Надежная статистика - Robust statistics
Надежная статистика находятся статистика с хорошей производительностью для данных, полученных из широкого диапазона распределения вероятностей, особенно для дистрибутивов, которые не нормальный. Крепкий статистический были разработаны методы для решения многих общих задач, таких как оценка место расположения, шкала, и параметры регрессии. Одна из мотиваций - производить Статистические методы которые не подвергаются чрезмерному влиянию выбросы. Еще одна мотивация - предоставить методы с хорошей производительностью, когда есть небольшие отклонения от параметрическое распределение. Например, надежные методы хорошо работают для смесей двух нормальные распределения с разными Стандартное отклонение; в рамках этой модели ненадежные методы, такие как t-тест плохо работают.
Вступление
Надежная статистика стремится предоставить методы, которые имитируют популярные статистические методы, но не подвержены чрезмерному влиянию выбросов или других небольших отклонений от допущения модели. В статистике классические методы оценки в значительной степени полагаются на предположения, которые на практике часто не выполняются. В частности, часто предполагается, что ошибки в данных распределены нормально, по крайней мере приблизительно, или что Центральная предельная теорема можно положиться на получение нормально распределенных оценок. К сожалению, когда в данных есть выбросы, классические оценщики часто имеют очень низкую производительность, если судить по точка разрушения и функция влияния, описано ниже.
Практический эффект проблем, обнаруженных в функции влияния, можно изучить эмпирически, исследуя выборочное распределение предлагаемых оценок под модель смеси, где смешивается небольшое количество (часто достаточно 1–5%) загрязнения. Например, можно использовать смесь 95% нормального распределения и 5% нормального распределения с тем же средним, но значительно более высоким стандартным отклонением (представляющим выбросы).
Крепкий параметрическая статистика может действовать двумя способами:
- путем разработки оценщиков таким образом, чтобы достигалось предварительно выбранное поведение функции влияния
- путем замены оценок, оптимальных в предположении нормального распределения, на оценки, которые оптимальны для других распределений или, по крайней мере, выведены для них: например, с использованием т-распределение с низкими степенями свободы (высокий эксцесс; степени свободы от 4 до 6 часто оказывались полезными на практике[нужна цитата ]) или с смесь из двух или более дистрибутивов.
Робастные оценки изучались для следующих задач:
- оценка параметры местоположения[нужна цитата ]
- оценка параметры шкалы[нужна цитата ]
- оценка коэффициенты регрессии[нужна цитата ]
- оценка состояний моделей в моделях, выраженных в пространство состояний форма, для которой стандартный метод эквивалентен Фильтр Калмана.
Определение
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Июль 2008 г.) |
Существуют различные определения «надежной статистики». Строго говоря, надежная статистика устойчива к ошибкам в результатах, вызванным отклонениями от предположений[1] (например, нормальности). Это означает, что если предположения выполняются только приблизительно, робастная оценка все равно будет разумный эффективность, и достаточно маленький предвзятость, а также будучи асимптотически несмещенный, что означает наличие смещения, стремящегося к 0, поскольку размер выборки стремится к бесконечности.
Один из наиболее важных случаев - надежность распределения.[1] Классические статистические процедуры обычно чувствительны к "долгосрочности" (например, когда распределение данных имеет более длинные хвосты, чем предполагаемое нормальное распределение). Это означает, что на них сильно повлияет наличие выбросов в данных, и получаемые ими оценки могут быть сильно искажены, если в данных есть экстремальные выбросы, по сравнению с тем, что было бы, если бы выбросы не были включены в данные. .
Напротив, более надежные оценщики, которые не так чувствительны к искажениям распределения, таким как длинноствольный характер, также устойчивы к наличию выбросов. Таким образом, в контексте надежной статистики, устойчивый к распределению и устойчивый к выбросам фактически являются синонимами.[1] Об одном взгляде на исследования надежной статистики до 2000 г. см. Портной и он (2000).
Смежная тема - это стойкая статистика, которая устойчива к воздействию экстремальных оценок.
При рассмотрении того, насколько устойчива оценка к наличию выбросов, полезно проверить, что происходит, когда резко выделяется добавлен к набору данных и проверить, что происходит, когда резко выделяется заменяет одна из существующих точек данных, а затем учесть влияние нескольких добавлений или замен.
Примеры
В иметь в виду не является надежной мерой основная тенденция. Если набор данных, например, значения {2,3,5,6,9}, то, если мы добавим к данным еще одну точку данных со значением -1000 или +1000, результирующее среднее будет сильно отличаться от среднего значения исходных данных. Точно так же, если мы заменим одно из значений точкой данных со значением -1000 или +1000, то итоговое среднее будет сильно отличаться от среднего значения исходных данных.
В медиана является надежной мерой основная тенденция. Если взять тот же набор данных {2,3,5,6,9}, то если мы добавим еще одну точку данных со значением -1000 или +1000, то медиана немного изменится, но все равно будет похожа на медиану исходных данных. Если мы заменим одно из значений точкой данных со значением -1000 или +1000, то полученная медиана все равно будет аналогична медиане исходных данных.
Описано с точки зрения точки поломки, медиана имеет точку разбивки 50%, в то время как среднее имеет точку разбивки 1 / N, где N - количество исходных точек данных (одно большое наблюдение может отбросить ее).
В среднее абсолютное отклонение и межквартильный размах надежные меры статистическая дисперсия, в то время как стандартное отклонение и классифицировать не.
Обрезанные оценщики и Победоносные оценки являются общими методами повышения надежности статистики. L-оценки представляют собой общий класс простой статистики, часто надежной, в то время как М-оценки представляют собой общий класс надежных статистических данных и в настоящее время являются предпочтительным решением, хотя их можно довольно сложно вычислить.
Пример: данные о скорости света
Гельман и др. в Bayesian Data Analysis (2004) рассмотрим набор данных, относящихся к скорость света измерения сделаны Саймон Ньюкомб. Наборы данных для этой книги можно найти через Классические наборы данных страница, а на сайте книги содержится дополнительная информация о данных.
Хотя большая часть данных выглядит более или менее нормально распределенной, есть два очевидных выброса. Эти выбросы сильно влияют на среднее значение, перетаскивая его к себе и от центра основной массы данных. Таким образом, если среднее значение предназначено для измерения местоположения центра данных, оно в некотором смысле смещается при наличии выбросов.
Кроме того, известно, что распределение среднего является асимптотически нормальным из-за центральной предельной теоремы. Однако выбросы могут сделать распределение среднего ненормальным даже для довольно больших наборов данных. Помимо этой ненормальности, среднее значение также неэффективный при наличии выбросов и менее изменчивые меры местоположения доступны.
Оценка местоположения
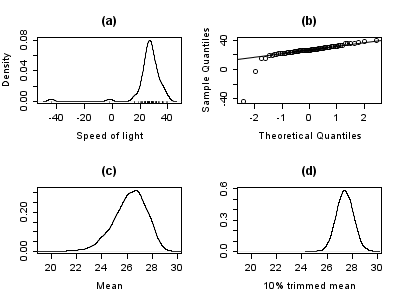
График ниже показывает график плотности данных скорости света вместе с графиком коврика (панель (а)). Также показан нормальный Q – Q график (панель (б)). На этих графиках хорошо видны выбросы.
Панели (c) и (d) графика показывают бутстрап-распределение среднего (c) и 10% усеченное среднее (г). Усеченное среднее - это простая надежная оценка местоположения, которая удаляет определенный процент наблюдений (здесь 10%). с каждого конца данных, затем вычисляет среднее значение обычным способом. Анализ проводился в р и 10 000 бутстрап образцы были использованы для каждого из необработанных и обрезанных средних значений.
Очевидно, что распределение среднего намного шире, чем у 10% усеченного среднего (графики имеют тот же масштаб). Кроме того, в то время как распределение усеченного среднего кажется близким к нормальному, распределение необработанного среднего сильно смещено влево. Итак, в этой выборке из 66 наблюдений только 2 выброса приводят к тому, что центральная предельная теорема неприменима.
Надежные статистические методы, простым примером которых является усеченное среднее, стремятся превзойти классические статистические методы при наличии выбросов или, в более общем плане, когда лежащие в основе параметрические допущения не совсем верны.
Хотя усеченное среднее хорошо работает по сравнению со средним в этом примере, доступны более надежные оценки. Фактически, среднее, медианное и усеченное среднее - это частные случаи М-оценки. Подробности представлены в разделах ниже.
Оценка масштаба
Выбросы в данных о скорости света имеют больше, чем просто отрицательное влияние на среднее значение; обычная оценка масштаба - это стандартное отклонение, и на эту величину еще более сильно влияют выбросы, потому что квадраты отклонений от среднего входят в расчет, поэтому влияние выбросов усугубляется.
На графиках ниже показаны бутстрап-распределения стандартного отклонения, среднее абсолютное отклонение (MAD) и Rousseeuw – Croux (Qn) оценка масштаба.[2] Графики основаны на 10000 бутстрап-выборок для каждой оценки, с некоторым гауссовским шумом, добавленным к передискретизированным данным (сглаженный бутстрап ). На панели (а) показано распределение стандартного отклонения, (b) MAD и (c) Qn.

Распределение стандартного отклонения неустойчиво и широко из-за выбросов. MAD ведет себя лучше, а Qn немного более эффективен, чем MAD. Этот простой пример демонстрирует, что при наличии выбросов стандартное отклонение нельзя рекомендовать в качестве оценки масштаба.
Ручной скрининг выбросов
Традиционно статистики вручную просматривали данные для выбросы, и удалите их, обычно проверяя источник данных, чтобы убедиться, что выбросы были записаны ошибочно. В самом деле, в приведенном выше примере скорости света легко увидеть и удалить два выброса, прежде чем продолжить дальнейший анализ. Однако в наше время наборы данных часто состоят из большого количества переменных, измеряемых на большом количестве экспериментальных установок. Поэтому ручной отбор выбросов часто нецелесообразен.
Выбросы часто могут взаимодействовать таким образом, что маскируют друг друга. В качестве простого примера рассмотрим небольшой одномерный набор данных, содержащий один скромный и один большой выброс. Расчетное стандартное отклонение будет сильно завышено из-за большого выброса. В результате скромный выброс выглядит относительно нормально. Как только большой выброс удаляется, расчетное стандартное отклонение уменьшается, и теперь скромный выброс выглядит необычно.
Эта проблема маскирования усугубляется по мере увеличения сложности данных. Например, в регресс проблемы, диагностические графики используются для выявления выбросов. Однако обычно после удаления нескольких выбросов другие становятся видимыми. Проблема еще хуже в более высоких измерениях.
Надежные методы обеспечивают автоматические способы обнаружения, уменьшения (или удаления) и отметки выбросов, что в значительной степени устраняет необходимость в ручной проверке. Следует соблюдать осторожность; исходные данные, показывающие озоновая дыра впервые появляется Антарктида были отклонены как выбросы при проверке без участия человека.[3]
Разнообразие приложений
Хотя в этой статье рассматриваются общие принципы одномерных статистических методов, робастные методы также существуют для задач регрессии, обобщенных линейных моделей и оценки параметров различных распределений.
Меры устойчивости
Основные инструменты, используемые для описания и измерения устойчивости: точка разрушения, то функция влияния и кривая чувствительности.
Точка разрушения
Интуитивно понятно, что точка отказа оценщик - это доля неверных наблюдений (например, произвольно больших наблюдений), которую может обработать оценщик, прежде чем дать неверный (например, произвольно большой) результат. Например, учитывая независимые случайные величины и соответствующие реализации , мы можем использовать оценить среднее. Такая оценка имеет точку разбивки 0, потому что мы можем сделать произвольно большой, просто изменив любой из .





Чем выше точка разбивки оценщика, тем она надежнее. Интуитивно мы можем понять, что точка разбивки не может превышать 50%, потому что, если более половины наблюдений загрязнены, невозможно отличить основное распределение от загрязняющего распределения. Руссей и Лерой (1986). Таким образом, максимальная точка разбивки составляет 0,5, и есть средства оценки, которые достигают такой точки разбивки. Например, медиана имеет точку разбивки 0,5. Усеченное среднее значение X% имеет точку пробоя X% для выбранного уровня X. Хубер (1981) и Маронна, Мартин и Йохай (2006) содержать более подробную информацию. Уровень и точки пропадания мощности испытаний исследуются в Он, Симпсон и Портной (1990).
Статистические данные с высокими пунктами разбивки иногда называют стойкая статистика.[4]
Пример: данные о скорости света
В примере со скоростью света удаление двух самых низких наблюдений приводит к изменению среднего значения с 26,2 до 27,75, т.е. на 1,55. Оценка масштаба, полученная методом Qn, составляет 6,3. Мы можем разделить это значение на квадратный корень из размера выборки, чтобы получить надежную стандартную ошибку, и мы находим, что эта величина составляет 0,78. Таким образом, изменение среднего в результате удаления двух выбросы примерно вдвое больше надежной стандартной ошибки.
Усеченное на 10% среднее значение скорости света составляет 27,43. Удаление двух самых низких наблюдений и пересчет дает 27,67. Ясно, что усеченное среднее меньше подвержено влиянию выбросов и имеет более высокую точку разбивки.
Если мы заменим самое низкое наблюдение, −44, на −1000, среднее значение станет 11,73, тогда как усеченное на 10% среднее значение останется 27,43. Во многих областях прикладной статистики данные обычно подвергаются логарифмическому преобразованию, чтобы сделать их почти симметричными. Очень маленькие значения становятся большими отрицательными при логарифмическом преобразовании, а нули становятся отрицательно бесконечными. Поэтому этот пример представляет практический интерес.
Функция эмпирического влияния
Эта статья может быть слишком техническим для большинства читателей, чтобы понять. Пожалуйста помогите улучшить это к сделать понятным для неспециалистов, не снимая технических деталей. (Июнь 2010 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
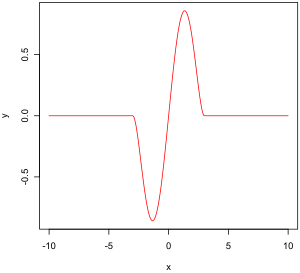
Функция эмпирического влияния - это мера зависимости оценки от значения одной из точек в выборке. Это безмодельная мера в том смысле, что она просто полагается на повторное вычисление оценки с другой выборкой. Справа - двухвесовая функция Тьюки, которая, как мы увидим позже, является примером того, как должна выглядеть «хорошая» (в определенном ниже смысле) эмпирическая функция влияния.
С математической точки зрения функция влияния определяется как вектор в пространстве оценщика, который, в свою очередь, определяется для выборки, которая является подмножеством совокупности:
- - вероятностное пространство,
- измеримое пространство (пространство состояний),
- это пространство параметров измерения ,
- измеримое пространство,





Например,
- любое вероятностное пространство,
- ,
- ,



Определение эмпирической функции влияния: Пусть и находятся i.i.d. и является выборкой из этих переменных. это оценщик. Позволять . Функция эмпирического влияния при наблюдении определяется:








На самом деле это означает, что мы заменяем я-е значение в выборке по произвольному значению и просмотру вывода оценщика. В качестве альтернативы EIF определяется как (масштабируемый на n + 1 вместо n) эффект добавления точки на средство оценки. к образцу.[нужна цитата ]

Функция влияния и кривая чувствительности
Вместо того, чтобы полагаться исключительно на данные, мы могли бы использовать распределение случайных величин. Подход сильно отличается от подхода, описанного в предыдущем абзаце. Что мы сейчас пытаемся сделать, так это посмотреть, что произойдет с оценщиком, когда мы немного изменим распределение данных: предполагается, что распределение, и измеряет чувствительность к изменению этого распределения. Напротив, эмпирическое влияние предполагает набор образцов, и измеряет чувствительность к изменениям в образцах.[5]
Позволять - выпуклое подмножество множества всех конечных мер со знаком на . Мы хотим оценить параметр распределения в . Пусть функционал - асимптотическое значение некоторой последовательности оценок . Предположим, что этот функционал Фишер последовательный, т.е. . Это означает, что у модели , последовательность оценки асимптотически измеряет правильную величину.







Позволять быть некоторым распределением в . Что происходит, когда данные не соответствуют модели точно, но другое, немного другое, "идущее навстречу" ?

Мы смотрим на: ,

какой односторонний Производная Гато из в , в направлении .


Позволять . - вероятностная мера, придающая массе 1 . Мы выбрали . Тогда функция влияния определяется следующим образом:





Он описывает эффект бесконечно малого загрязнения в точке по искомой оценке, стандартизированной массой загрязнения (асимптотическое смещение, вызванное загрязнением в наблюдениях). Для надежной оценки нам нужна ограниченная функция влияния, то есть такая, которая не стремится к бесконечности, когда x становится сколь угодно большим.

Желательные свойства
Свойства функции влияния, придающие ей желаемые характеристики:
- Конечная точка отказа ,
- Малая чувствительность к грубым ошибкам ,
- Малая чувствительность к локальному сдвигу .



Точка отказа

Чувствительность к большой погрешности

Чувствительность к местному смещению

Это значение, которое очень похоже на Постоянная Липшица, представляет собой эффект небольшого смещения наблюдения от в соседнюю точку , т.е. добавить наблюдение в и удалите один в .

М-оценки
(Математический контекст этого параграфа дан в разделе, посвященном эмпирическим функциям влияния.)
Исторически было предложено несколько подходов к робастной оценке, включая R-оценки и L-оценки. Однако сейчас M-оценки, кажется, доминируют в этой области в результате их универсальности, высокой точки пробоя и их эффективности. Видеть Хубер (1981).
M-оценки являются обобщением оценщики максимального правдоподобия (MLEs). Что мы пытаемся делать с MLE, так это максимизировать или, что то же самое, минимизировать . В 1964 году Хубер предложил обобщить это до минимизации , куда это какая-то функция. Таким образом, MLE являются частным случаем M-оценок (отсюда и название: "M"оценки типа максимального правдоподобия").




Сведение к минимуму часто можно сделать, дифференцируя и решение , куда (если имеет производную).


Несколько вариантов и Были предложены. На двух рисунках ниже показаны четыре функции и соответствующие им функции.


Для квадратичных ошибок увеличивается с ускорением, в то время как для абсолютных ошибок он увеличивается с постоянной скоростью. Когда используется Winsorizing, вводится смесь этих двух эффектов: для малых значений x, увеличивается в квадрате скорости, но после достижения выбранного порога (1,5 в этом примере) скорость увеличения становится постоянной. Эта Winsorised оценка также известна как Функция потерь Хубера.

Функция двухвесов Тьюки (также известная как бисквадрат) сначала ведет себя аналогично функции квадратов ошибок, но для больших ошибок функция сужается.

Свойства M-оценок
М-оценки не обязательно связаны с функцией плотности вероятности. Следовательно, стандартные подходы к умозаключениям, возникающие из теории правдоподобия, в общем случае использовать нельзя.
Можно показать, что M-оценки распределены асимптотически нормально, так что, пока их стандартные ошибки могут быть вычислены, приближенный подход к выводу доступен.
Поскольку M-оценки нормальны только асимптотически, для небольших размеров выборки может оказаться целесообразным использовать альтернативный подход к выводу, такой как бутстрап. Однако M-оценки не обязательно уникальны (т.е. может быть более одного решения, удовлетворяющего уравнениям). Кроме того, возможно, что любая конкретная выборка начальной загрузки может содержать больше выбросов, чем точка разбивки оценщика. Поэтому при разработке схем начальной загрузки требуется некоторая осторожность.
Конечно, как мы видели на примере скорости света, среднее только нормально распределено асимптотически, и когда присутствуют выбросы, аппроксимация может быть очень плохой даже для довольно больших выборок. Однако классические статистические тесты, в том числе те, которые основаны на среднем значении, обычно ограничиваются номинальным размером теста. То же самое не относится к M-оценкам, и частота ошибок типа I может быть значительно выше номинального уровня.
Эти соображения никоим образом не «аннулируют» М-оценку. Они просто дают понять, что при их использовании требуется некоторая осторожность, как и в отношении любого другого метода оценки.
Функция влияния M-оценки
Можно показать, что функция влияния M-оценки пропорционально ,[6] это означает, что мы можем получить свойства такого оценщика (такие как его точка отклонения, чувствительность к грубым ошибкам или чувствительность к локальному сдвигу), когда мы знаем его функция.

с предоставлено:


Выбор ψ и ρ
Во многих практических ситуациях выбор Функция не является критичной для получения хорошей надежной оценки, и многие варианты дадут аналогичные результаты, которые предлагают большие улучшения с точки зрения эффективности и систематической ошибки по сравнению с классическими оценками при наличии выбросов.[7]
Теоретически функции должны быть предпочтительными,[требуется разъяснение ] а функция двойного веса Тьюки (также известная как бис-квадрат) является популярным выбором. Маронна, Мартин и Йохай (2006) рекомендуют функцию двойного веса с эффективностью при нормальном значении 85%.
Надежные параметрические подходы
М-оценки не обязательно связаны с функцией плотности и поэтому не являются полностью параметрическими. Полностью параметрические подходы к надежному моделированию и логическому выводу, как байесовский, так и вероятностный подходы, обычно имеют дело с распределениями с тяжелыми хвостами, такими как распределение Стьюдента. т-распределение.
Для т-распространение с степеней свободы, можно показать, что


За , то т-распределение эквивалентно распределению Коши. Степени свободы иногда называют параметр эксцесса. Это параметр, который определяет, насколько тяжелы хвосты. В принципе, можно оценить по данным так же, как и любой другой параметр. На практике часто бывает несколько локальных максимумов, когда разрешено варьироваться. Таким образом, обычно исправляют при значении около 4 или 6. На рисунке ниже показан -функция для 4 различных значений .


Пример: данные о скорости света
Для данных о скорости света, позволяя варьировать параметр эксцесса и увеличивая вероятность, мы получаем

Фиксация и максимальное увеличение вероятности дает


Связанные понятия
А основное количество является функцией данных, базовое распределение населения которых является членом параметрического семейства, которое не зависит от значений параметров. An вспомогательная статистика такая функция, которая также является статистикой, что означает, что она вычисляется только на основе данных. Такие функции устойчивы к параметрам в том смысле, что они не зависят от значений параметров, но не устойчивы к модели в том смысле, что они предполагают базовую модель (параметрическое семейство), и фактически такие функции часто очень чувствительны к нарушения модельных предположений. Таким образом статистика тестов, которые часто строятся с учетом этих параметров, чтобы не зависеть от предположений о параметрах, по-прежнему очень чувствительны к предположениям модели.
Замена выбросов и пропущенных значений
Замена отсутствующие данные называется вменение. Если пропущенных точек относительно мало, есть несколько моделей, которые можно использовать для оценки значений для завершения ряда, например, замена пропущенных значений средним или медианным значением данных. Простая линейная регрессия также может использоваться для оценки пропущенных значений.[8] Кроме того, выбросы иногда могут быть включены в данные с помощью усеченных средних, других оценщиков шкалы, кроме стандартного отклонения (например, MAD) и винсоризации.[9] При вычислениях усеченного среднего фиксированный процент данных удаляется с каждого конца упорядоченных данных, тем самым устраняя выбросы. Затем рассчитывается среднее значение с использованием оставшихся данных. Winsorizing включает в себя корректировку выброса путем замены его следующим по величине или следующим наименьшим значением, в зависимости от ситуации.[10]
Однако использование этих типов моделей для прогнозирования пропущенных значений или выбросов в длинных временных рядах сложно и часто ненадежно, особенно если количество значений, подлежащих заполнению, относительно велико по сравнению с общей длиной записи. Точность оценки зависит от того, насколько хороша и репрезентативна модель и как долго длится период пропущенных значений.[11] В случае динамического процесса любая переменная зависит не только от исторических временных рядов той же переменной, но также и от нескольких других переменных или параметров процесса.[требуется разъяснение ] Другими словами, проблема заключается в упражнении в многомерном анализе, а не в одномерном подходе большинства традиционных методов оценки пропущенных значений и выбросов; Следовательно, многомерная модель будет более репрезентативной, чем одномерная, для прогнозирования пропущенных значений. В Самоорганизующаяся карта Кохонена (KSOM) предлагает простую и надежную многомерную модель для анализа данных, тем самым предоставляя хорошие возможности для оценки отсутствующих значений, принимая во внимание их взаимосвязь или корреляцию с другими соответствующими переменными в записи данных.[10]
Стандарт Фильтры Калмана не устойчивы к выбросам. С этой целью Тинг, Теодору и Шаал (2007) недавно показали, что модификация Теорема Масрелица может иметь дело с выбросами.
Один из распространенных подходов к обработке выбросов при анализе данных - сначала выполнить обнаружение выбросов, а затем использовать эффективный метод оценки (например, методом наименьших квадратов). Хотя этот подход часто бывает полезным, следует помнить о двух проблемах. Во-первых, метод обнаружения выбросов, основанный на ненадежной начальной подгонке, может пострадать от эффекта маскировки, то есть группа выбросов может маскировать друг друга и избегать обнаружения.[12] Во-вторых, если для обнаружения выбросов используется начальная аппроксимация с высокой разбивкой, последующий анализ может унаследовать некоторые неэффективности первоначальной оценки.[13]
Смотрите также
Примечания
- ^ а б c Хубер (1981), Страница 1.
- ^ Руссей и Крук (1993).
- ^ Мастерс, Джеффри. «Когда была открыта озоновая дыра». Weather Underground. Архивировано из оригинал на 2016-09-15.
- ^ Устойчивая статистика, Дэвид Б. Стивенсон
- ^ фон Мизес (1947).
- ^ Хубер (1981), стр.45
- ^ Хубер (1981).
- ^ Макдональд и цуккини (1997); Харви (1989).
- ^ Макбин и Роверс (1998).
- ^ а б Растум и Аделой (2007).
- ^ Розен и Леннокс (2001).
- ^ Руссей и Лерой (1987).
- ^ Он и Портной (1992).
Рекомендации
- Farcomeni, A .; Греко, Л. (2013), Надежные методы обработки данных, Бока-Ратон, Флорида: Chapman & Hall / CRC Press, ISBN 978-1-4665-9062-5.
- Hampel, Frank R .; Ronchetti, Elvezio M .; Руссей, Питер Дж.; Стахел, Вернер А. (1986), Надежная статистика, Ряд Уайли по вероятности и математической статистике: вероятность и математическая статистика, Нью-Йорк: John Wiley & Sons, Inc., ISBN 0-471-82921-8, МИСТЕР 0829458. Переиздан в мягкой обложке, 2005 г.
- Он, Сюмин; Портной, Стивен (1992), «Повторно взвешенные оценки LS сходятся с той же скоростью, что и первоначальная оценка», Анналы статистики, 20 (4): 2161–2167, Дои:10.1214 / aos / 1176348910, МИСТЕР 1193333.
- Он, Сюмин; Симпсон, Дуглас Дж .; Портной, Стивен Л. (1990), "Устойчивость испытаний к отказу", Журнал Американской статистической ассоциации, 85 (410): 446–452, Дои:10.2307/2289782, JSTOR 2289782, МИСТЕР 1141746.
- Hettmansperger, T. P .; Маккин, Дж. У. (1998), Надежные непараметрические статистические методы, Библиотека статистики Кендалла, 5, Нью-Йорк: John Wiley & Sons, Inc., ISBN 0-340-54937-8, МИСТЕР 1604954. 2-е изд., CRC Press, 2011.
- Хубер, Питер Дж. (1981), Надежная статистика, Нью-Йорк: John Wiley & Sons, Inc., ISBN 0-471-41805-6, МИСТЕР 0606374. Переиздано в мягкой обложке, 2004. 2-е изд., Wiley, 2009.
- Маронна, Рикардо А .; Мартин, Р. Дуглас; Йохай, Виктор Дж. (2006), Надежная статистика: теория и методы, Серия Wiley по вероятности и статистике, Chichester: John Wiley & Sons, Ltd., Дои:10.1002/0470010940, ISBN 978-0-470-01092-1, МИСТЕР 2238141.
- Макбин, Эдвард А .; Роверс, Фрэнк (1998), Статистические процедуры анализа данных и оценки экологического мониторинга, Прентис-Холл.
- Портной, Стивен; Он, Сюмин (2000), «Интенсивное путешествие в новое тысячелетие», Журнал Американской статистической ассоциации, 95 (452): 1331–1335, Дои:10.2307/2669782, JSTOR 2669782, МИСТЕР 1825288.
- Press, Уильям Х.; Теукольский, Саул А.; Веттерлинг, Уильям Т .; Фланнери, Брайан П. (2007), «Раздел 15.7. Надежная оценка», Числовые рецепты: искусство научных вычислений (3-е изд.), Cambridge University Press, ISBN 978-0-521-88068-8, МИСТЕР 2371990.
- Rosen, C .; Леннокс, Дж. (Октябрь 2001 г.), «Многомасштабный и многомасштабный мониторинг работы по очистке сточных вод», Водные исследования, 35 (14): 3402–3410, Дои:10.1016 / s0043-1354 (01) 00069-0, PMID 11547861.
- Руссей, Питер Дж.; Кру, Кристоф (1993), "Альтернативы среднему абсолютному отклонению", Журнал Американской статистической ассоциации, 88 (424): 1273–1283, Дои:10.2307/2291267, JSTOR 2291267, МИСТЕР 1245360.
- Руссей, Питер Дж.; Лерой, Анник М. (1987), Надежная регрессия и обнаружение выбросов, Серия Wiley по вероятности и математической статистике: прикладная вероятность и статистика, Нью-Йорк: John Wiley & Sons, Inc., Дои:10.1002/0471725382, ISBN 0-471-85233-3, МИСТЕР 0914792. Переиздан в мягкой обложке, 2003 г.
- Руссей, Питер Дж.; Юбер, Миа (2011), «Надежная статистика для обнаружения выбросов», Междисциплинарные обзоры Wiley: интеллектуальный анализ данных и открытие знаний, 1 (1): 73–79, Дои:10.1002 / widm.2. Препринт
- Рустум, Раби; Аделой, Адебайо Дж. (Сентябрь 2007 г.), «Замена выбросов и пропущенных значений из данных по активному илу с использованием самоорганизующейся карты Кохонена», Журнал экологической инженерии, 133 (9): 909–916, Дои:10.1061 / (восхождение) 0733-9372 (2007) 133: 9 (909).
- Стиглер, Стивен М. (2010), «Изменяющаяся история устойчивости», Американский статистик, 64 (4): 277–281, Дои:10.1198 / вкус.2010.10159, МИСТЕР 2758558, S2CID 10728417.
- Тинг, Джо-Энн; Теодору, Евангелос; Шаал, Стефан (2007), «Фильтр Калмана для надежного обнаружения выбросов», Международная конференция по интеллектуальным роботам и системам - IROS, стр. 1514–1519.
- фон Мизес, Р. (1947), «Об асимптотическом распределении дифференцируемых статистических функций», Анналы математической статистики, 18 (3): 309–348, Дои:10.1214 / aoms / 1177730385, МИСТЕР 0022330.
- Уилкокс, Рэнд (2012), Введение в робастную оценку и проверку гипотез, Статистическое моделирование и наука о принятии решений (3-е изд.), Амстердам: Elsevier / Academic Press, стр. 1–22, Дои:10.1016 / B978-0-12-386983-8.00001-9, ISBN 978-0-12-386983-8, МИСТЕР 3286430.
внешняя ссылка
- Брайан Рипли подробные статистические заметки по курсу.
- Заметки о курсе Ника Филлера по статистическому моделированию и вычислениям содержат материал о надежной регрессии.
- Сайт Дэвида Олива содержит заметки курса по надежной статистике и некоторым наборам данных.
- Онлайн-эксперименты с использованием R и JSXGraph