собой разницу между моделью с хотя бы одним предиктором и насыщенной моделью.[32] В этом отношении нулевая модель обеспечивает основу для сравнения моделей предикторов. Учитывая, что отклонение является мерой разницы между данной моделью и насыщенной моделью, меньшие значения указывают на лучшее соответствие. Таким образом, чтобы оценить вклад предиктора или набора предикторов, можно вычесть отклонение модели из нулевого отклонения и оценить разницу на распределение хи-квадрат с степени свободы[15] равна разнице в количестве оцениваемых параметров.

Позволять
![{ displaystyle { begin {align} D _ { text {null}} & = - 2 ln { frac { text {вероятность нулевой модели}} { text {вероятность насыщенной модели}}} [6pt] D _ { text {fit}} & = - 2 ln { frac { text {вероятность подобранной модели}} { text {вероятность насыщенной модели}}}. End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85ab8f60a3e7685815b132b3a80d03d26d9745a)
Тогда разница обоих:
![{ displaystyle { begin {align} D _ { text {null}} - D _ { text {fit}} & = - 2 left ( ln { frac { text {вероятность нулевой модели}} { text {вероятность насыщенной модели}}} - ln { frac { text {вероятность соответствия модели}} { text {вероятность насыщенной модели}}} right) [6pt] & = - 2 ln { frac { left ({ dfrac { text {вероятность нулевой модели}} { text {вероятность насыщенной модели}}} right)} { left ({ dfrac { text {вероятность подобранной модели}} { text {вероятность насыщенной модели}}} right)}} [6pt] & = - 2 ln { frac { text {вероятность нулевой модели}} { text {вероятность подобранной модели}}}. end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd851b7e234a5483dbb21da9fff7d9d2419e3e3e)
Если отклонение модели значительно меньше нулевого отклонения, то можно сделать вывод, что предиктор или набор предикторов значительно улучшили соответствие модели. Это аналогично F-тест используется в линейном регрессионном анализе для оценки значимости прогноза.[32]
Псевдо-R-квадрат
В линейной регрессии квадрат множественной корреляции, р² используется для оценки степени соответствия, поскольку представляет собой долю отклонения критерия, которая объясняется предикторами.[32] В логистическом регрессионном анализе нет согласованной аналогичной меры, но есть несколько конкурирующих мер, каждая из которых имеет ограничения.[32][33]
На этой странице рассматриваются четыре наиболее часто используемых индекса и один менее часто используемый:
- Отношение правдоподобия р²L
- Кокс и Снелл р²CS
- Нагелькерке р²N
- McFadden р²McF
- Тюр р²Т
р²L дается Коэном:[32]

Это наиболее аналогичный показатель квадрату множественных корреляций в линейной регрессии.[27] Он представляет собой пропорциональное уменьшение отклонения, при этом отклонение рассматривается как мера отклонения, аналогичная, но не идентичная измерению. отклонение в линейная регрессия анализ.[27] Одно ограничение отношения правдоподобия р² заключается в том, что он не связан монотонно с соотношением шансов,[32] Это означает, что оно не обязательно увеличивается с увеличением отношения шансов и не обязательно уменьшается с уменьшением отношения шансов.
р²CS альтернативный показатель качества соответствия, связанный с р² значение из линейной регрессии.[33] Выдается:
![{ displaystyle { begin {align} R _ { text {CS}} ^ {2} & = 1- left ({ frac {L_ {0}} {L_ {M}}} right) ^ {2 / n} [5pt] & = 1-e ^ {2 ( ln (L_ {0}) - ln (L_ {M})) / n} end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8d7fd894a2491abc493151c9aecafec2bb3cd9b8)
куда LM и {{mvar | L0} - это вероятность подгонки модели и нулевой модели соответственно. Индекс Кокса и Снелла проблематичен, поскольку его максимальное значение составляет . Максимальное значение этого верхнего предела может составлять 0,75, но оно может легко достигать 0,48, когда предельная доля случаев мала.[33]

р²N обеспечивает исправление Кокса и Снелла р² так, чтобы максимальное значение было равно 1. Тем не менее, коэффициенты Кокса и Снелла и отношение правдоподобия р²s показывают большее согласие друг с другом, чем с Nagelkerke р².[32] Конечно, это может быть не так для значений, превышающих 0,75, поскольку индекс Кокса и Снелла ограничен этим значением. Отношение правдоподобия р² часто предпочитают альтернативным вариантам, поскольку он наиболее аналогичен р² в линейная регрессия, не зависит от базовой ставки (как Кокса, так и Снелла и Нагелькерке р²s увеличивается при увеличении доли случаев от 0 до 0,5) и изменяется от 0 до 1.
р²McF определяется как

и предпочтительнее р²CS пользователя Allison.[33] Два выражения р²McF и р²CS связаны соответственно соотношением
![{ displaystyle { begin {matrix} R _ { text {CS}} ^ {2} = 1- left ({ dfrac {1} {L_ {0}}} right) ^ { frac {2 ( R _ { text {McF}} ^ {2})} {n}} [1.5em] R _ { text {McF}} ^ {2} = - { dfrac {n} {2}} cdot { dfrac { ln (1-R _ { text {CS}} ^ {2})} { ln L_ {0}}} end {matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f5537e92777913de25ddaa5b8909c8e7f008ccf)
Однако сейчас Эллисон предпочитает р²Т это относительно новая мера, разработанная Tjur.[34] Его можно рассчитать в два этапа:[33]
- Для каждого уровня зависимой переменной найдите среднее значение прогнозируемых вероятностей события.
- Возьмите абсолютное значение разности этих средних значений.
При интерпретации псевдо-р² статистика. Причина, по которой эти показатели соответствия упоминаются как псевдо р² заключается в том, что они не отражают пропорционального уменьшения ошибки, как р² в линейная регрессия делает.[32] Линейная регрессия предполагает гомоскедастичность, что дисперсия ошибки одинакова для всех значений критерия. Логистическая регрессия всегда будет гетероскедастический - дисперсии ошибок различаются для каждого значения прогнозируемой оценки. Для каждого значения прогнозируемой оценки будет свое значение пропорционального уменьшения ошибки. Поэтому неуместно думать о р² как пропорциональное уменьшение ошибки в универсальном смысле логистической регрессии.[32]
Тест Хосмера – Лемешоу
В Тест Хосмера – Лемешоу использует тестовую статистику, которая асимптотически следует за распределение чтобы оценить, соответствует ли наблюдаемая частота событий ожидаемой частоте событий в подгруппах модельной популяции. Некоторые статистики считают этот тест устаревшим из-за его зависимости от произвольного объединения предсказанных вероятностей и относительно низкой мощности.[35]

Коэффициенты
После подбора модели вполне вероятно, что исследователи захотят изучить вклад отдельных предикторов. Для этого они захотят изучить коэффициенты регрессии. В линейной регрессии коэффициенты регрессии представляют изменение критерия для каждого изменения единицы в предикторе.[32] Однако в логистической регрессии коэффициенты регрессии представляют изменение логита для каждого изменения единицы в предикторе.Учитывая, что логит не является интуитивно понятным, исследователи, вероятно, сосредоточатся на влиянии предсказателя на экспоненциальную функцию коэффициента регрессии - отношения шансов (см. определение ). В линейной регрессии значимость коэффициента регрессии оценивается путем вычисления т тест. В логистической регрессии существует несколько различных тестов, предназначенных для оценки значимости отдельного предиктора, в первую очередь тест отношения правдоподобия и статистика Вальда.
Тест отношения правдоподобия
В критерий отношения правдоподобия Рассмотренная выше процедура оценки соответствия модели также является рекомендуемой процедурой для оценки вклада отдельных «предикторов» в данную модель.[15][27][32] В случае модели с одним предиктором, просто сравнивают отклонение модели предиктора с отклонением от нулевой модели на распределении хи-квадрат с одной степенью свободы. Если модель предиктора имеет значительно меньшее отклонение (c.f хи-квадрат с использованием разницы в степенях свободы двух моделей), то можно сделать вывод, что существует значимая связь между "предиктором" и результатом. Хотя некоторые общие статистические пакеты (например, SPSS) действительно предоставляют статистику теста отношения правдоподобия, без этого требовательного к вычислениям теста было бы труднее оценить вклад отдельных предикторов в случае множественной логистической регрессии.[нужна цитата ] Чтобы оценить вклад отдельных предикторов, можно ввести предикторы иерархически, сравнивая каждую новую модель с предыдущей, чтобы определить вклад каждого предиктора.[32] Статистики спорят о целесообразности так называемых «пошаговых» процедур.[ласковые слова ] Есть опасения, что они могут не сохранить номинальные статистические свойства и ввести в заблуждение.[36]
Статистика Вальда
В качестве альтернативы, при оценке вклада отдельных предикторов в данной модели, можно исследовать значимость Статистика Вальда. Статистика Вальда, аналогичная т-тест в линейной регрессии, используется для оценки значимости коэффициентов. Статистика Вальда представляет собой отношение квадрата коэффициента регрессии к квадрату стандартной ошибки коэффициента и асимптотически распределяется как распределение хи-квадрат.[27]

Хотя несколько статистических пакетов (например, SPSS, SAS) сообщают статистику Вальда для оценки вклада отдельных предикторов, статистика Вальда имеет ограничения. Когда коэффициент регрессии велик, стандартная ошибка коэффициента регрессии также имеет тенденцию быть больше, увеличивая вероятность Ошибка типа II. Статистика Вальда также имеет тенденцию к смещению, когда данные немногочисленны.[32]
Выборка случай-контроль
Допустим, случаи редкие. Тогда мы могли бы пожелать отбирать их чаще, чем их распространенность в популяции. Например, предположим, что есть заболевание, которым страдает 1 человек из 10 000, и для сбора данных нам необходимо пройти полное обследование. Проведение тысяч медицинских осмотров здоровых людей для получения данных только по нескольким больным может оказаться слишком дорогостоящим. Таким образом, мы можем оценить большее количество больных, возможно, все редкие исходы. Это также ретроспективная выборка, или, что то же самое, ее называют несбалансированными данными. Как показывает практика, выборка элементов управления, в пять раз превышающих количество наблюдений, дает достаточные данные управления.[37]
Логистическая регрессия уникальна тем, что она может быть оценена на несбалансированных данных, а не на случайно выбранных данных, и при этом дает правильные оценки коэффициентов влияния каждой независимой переменной на результат. То есть, если мы сформируем логистическую модель из таких данных, если модель верна в общей популяции, все параметры верны, кроме . Мы можем исправить если мы знаем истинную распространенность следующим образом:[37]

куда истинная распространенность и - распространенность в выборке.


Формальная математическая спецификация
Существуют различные эквивалентные спецификации логистической регрессии, которые вписываются в различные типы более общих моделей. Эти разные спецификации позволяют делать разные полезные обобщения.
Настраивать
Базовая настройка логистической регрессии выглядит следующим образом. Нам дан набор данных, содержащий N точки. Каждая точка я состоит из набора м входные переменные Икс1,я ... Иксм, я (также называемый независимые переменные, предикторные переменные, функции или атрибуты) и двоичный переменная результата Yя (также известный как зависимая переменная, переменная ответа, выходная переменная или класс), то есть он может принимать только два возможных значения: 0 (часто означает «нет» или «сбой») или 1 (часто означает «да» или «успех»). Целью логистической регрессии является использование набора данных для создания модели прогнозирования переменной результата.
Некоторые примеры:
- Наблюдаемые результаты - это наличие или отсутствие данного заболевания (например, диабета) у группы пациентов, а объясняющими переменными могут быть характеристики пациентов, которые считаются соответствующими (пол, раса, возраст, артериальное давление, индекс массы тела, так далее.).
- Наблюдаемые результаты - это голоса (например, Демократичный или же Республиканец ) группы людей на выборах, а объясняющими переменными являются демографические характеристики каждого человека (например, пол, раса, возраст, доход и т. д.). В таком случае один из двух результатов произвольно кодируется как 1, а другой как 0.
Как и в линейной регрессии, переменные результата Yя предполагается, что они зависят от объясняющих переменных Икс1,я ... Иксм, я.
- Объясняющие переменные
Как показано выше в приведенных выше примерах, объясняющие переменные могут быть любыми тип: ценный, двоичный, категоричный и т. д. Основное различие между непрерывные переменные (например, доход, возраст и артериальное давление ) и дискретные переменные (например, пол или раса). Дискретные переменные, относящиеся к более чем двум возможным вариантам, обычно кодируются с использованием фиктивные переменные (или же индикаторные переменные ), то есть отдельные независимые переменные, принимающие значение 0 или 1, создаются для каждого возможного значения дискретной переменной, где 1 означает «переменная имеет данное значение», а 0 означает «переменная не имеет этого значения».
Например, четырехсторонняя дискретная переменная группа крови с возможными значениями «A, B, AB, O» можно преобразовать в четыре отдельных двусторонних фиктивных переменных: «is-A, is-B, is-AB, is-O», где только одна из них имеет значение 1, а все остальные имеют значение 0. Это позволяет сопоставить отдельные коэффициенты регрессии для каждого возможного значения дискретной переменной. (В таком случае только три из четырех фиктивных переменных независимы друг от друга в том смысле, что, как только значения трех переменных известны, четвертая определяется автоматически. Таким образом, необходимо кодировать только три из четырех возможностей в качестве фиктивных переменных. Это также означает, что, когда все четыре возможности закодированы, общая модель не идентифицируемый при отсутствии дополнительных ограничений, таких как ограничение регуляризации. Теоретически это может вызвать проблемы, но на самом деле почти все модели логистической регрессии имеют ограничения регуляризации.)
- Переменные результата
Формально итоги Yя описываются как Распределенный по Бернулли данные, где каждый результат определяется ненаблюдаемой вероятностью пя это специфично для конкретного результата, но связано с независимыми переменными. Это может быть выражено в любой из следующих эквивалентных форм:
![{ displaystyle { begin {align} Y_ {i} mid x_ {1, i}, ldots, x_ {m, i} & sim operatorname {Bernoulli} (p_ {i}) имя оператора { mathcal {E}} [Y_ {i} mid x_ {1, i}, ldots, x_ {m, i}] & = p_ {i} Pr (Y_ {i} = y mid x_ {1, i}, ldots, x_ {m, i}) & = { begin {cases} p_ {i} & { text {if}} y = 1 1-p_ {i} & { text {if}} y = 0 end {cases}} Pr (Y_ {i} = y mid x_ {1, i}, ldots, x_ {m, i}) & = p_ {i } ^ {y} (1-p_ {i}) ^ {(1-y)} конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/60a58e896d8e9edcbf146709ae5be055e2a1a838)
Значения этих четырех строк:
- Первая строка выражает распределение вероятностей каждого Yя: При условии независимых переменных, следует Распределение Бернулли с параметрами пя, вероятность исхода 1 для испытания я. Как отмечалось выше, каждое отдельное испытание имеет собственную вероятность успеха, так же как каждое испытание имеет свои собственные объясняющие переменные. Вероятность успеха пя не наблюдается, только результат отдельного испытания Бернулли с использованием этой вероятности.
- Вторая строка выражает тот факт, что ожидаемое значение каждого Yя равна вероятности успеха пя, что является общим свойством распределения Бернулли. Другими словами, если мы проведем большое количество испытаний Бернулли с одинаковой вероятностью успеха пя, затем возьмите среднее значение для всех результатов 1 и 0, тогда результат будет близок к пя. Это связано с тем, что вычисление среднего таким образом просто вычисляет долю увиденных успехов, которые, как мы ожидаем, сойдутся с основной вероятностью успеха.
- В третьей строке записывается функция массы вероятности распределения Бернулли, определяя вероятность увидеть каждый из двух возможных результатов.
- Четвертая строка - это еще один способ записи функции массы вероятности, который позволяет избежать написания отдельных случаев и более удобен для определенных типов вычислений. Это опирается на то, что Yя может принимать только значение 0 или 1. В каждом случае один из показателей будет равен 1, «выбирая» значение под ним, а другой - 0, «отменяя» значение под ним. Следовательно, результат либо пя или 1 -пя, как в предыдущей строке.
- Линейная функция предиктора
Основная идея логистической регрессии заключается в использовании механизма, уже разработанного для линейная регрессия путем моделирования вероятности пя используя функция линейного предиктора, т.е. линейная комбинация объясняющих переменных и набора коэффициенты регрессии которые относятся к рассматриваемой модели, но одинаковы для всех испытаний. Функция линейного предиктора для конкретной точки данных я записывается как:


куда находятся коэффициенты регрессии указывающий на относительный эффект конкретной объясняющей переменной на результат.

Модель обычно принимают в более компактном виде:
- Коэффициенты регрессии β0, β1, ..., βм сгруппированы в один вектор β размера м + 1.
- Для каждой точки данных я, дополнительная объяснительная псевдо-переменная Икс0,я добавляется с фиксированным значением 1, соответствующим перехватить коэффициент β0.
- Результирующие независимые переменные Икс0,я, Икс1,я, ..., Иксм, я затем группируются в один вектор Икся размера м + 1.
Это позволяет записать функцию линейного предсказания следующим образом:

используя обозначения для скалярное произведение между двумя векторами.
Как обобщенная линейная модель
Конкретная модель, используемая логистической регрессией, которая отличает ее от стандартной линейная регрессия и из других видов регрессивный анализ используется для двоичный исходы - это способ, которым вероятность определенного результата связана с функцией линейного предиктора:
![{ displaystyle operatorname {logit} ( operatorname { mathcal {E}} [Y_ {i} mid x_ {1, i}, ldots, x_ {m, i}]) = operatorname {logit} ( p_ {i}) = ln left ({ frac {p_ {i}} {1-p_ {i}}} right) = beta _ {0} + beta _ {1} x_ {1, i} + cdots + beta _ {m} x_ {m, i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2389d119a0c95c1f52b98396ac9762de04067bdd)
Написано с использованием более компактных обозначений, описанных выше, это:
![{ displaystyle operatorname {logit} ( operatorname { mathcal {E}} [Y_ {i} mid mathbf {X} _ {i}]) = operatorname {logit} (p_ {i}) = ln left ({ frac {p_ {i}} {1-p_ {i}}} right) = { boldsymbol { beta}} cdot mathbf {X} _ {i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66290b1bc5ddfd2fc7fc2971372a79ba65e28f89)
Эта формулировка выражает логистическую регрессию как тип обобщенная линейная модель, который прогнозирует переменные с различными типами распределения вероятностей путем подгонки линейной функции-предиктора указанной выше формы к некоторому произвольному преобразованию ожидаемого значения переменной.
Интуиция для преобразования с использованием функции логита (натуральный логарифм шансов) объяснялась выше. Он также имеет практический эффект преобразования вероятности (которая ограничена между 0 и 1) в переменную, которая находится в диапазоне - тем самым согласовывая потенциальный диапазон функции линейного прогнозирования в правой части уравнения.

Обратите внимание, что обе вероятности пя а коэффициенты регрессии не наблюдаются, и средства их определения не являются частью самой модели. Обычно они определяются какой-либо процедурой оптимизации, например оценка максимального правдоподобия, который находит значения, которые наилучшим образом соответствуют наблюдаемым данным (т. е. дают наиболее точные прогнозы для уже наблюдаемых данных), обычно с учетом регуляризация условия, которые стремятся исключить маловероятные значения, например чрезвычайно большие значения для любого из коэффициентов регрессии. Использование условия регуляризации эквивалентно выполнению максимум апостериори (MAP) оценка, расширение максимального правдоподобия. (Регуляризация чаще всего выполняется с помощью квадрат регуляризующей функции, что эквивалентно установке нулевого среднего Гауссовский предварительное распространение на коэффициенты, но возможны и другие регуляризаторы.) Независимо от того, используется ли регуляризация, обычно невозможно найти решение в замкнутой форме; вместо этого необходимо использовать итеративный численный метод, например методом наименьших квадратов с повторным взвешиванием (IRLS) или, что чаще в наши дни, квазиньютоновский метод такой как L-BFGS метод.[38]
Интерпретация βj оценки параметров как аддитивный эффект на журнал шансы для изменения единицы в j объясняющая переменная. В случае дихотомической объясняющей переменной, например, пол это оценка шансов получить результат, скажем, для мужчин по сравнению с женщинами.

Эквивалентная формула использует обратную функцию логита, которая является логистическая функция, то есть:
![{ displaystyle operatorname { mathcal {E}} [Y_ {i} mid mathbf {X} _ {i}] = p_ {i} = operatorname {logit} ^ {- 1} ({ boldsymbol { beta}} cdot mathbf {X} _ {i}) = { frac {1} {1 + e ^ {- { boldsymbol { beta}} cdot mathbf {X} _ {i}} }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74c2849bc48454b0a177375d2c69c557ffd2836d)
Формулу также можно записать в виде распределение вероятностей (в частности, используя функция массы вероятности ):

Как модель со скрытыми переменными
Вышеупомянутая модель имеет эквивалентную формулировку: модель со скрытыми переменными. Эта формулировка распространена в теории дискретный выбор моделей и упрощает расширение до некоторых более сложных моделей с множественными коррелированными вариантами, а также сравнение логистической регрессии с тесно связанными пробит модель.
Представьте себе, что для каждого испытания ясуществует непрерывный скрытая переменная Yя* (т.е. ненаблюдаемый случайная переменная ), который распределяется следующим образом:

куда

т.е. скрытая переменная может быть записана непосредственно в терминах функции линейного предсказания и аддитивного случайного переменная ошибки который распространяется согласно стандарту логистическая дистрибуция.
потом Yя можно рассматривать как индикатор того, является ли эта скрытая переменная положительной:

Выбор моделирования переменной ошибки специально со стандартным логистическим распределением, а не с общим логистическим распределением с произвольными значениями местоположения и масштаба, кажется ограничительным, но на самом деле это не так. Следует иметь в виду, что мы можем сами выбирать коэффициенты регрессии и очень часто можем использовать их для компенсации изменений параметров распределения переменной ошибки. Например, распределение переменных логистической ошибки с ненулевым параметром местоположения μ (который устанавливает среднее значение) эквивалентно распределению с нулевым параметром местоположения, где μ был добавлен к коэффициенту перехвата. Обе ситуации дают одинаковое значение для Yя* независимо от настроек объясняющих переменных. Аналогично, произвольный масштабный параметр s эквивалентно установке параметра масштаба на 1 и последующему делению всех коэффициентов регрессии на s. В последнем случае результирующее значение Yя* будет меньше в раз s чем в первом случае, для всех наборов объясняющих переменных - но, что критически важно, он всегда будет оставаться по ту же сторону от 0 и, следовательно, приведет к тому же Yя выбор.
(Обратите внимание, что это предсказывает, что несоответствие параметра масштаба не может быть перенесено на более сложные модели, где доступно более двух вариантов.)
Оказывается, эта формулировка в точности эквивалентна предыдущей, сформулированной в терминах обобщенная линейная модель и без каких-либо скрытые переменные. Это можно показать следующим образом, используя тот факт, что кумулятивная функция распределения (CDF) стандарта логистическая дистрибуция это логистическая функция, что является обратным функция logit, т.е.

Потом:
![{ Displaystyle { begin {align} Pr (Y_ {i} = 1 mid mathbf {X} _ {i}) & = Pr (Y_ {i} ^ { ast}> 0 mid mathbf {X} _ {i}) [5pt] & = Pr ({ boldsymbol { beta}} cdot mathbf {X} _ {i} + varepsilon> 0) [5pt] & = Pr ( varepsilon> - { boldsymbol { beta}} cdot mathbf {X} _ {i}) [5pt] & = Pr ( varepsilon <{ boldsymbol { beta}} cdot mathbf {X} _ {i}) && { text {(поскольку логистическое распределение является симметричным)}} [5pt] & = operatorname {logit} ^ {- 1} ({ boldsymbol { beta} } cdot mathbf {X} _ {i}) & [5pt] & = p_ {i} && { text {(см. выше)}} end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d9f767289fb1baf367d01371bafd39857ac05c3)
Эта формулировка - стандартная в дискретный выбор модели - проясняет взаимосвязь между логистической регрессией («логит-модель») и пробит модель, который использует переменную ошибки, распределенную согласно стандарту нормальное распределение вместо стандартной логистической дистрибуции. Как логистическое, так и нормальное распределения симметричны базовой унимодальной форме «колоколообразной кривой». Единственное отличие состоит в том, что логистическая дистрибуция несколько более тяжелые хвосты, что означает, что он менее чувствителен к удаленным данным (и, следовательно, несколько больше крепкий для моделирования неверных спецификаций или ошибочных данных).
Двусторонняя модель со скрытыми переменными
Еще одна формулировка использует две отдельные скрытые переменные:

куда

куда Электромобиль1(0,1) - стандартный тип-1 распределение экстремальных значений: т.е.

потом

Эта модель имеет отдельную скрытую переменную и отдельный набор коэффициентов регрессии для каждого возможного результата зависимой переменной. Причина такого разделения заключается в том, что оно позволяет легко расширить логистическую регрессию на многоцелевые категориальные переменные, как в полиномиальный логит модель. В такой модели естественно моделировать каждый возможный результат, используя другой набор коэффициентов регрессии. Также можно мотивировать каждую из отдельных скрытых переменных в качестве теоретической полезность связанных с принятием соответствующего выбора, и, таким образом, мотивируют логистическую регрессию с точки зрения теория полезности. (С точки зрения теории полезности рациональный субъект всегда выбирает вариант с наибольшей связанной полезностью.) Это подход, используемый экономистами при формулировании дискретный выбор models, потому что он обеспечивает теоретически прочную основу и облегчает интуитивное понимание модели, что, в свою очередь, упрощает рассмотрение различных видов расширений. (См. Пример ниже.)
Выбор типа-1 распределение экстремальных значений кажется довольно произвольным, но он заставляет математику работать, и его использование может быть оправдано с помощью теория рационального выбора.
Оказывается, эта модель эквивалентна предыдущей модели, хотя это кажется неочевидным, поскольку теперь существует два набора коэффициентов регрессии и переменных ошибок, а переменные ошибок имеют другое распределение. Фактически, эта модель непосредственно сводится к предыдущей со следующими заменами:


Интуиция для этого исходит из того факта, что, поскольку мы выбираем на основе максимум двух значений, имеет значение только их разница, а не точные значения - и это эффективно удаляет одно степень свободы. Другой важный факт заключается в том, что разница двух переменных с распределением экстремальных значений типа 1 - это логистическое распределение, т.е. Мы можем продемонстрировать эквивалент следующим образом:

![{ displaystyle { begin {align} Pr (Y_ {i} = 1 mid mathbf {X} _ {i}) = {} & Pr left (Y_ {i} ^ {1 ast}> Y_ {i} ^ {0 ast} mid mathbf {X} _ {i} right) & [5pt] = {} & Pr left (Y_ {i} ^ {1 ast} - Y_ {i} ^ {0 ast}> 0 mid mathbf {X} _ {i} right) & [5pt] = {} & Pr left ({ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i} + varepsilon _ {1} - left ({ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i} + varepsilon _ {0} right)> 0 right) & [5pt] = {} & Pr left (({ boldsymbol { beta}} _ {1} cdot mathbf {X} _ { i} - { boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}) + ( varepsilon _ {1} - varepsilon _ {0})> 0 right) & [5pt] = {} & Pr (({ boldsymbol { beta}} _ {1} - { boldsymbol { beta}} _ {0}) cdot mathbf {X} _ {i} + ( varepsilon _ {1} - varepsilon _ {0})> 0) & [5pt] = {} & Pr (({ boldsymbol { beta}} _ {1} - { boldsymbol { beta}} _ {0}) cdot mathbf {X} _ {i} + varepsilon> 0) && { text {(заменитель}} varepsilon { text {как указано выше)}} [5pt] = {} & Pr ({ boldsymbol { beta}} cdot mathbf {X} _ {i} + varepsilon> 0) && { text {(replace}} { boldsymbol { beta}} { text {как указано выше)}} [5pt] = { } & Pr ( varepsilon> - { boldsymbol { beta}} cdot mathbf {X} _ {i}) && { text {(теперь, как в модели выше)}} [5pt] = {} & Pr ( varepsilon <{ boldsymbol { beta}} cdot mathbf {X} _ {i}) & [5pt] = {} & operatorname {logit} ^ {- 1} ( { boldsymbol { beta}} cdot mathbf {X} _ {i}) [5pt] = {} & p_ {i} end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be3b57ca6773ef745cdfd82367611e9394215f9e)
Пример
В качестве примера рассмотрим выборы на уровне провинции, где выбор делается между правоцентристской партией, левоцентристской партией и сепаратистской партией (например, Parti Québécois, который хочет Квебек отделиться от Канада ). Затем мы использовали бы три скрытые переменные, по одной для каждого выбора. Тогда в соответствии с теория полезности, тогда мы можем интерпретировать скрытые переменные как выражающие полезность это результат каждого выбора. Мы также можем интерпретировать коэффициенты регрессии как показывающие силу, которую связанный фактор (т. Е. Объясняющая переменная) имеет в содействии полезности, или, точнее, количество, на которое изменение единицы в объясняющей переменной изменяет полезность данного выбора. Избиратель может ожидать, что правоцентристская партия снизит налоги, особенно для богатых. Это не дало бы людям с низким доходом никакой выгоды, то есть никаких изменений в полезности (поскольку они обычно не платят налоги); принесет умеренную выгоду (то есть несколько больше денег или умеренное повышение полезности) для людей среднего уровня; принесет значительные выгоды людям с высокими доходами. С другой стороны, можно ожидать, что левоцентристская партия повысит налоги и компенсирует их повышением благосостояния и другой помощью для нижних и средних классов. Это принесет значительную положительную пользу людям с низкими доходами, возможно, слабую пользу для людей со средним доходом и значительную отрицательную выгоду для людей с высокими доходами. Наконец, сепаратистская партия не будет предпринимать никаких прямых действий в отношении экономики, а просто отделится. Избиратель с низким или средним доходом может в основном не ожидать от этого явной выгоды или убытка от полезности, но избиратель с высоким доходом может ожидать отрицательной полезности, поскольку он / она, вероятно, будет владеть компаниями, которым будет труднее вести бизнес. такая среда и, вероятно, потеряете деньги.
Эти интуиции можно выразить следующим образом:
| Центр-право | В центре слева | Сецессионист | |
|---|---|---|---|
| Высокий доход | сильный + | сильный - | сильный - |
| Средний доход | умеренный + | слабый + | никто |
| Низкий уровень дохода | никто | сильный + | никто |
Это ясно показывает, что
- Для каждого выбора должны существовать отдельные наборы коэффициентов регрессии. Если сформулировать это с точки зрения полезности, это очень легко увидеть. Разные варианты по-разному влияют на чистую полезность; кроме того, эффекты различаются сложным образом, что зависит от характеристик каждого человека, поэтому должны быть отдельные наборы коэффициентов для каждой характеристики, а не просто одна дополнительная характеристика для каждого выбора.
- Несмотря на то, что доход является непрерывной переменной, его влияние на полезность слишком сложно, чтобы его можно было рассматривать как единственную переменную. Либо его необходимо напрямую разделить на диапазоны, либо нужно добавить более высокие степени дохода, чтобы полиномиальная регрессия по доходу.
Как "лог-линейная" модель
Еще одна формулировка сочетает в себе формулировку с двусторонними латентными переменными, указанную выше, с исходной формулировкой выше, без скрытых переменных, и в процессе обеспечивает ссылку на одну из стандартных формулировок полиномиальный логит.
Здесь вместо того, чтобы писать логит вероятностей пя В качестве линейного предсказателя мы разделяем линейный предсказатель на два, по одному для каждого из двух результатов:

Обратите внимание, что были введены два отдельных набора коэффициентов регрессии, как и в модели двусторонних скрытых переменных, и два уравнения представляют собой форму, которая записывает логарифм связанной вероятности в качестве линейного предиктора с дополнительным членом в конце. Этот термин, как выясняется, служит нормализующий коэффициент обеспечение того, чтобы результат был распределением. Это можно увидеть, возведя в степень обе стороны:

![{ Displaystyle { begin {align} Pr (Y_ {i} = 0) & = { frac {1} {Z}} e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} [5pt] Pr (Y_ {i} = 1) & = { frac {1} {Z}} e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}} конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e1e2a04fd15f2e5617c0606a7644fe719823960)
В таком виде ясно, что цель Z гарантировать, что полученное распределение по Yя на самом деле распределение вероятностей, т.е. сумма равна 1. Это означает, что Z представляет собой просто сумму всех ненормированных вероятностей, и путем деления каждой вероятности на Z, вероятности становятся "нормализованный ". То есть:

и результирующие уравнения
![{ displaystyle { begin {align} Pr (Y_ {i} = 0) & = { frac {e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i }}} {e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} + e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}}}} [5pt] Pr (Y_ {i} = 1) & = { frac {e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}}} {e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} + e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}}}}. End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1fa489d73be139142872ddccccecd567635525d5)
Или вообще:

Это ясно показывает, как обобщить эту формулировку более чем на два результата, как в полиномиальный логит Обратите внимание, что эта общая формулировка в точности функция softmax как в

Чтобы доказать, что это эквивалентно предыдущей модели, обратите внимание, что указанная выше модель является завышенной, в том числе и не может быть отдельно указан: скорее поэтому знание одного автоматически определяет другое. В результате модель неидентифицируемый, в нескольких комбинациях β0 и β1 даст одинаковые вероятности для всех возможных объясняющих переменных. Фактически, можно видеть, что добавление любого постоянного вектора к ним обоим даст одинаковые вероятности:



![{ Displaystyle { begin {align} Pr (Y_ {i} = 1) & = { frac {e ^ {({ boldsymbol { beta}} _ {1} + mathbf {C}) cdot mathbf {X} _ {i}}} {e ^ {({ boldsymbol { beta}} _ {0} + mathbf {C}) cdot mathbf {X} _ {i}} + e ^ {({ boldsymbol { beta}} _ {1} + mathbf {C}) cdot mathbf {X} _ {i}}}} [5pt] & = { frac {e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}} e ^ { mathbf {C} cdot mathbf {X} _ {i}}} {e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} e ^ { mathbf {C} cdot mathbf {X} _ {i}} + e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}} e ^ { mathbf {C} cdot mathbf {X} _ {i}}}} [5pt] & = { frac {e ^ { mathbf {C} cdot mathbf {X} _ {i}} e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}} } {e ^ { mathbf {C} cdot mathbf {X} _ {i}} (e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} + e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}})}} [5pt] & = { frac {e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}}} {e ^ {{ boldsymbol { beta}} _ {0} cdot mathbf {X} _ {i}} + e ^ {{ boldsymbol { beta}} _ {1} cdot mathbf {X} _ {i}}}}. end {выравнивается}} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/4f545a36890435f35e006242acda552c8f62dcd0)
В результате мы можем упростить ситуацию и восстановить идентифицируемость, выбрав произвольное значение для одного из двух векторов. Мы выбираем установить Потом,


и так

что показывает, что эта формулировка действительно эквивалентна предыдущей формулировке. (Как и в формулировке двусторонней скрытой переменной, любые настройки, даст эквивалентные результаты.)
Обратите внимание, что большинство методов лечения полиномиальный логит Модель начинается либо с расширения представленной здесь «лог-линейной» формулировки, либо с формулировки двусторонней скрытой переменной, представленной выше, поскольку обе четко показывают способ, которым модель может быть расширена для многосторонних результатов. В общем, представление со скрытыми переменными чаще встречается в эконометрика и политическая наука, куда дискретный выбор модели и теория полезности царствовать, в то время как "лог-линейная" формулировка здесь более распространена в Информатика, например машинное обучение и обработка естественного языка.
Как однослойный перцептрон
Модель имеет эквивалентную формулировку

Эта функциональная форма обычно называется однослойной. перцептрон или однослойный искусственная нейронная сеть. Однослойная нейронная сеть вычисляет непрерывный вывод вместо ступенчатая функция. Производная от пя относительно Икс = (Икс1, ..., Иксk) вычисляется по общей форме:

куда ж(Икс) является аналитическая функция в Икс. При таком выборе однослойная нейронная сеть идентична модели логистической регрессии. Эта функция имеет непрерывную производную, что позволяет использовать ее в обратное распространение. Эта функция также предпочтительна, потому что ее производная легко вычисляется:

С точки зрения биномиальных данных
Тесно связанная модель предполагает, что каждый я связана не с одним судом Бернулли, а с пя независимые одинаково распределенные испытания, где наблюдение Yя - количество наблюдаемых успехов (сумма отдельных случайных величин, распределенных по Бернулли), и, следовательно, следует биномиальное распределение:

Примером такого распределения является доля семян (пя), которые прорастают после пя посажены.
С точки зрения ожидаемые значения, эта модель выражается следующим образом:
![{ displaystyle p_ {i} = operatorname { mathcal {E}} left [ left. { frac {Y_ {i}} {n_ {i}}} , right | , mathbf {X } _{Я прав],,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0123cbc81b998479d4519f00a89ba3d5ba1bfcc5)
так что
![{ displaystyle operatorname {logit} left ( operatorname { mathcal {E}} left [ left. { frac {Y_ {i}} {n_ {i}}} , right | , mathbf {X} _ {i} right] right) = operatorname {logit} (p_ {i}) = ln left ({ frac {p_ {i}} {1-p_ {i}}} right) = { boldsymbol { beta}} cdot mathbf {X} _ {i} ,,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdb8db87748853ad7609116b81d41ab7ecaad708)
Или эквивалентно:

Эта модель может быть подобрана с использованием тех же методов, что и описанная выше более базовая модель.
Байесовский



В Байесовская статистика контекст предыдущие распределения обычно помещаются в коэффициенты регрессии, обычно в форме Гауссовы распределения. Здесь нет сопряженный предшествующий из функция правдоподобия в логистической регрессии. Когда байесовский вывод был выполнен аналитически, это сделало апостериорное распределение трудно рассчитать, за исключением очень малых размеров. Однако теперь автоматическое программное обеспечение, такое как OpenBUGS, JAGS, PyMC3 или же Стэн позволяет вычислить эти апостериорные данные с помощью моделирования, поэтому отсутствие сопряженности не является проблемой. Однако, когда размер выборки или количество параметров велико, полное байесовское моделирование может быть медленным, и люди часто используют приближенные методы, такие как вариационные байесовские методы и распространение ожидания.
История
Подробная история логистической регрессии приведена в Крамер (2002). Логистическая функция была разработана как модель рост населения и назван "логистическим" Пьер Франсуа Верхюльст в 1830-х и 1840-х годах под руководством Адольф Кетле; видеть Логистическая функция § История для подробностей.[39] В своей самой ранней статье (1838) Ферхюльст не уточнил, как он подгоняет кривые к данным.[40][41] В своей более подробной статье (1845) Ферхюльст определил три параметра модели, заставив кривую проходить через три наблюдаемые точки, что дало плохие прогнозы.[42][43]
Логистическая функция была независимо разработана в химии как модель автокатализ (Вильгельм Оствальд, 1883).[44] Автокаталитическая реакция - это реакция, в которой один из продуктов сам по себе катализатор для той же реакции, при фиксированной подаче одного из реагентов. Это естественным образом приводит к логистическому уравнению по той же причине, что и рост населения: реакция является самоусиливающейся, но ограниченной.
Логистическая функция была независимо заново открыта как модель роста населения в 1920 г. Раймонд Перл и Лоуэлл Рид, опубликовано как Жемчуг и тростник (1920), что привело к его использованию в современной статистике. Первоначально они не знали о работе Ферхюльста и, вероятно, узнали о ней от Л. Густав дю Паскье, но они не поверили ему и не приняли его терминологию.[45] Признание приоритета Verhulst и возрождение термина «логистика» Удный Йоль в 1925 году и с тех пор отслеживается.[46] Перл и Рид сначала применили модель к населению Соединенных Штатов, а также сначала подогнали кривую, проведя ее через три точки; как и в случае с Verhulst, это снова дало плохие результаты.[47]
В 1930-е гг. пробит модель был разработан и систематизирован Честер Иттнер Блисс, который ввел термин "пробит" в Блаженство (1934), и по Джон Гэддум в Гаддум (1933), и модель соответствовала оценка максимального правдоподобия к Рональд А. Фишер в Фишер (1935), как дополнение к работе Блисс. Модель пробит в основном использовалась в биоанализ, и ему предшествовали более ранние работы, датированные 1860 годом; видеть Пробит модель § История. Пробит-модель повлияла на последующее развитие логит-модели, и эти модели конкурировали друг с другом.[48]
Логистическая модель, вероятно, впервые была использована в качестве альтернативы пробит-модели в биотестах. Эдвин Бидвелл Уилсон и его ученик Джейн Вустер в Уилсон и Вустер (1943).[49] Однако разработка логистической модели как общей альтернативы пробит-модели была в основном связана с работой Джозеф Берксон на протяжении многих десятилетий, начиная с Берксон (1944), где он придумал «логит» по аналогии с «пробит», и продолжая Берксон (1951) и последующие годы.[50] Первоначально логит-модель была отклонена как уступающая пробит-модели, но «постепенно достигла равенства с логит-моделью»,[51] особенно между 1960 и 1970 годами. К 1970 году логит-модель достигла паритета с пробит-моделью, используемой в статистических журналах, и впоследствии превзошла ее. Эта относительная популярность объяснялась принятием логита за пределами биотеста, а не вытеснением пробита в биотесте, и его неформальным использованием на практике; Популярность логита объясняется вычислительной простотой, математическими свойствами и универсальностью модели логита, что позволяет использовать ее в различных областях.[52]
За это время были внесены различные усовершенствования, в частности Дэвид Кокс, как в Кокс (1958).[2]
Полиномиальная логит-модель была введена независимо в Кокс (1966) и Тиль (1969), что значительно увеличило сферу применения и популярность модели logit.[53] В 1973 г. Дэниел Макфадден связал полиномиальный логит с теорией дискретный выбор, конкретно Аксиома выбора Люси, показывая, что полиномиальный логит следует из предположения независимость от нерелевантных альтернатив и интерпретация вероятностей альтернатив как относительных предпочтений;[54] это дало теоретическую основу для логистической регрессии.[53]
Расширения
Есть большое количество расширений:
- Полиномиальная логистическая регрессия (или же полиномиальный логит) обрабатывает случай многоходового категоричный зависимая переменная (с неупорядоченными значениями, также называемая «классификацией»). Обратите внимание, что общий случай наличия зависимых переменных с более чем двумя значениями называется политомическая регрессия.
- Упорядоченная логистическая регрессия (или же заказанный логит) ручки порядковый зависимые переменные (упорядоченные значения).
- Смешанный логит - это расширение полиномиального логита, которое позволяет устанавливать корреляции между вариантами выбора зависимой переменной.
- Расширением логистической модели до наборов взаимозависимых переменных является условное случайное поле.
- Условная логистическая регрессия ручки совпадает или же стратифицированный данные, когда пласты небольшие. В основном он используется при анализе наблюдательные исследования.
Программного обеспечения
Наиболее статистическое программное обеспечение может выполнять бинарную логистическую регрессию.
- SPSS
- [1] для базовой логистической регрессии.
- Stata
- SAS
- ПРОЦЕДУРА ЛОГИСТИКА для базовой логистической регрессии.
- PROC CATMOD когда все переменные категоричны.
- ПРОЦЕДУРА GLIMMIX за многоуровневая модель логистическая регрессия.
- р
glmв пакете статистики (с использованием family = binomial)[55]lrmв пакет rms- Пакет GLMNET для эффективной реализации регуляризованной логистической регрессии
- lmer для логистической регрессии со смешанными эффектами
- Команда пакета Rfast
gm_logisticдля быстрых и тяжелых вычислений с крупномасштабными данными. - пакет arm для байесовской логистической регрессии
- Python
Logitв Статистические модели модуль.Логистическая регрессияв Scikit-Learn модуль.LogisticRegressorв TensorFlow модуль.- Полный пример логистической регрессии в учебнике Theano [2]
- Байесовская логистическая регрессия с предварительным ARD код, руководство
- Вариационная байесовская логистическая регрессия с предварительным ARD код , руководство
- Байесовская логистическая регрессия код, руководство
- NCSS
- Matlab
mnrfitв Инструменты статистики и машинного обучения (с "неправильным" кодом 2 вместо 0)fminunc / fmincon, fitglm, mnrfit, fitclinear, mleмогут все сделать логистическую регрессию.
- Ява (JVM )
- LibLinear
- Apache Flink
- Apache Spark
- SparkML поддерживает логистическую регрессию
- FPGA
В частности, Майкрософт Эксель пакет расширения статистики не включает его.
Смотрите также
- Логистическая функция
- Дискретный выбор
- Модель Ярроу – Тернбулла
- Ограниченная зависимая переменная
- Полиномиальная логит-модель
- Заказал логит
- Тест Хосмера – Лемешоу
- Оценка Бриера
- mlpack - содержит C ++ реализация логистической регрессии
- Выборка для местного контроля
- Дерево логистической модели
Рекомендации
- ^ Толлес, Юлиана; Мерер, Уильям Дж (2016).«Логистическая регрессия, связывающая характеристики пациентов с результатами». JAMA. 316 (5): 533–4. Дои:10.1001 / jama.2016.7653. ISSN 0098-7484. OCLC 6823603312. PMID 27483067.
- ^ а б Уокер, SH; Дункан, ДБ (1967). «Оценка вероятности события как функции нескольких независимых переменных». Биометрика. 54 (1/2): 167–178. Дои:10.2307/2333860. JSTOR 2333860.
- ^ Крамер 2002, п. 8.
- ^ Boyd, C. R .; Толсон, М. А .; Копс, В. С. (1987). «Оценка помощи при травмах: метод TRISS. Оценка травмы и оценка тяжести травмы». Журнал травм. 27 (4): 370–378. Дои:10.1097/00005373-198704000-00005. PMID 3106646.
- ^ Кологлу, М .; Elker, D .; Алтун, Х .; Сайек, И. (2001). «Валидация MPI и PIA II в двух разных группах пациентов со вторичным перитонитом». Гепатогастроэнтерология. 48 (37): 147–51. PMID 11268952.
- ^ Biondo, S .; Ramos, E .; Deiros, M .; Ragué, J.M .; De Oca, J .; Moreno, P .; Farran, L .; Джаурриета, Э. (2000). «Прогностические факторы смертности при перитоните левой толстой кишки: новая система баллов». Журнал Американского колледжа хирургов. 191 (6): 635–42. Дои:10.1016 / S1072-7515 (00) 00758-4. PMID 11129812.
- ^ Marshall, J.C .; Кук, Д. Дж .; Christou, N.V .; Бернард, Г. Р .; Sprung, C.L .; Сиббальд, В. Дж. (1995). «Оценка множественной дисфункции органов: надежный дескриптор сложного клинического исхода». Реанимационная медицина. 23 (10): 1638–52. Дои:10.1097/00003246-199510000-00007. PMID 7587228.
- ^ Le Gall, J. R .; Lemeshow, S .; Saulnier, F. (1993). «Новая упрощенная оценка острой физиологии (SAPS II) на основе многоцентрового исследования в Европе и Северной Америке». JAMA. 270 (24): 2957–63. Дои:10.1001 / jama.1993.03510240069035. PMID 8254858.
- ^ а б Дэвид А. Фридман (2009). Статистические модели: теория и практика. Издательство Кембриджского университета. п. 128.
- ^ Truett, J; Кукурузное поле, Дж; Каннел, W. (1967). «Многомерный анализ риска ишемической болезни сердца во Фрамингеме». Журнал хронических болезней. 20 (7): 511–24. Дои:10.1016/0021-9681(67)90082-3. PMID 6028270.
- ^ Харрелл, Фрэнк Э. (2001). Стратегии регрессионного моделирования (2-е изд.). Springer-Verlag. ISBN 978-0-387-95232-1.
- ^ М. Страно; Б.М. Колозимо (2006). «Логистический регрессионный анализ для экспериментального определения построения предельных диаграмм». Международный журнал станков и производства. 46 (6): 673–682. Дои:10.1016 / j.ijmachtools.2005.07.005.
- ^ Palei, S.K .; Дас, С. К. (2009). «Модель логистической регрессии для прогнозирования рисков обрушения кровли при выработках бортов и колонн в угольных шахтах: подход». Наука о безопасности. 47: 88–96. Дои:10.1016 / j.ssci.2008.01.002.
- ^ Берри, Майкл Дж. А. (1997). Методы интеллектуального анализа данных для маркетинга, продаж и поддержки клиентов. Вайли. п. 10.
- ^ а б c d е ж грамм час я j k Хосмер, Дэвид В .; Лемешоу, Стэнли (2000). Прикладная логистическая регрессия (2-е изд.). Вайли. ISBN 978-0-471-35632-5.[страница нужна ]
- ^ а б Харрелл, Фрэнк Э. (2015). Стратегии регрессионного моделирования. Серия Спрингера в статистике (2-е изд.). Нью-Йорк; Springer. Дои:10.1007/978-3-319-19425-7. ISBN 978-3-319-19424-0.
- ^ Родригес, Г. (2007). Конспект лекций по обобщенным линейным моделям. стр. Глава 3, стр. 45 - через http://data.princeton.edu/wws509/notes/.
- ^ Гарет Джеймс; Даниэла Виттен; Тревор Хасти; Роберт Тибширани (2013). Введение в статистическое обучение. Springer. п. 6.
- ^ Похар, Майя; Блас, Матея; Терк, Сандра (2004). «Сравнение логистической регрессии и линейного дискриминантного анализа: имитационное исследование». Методолошки Звездки. 1 (1).
- ^ «Как интерпретировать отношение шансов в логистической регрессии?». Институт цифровых исследований и образования.
- ^ Эверит, Брайан (1998). Кембриджский статистический словарь. Кембридж, Великобритания Нью-Йорк: Издательство Кембриджского университета. ISBN 978-0521593465.
- ^ Нг, Эндрю (2000). "Лекционные заметки CS229" (PDF). CS229 Лекционные заметки: 16–19.
- ^ Ван Смеден, М .; Де Гроот, Дж. А .; Луны, К. Г .; Коллинз, Г. С .; Альтман, Д. Г .; Eijkemans, M. J .; Рейцма, Дж. Б. (2016). «Нет обоснования для 1 переменной на 10 критериев событий для бинарного логистического регрессионного анализа». BMC Методология медицинских исследований. 16 (1): 163. Дои:10.1186 / s12874-016-0267-3. ЧВК 5122171. PMID 27881078.
- ^ Peduzzi, P; Конкато, Дж; Кемпер, Э; Холфорд, TR; Файнштейн, АР (декабрь 1996 г.). «Имитационное исследование количества событий на переменную в логистическом регрессионном анализе». Журнал клинической эпидемиологии. 49 (12): 1373–9. Дои:10.1016 / s0895-4356 (96) 00236-3. PMID 8970487.
- ^ Vittinghoff, E .; Маккаллох, К. Э. (12 января 2007 г.). «Ослабление правила десяти событий на переменную в логистической регрессии и регрессии Кокса». Американский журнал эпидемиологии. 165 (6): 710–718. Дои:10.1093 / aje / kwk052. PMID 17182981.
- ^ ван дер Плоег, Тьерд; Остин, Питер С .; Стейерберг, Юут В. (2014). «Современные методы моделирования требуют данных: имитационное исследование для прогнозирования дихотомических конечных точек». BMC Методология медицинских исследований. 14: 137. Дои:10.1186/1471-2288-14-137. ЧВК 4289553. PMID 25532820.
- ^ а б c d е ж грамм час я Менард, Скотт В. (2002). Прикладная логистическая регрессия (2-е изд.). МУДРЕЦ. ISBN 978-0-7619-2208-7.[страница нужна ]
- ^ Гурье, Кристиан; Монфор, Ален (1981). «Асимптотические свойства оценки максимального правдоподобия в дихотомических логит-моделях». Журнал эконометрики. 17 (1): 83–97. Дои:10.1016/0304-4076(81)90060-9.
- ^ Park, Byeong U .; Симар, Леопольд; Зеленюк, Валентин (2017). «Непараметрическая оценка динамических моделей дискретного выбора для данных временных рядов» (PDF). Вычислительная статистика и анализ данных. 108: 97–120. Дои:10.1016 / j.csda.2016.10.024.
- ^ Видеть например. Мерфи, Кевин П. (2012). Машинное обучение - вероятностная перспектива. MIT Press. стр. 245с. ISBN 978-0-262-01802-9.
- ^ Грин, Уильям Н. (2003). Эконометрический анализ (Пятое изд.). Прентис-Холл. ISBN 978-0-13-066189-0.
- ^ а б c d е ж грамм час я j k л м п о Коэн, Джейкоб; Коэн, Патрисия; Уэст, Стивен Дж .; Айкен, Леона С. (2002). Прикладная множественная регрессия / корреляционный анализ для поведенческих наук (3-е изд.). Рутледж. ISBN 978-0-8058-2223-6.[страница нужна ]
- ^ а б c d е Эллисон, Пол Д. «Меры соответствия для логистической регрессии» (PDF). Statistical Horizons LLC и Пенсильванский университет.
- ^ Тюрь, Вт (2009). «Коэффициенты детерминации в моделях логистической регрессии». Американский статистик: 366–372. Дои:10.1198 / вкус.2009.08210.[требуется полная цитата ]
- ^ Хосмер, Д.В. (1997). «Сравнение критериев согласия для модели логистической регрессии». Stat Med. 16 (9): 965–980. Дои:10.1002 / (sici) 1097-0258 (19970515) 16: 9 <965 :: help-sim509> 3.3.co; 2-f.
- ^ Харрелл, Фрэнк Э. (2010). Стратегии регрессионного моделирования: с приложениями к линейным моделям, логистической регрессии и анализу выживаемости. Нью-Йорк: Спрингер. ISBN 978-1-4419-2918-1.[страница нужна ]
- ^ а б https://class.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/classification.pdf слайд 16
- ^ Малуф, Роберт (2002). «Сравнение алгоритмов оценки максимального энтропийного параметра». Труды Шестой конференции по изучению естественного языка (CoNLL-2002). С. 49–55. Дои:10.3115/1118853.1118871.
- ^ Крамер 2002, стр. 3–5.
- ^ Верхюльст, Пьер-Франсуа (1838). "Notice sur la loi que la population poursuit dans son accroissement" (PDF). Соответствие Mathématique et Physique. 10: 113–121. Получено 3 декабря 2014.
- ^ Крамер 2002, п. 4, «Он не сказал, как он подогнал кривые».
- ^ Верхюльст, Пьер-Франсуа (1845). "Recherches mathématiques sur la loi d'accroissement de la Population" [Математические исследования закона увеличения роста населения]. Nouveaux Mémoires de l'Académie Royale des Sciences et Belles-Lettres de Bruxelles. 18. Получено 2013-02-18.
- ^ Крамер 2002, п. 4.
- ^ Крамер 2002, п. 7.
- ^ Крамер 2002, п. 6.
- ^ Крамер 2002, п. 6–7.
- ^ Крамер 2002, п. 5.
- ^ Крамер 2002, п. 7–9.
- ^ Крамер 2002, п. 9.
- ^ Крамер 2002, п. 8: «Насколько я понимаю, введение логистики в качестве альтернативы нормальной функции вероятности - это работа одного человека, Джозефа Берксона (1899–1982), ...»
- ^ Крамер 2002, п. 11.
- ^ Крамер 2002, п. 10–11.
- ^ а б Крамер, п. 13.
- ^ Макфадден, Дэниел (1973). «Условный логит-анализ качественного выбора поведения» (PDF). В П. Зарембке (ред.). Границы в эконометрике. Нью-Йорк: Academic Press. С. 105–142. Архивировано из оригинал (PDF) на 2018-11-27. Получено 2019-04-20.
- ^ Гельман, Андрей; Хилл, Дженнифер (2007). Анализ данных с использованием регрессии и многоуровневых / иерархических моделей. Нью-Йорк: Издательство Кембриджского университета. С. 79–108. ISBN 978-0-521-68689-1.
дальнейшее чтение
- Кокс, Дэвид Р. (1958). «Регрессионный анализ двоичных последовательностей (с обсуждением)». J R Stat Soc B. 20 (2): 215–242. JSTOR 2983890.
- Кокс, Дэвид Р. (1966). «Некоторые процедуры, связанные с логистической качественной кривой ответа». В F. N. David (1966) (ред.). Исследования по вероятности и статистике (Festschrift для Дж. Неймана). Лондон: Уайли. С. 55–71.
- Крамер, Дж. С. (2002). Истоки логистической регрессии (PDF) (Технический отчет). 119. Институт Тинбергена. С. 167–178. Дои:10.2139 / ssrn.360300.
- Опубликовано в: Крамер, Дж. С. (2004). «Ранние истоки логит-модели». Исследования по истории и философии науки Часть C: Исследования по истории и философии биологических и биомедицинских наук. 35 (4): 613–626. Дои:10.1016 / j.shpsc.2004.09.003.
- Тиль, Анри (1969). «Мультиномиальное расширение линейной логитовой модели». Международное экономическое обозрение. 10 (3): 251–59. Дои:10.2307/2525642. JSTOR 2525642.
- Уилсон, Э.; Вустер, Дж. (1943). «Определение L.D.50 и его ошибка отбора проб в биопробе». Труды Национальной академии наук Соединенных Штатов Америки. 29 (2): 79–85. Bibcode:1943ПНАС ... 29 ... 79Вт. Дои:10.1073 / пнас.29.2.79. ЧВК 1078563. PMID 16588606.
- Агрести, Алан. (2002). Категориальный анализ данных. Нью-Йорк: Wiley-Interscience. ISBN 978-0-471-36093-3.
- Амемия, Такеши (1985). «Модели качественного ответа». Продвинутая эконометрика. Оксфорд: Бэзил Блэквелл. С. 267–359. ISBN 978-0-631-13345-2.
- Балакришнан, Н. (1991). Справочник по логистической дистрибуции. Марсель Деккер, Inc. ISBN 978-0-8247-8587-1.
- Гурье, Кристиан (2000). «Простая дихотомия». Эконометрика качественных зависимых переменных. Нью-Йорк: Издательство Кембриджского университета. С. 6–37. ISBN 978-0-521-58985-7.
- Грин, Уильям Х. (2003). Эконометрический анализ, пятое издание. Прентис Холл. ISBN 978-0-13-066189-0.
- Хильбе, Джозеф М. (2009). Модели логистической регрессии. Чепмен и Холл / CRC Press. ISBN 978-1-4200-7575-5.
- Хосмер, Дэвид (2013). Прикладная логистическая регрессия. Хобокен, Нью-Джерси: Wiley. ISBN 978-0470582473.
- Хауэлл, Дэвид С. (2010). Статистические методы психологии, 7-е изд.. Бельмонт, Калифорния; Томсон Уодсворт. ISBN 978-0-495-59786-5.
- Peduzzi, P .; Дж. Конкато; Э. Кемпер; T.R. Холфорд; A.R. Файнштейн (1996). «Имитационное исследование количества событий на переменную в логистическом регрессионном анализе». Журнал клинической эпидемиологии. 49 (12): 1373–1379. Дои:10.1016 / s0895-4356 (96) 00236-3. PMID 8970487.
- Берри, Майкл Дж. А .; Линофф, Гордон (1997). Методы интеллектуального анализа данных для маркетинга, продаж и поддержки клиентов. Вайли.
внешняя ссылка
 СМИ, связанные с Логистическая регрессия в Wikimedia Commons
СМИ, связанные с Логистическая регрессия в Wikimedia Commons- Лекция по эконометрике (тема: Логит-модель) на YouTube к Марк Тома
- Учебник по логистической регрессии
- mlelr: программное обеспечение в C в учебных целях