Параллельные вычисления - Parallel computing

Параллельные вычисления это тип вычисление где много расчетов или выполнение процессы выполняются одновременно.[1] Большие проблемы часто можно разделить на более мелкие, которые затем можно решить одновременно. Есть несколько различных форм параллельных вычислений: битовый уровень, уровень обучения, данные, и параллелизм задач. Параллелизм уже давно используется в высокопроизводительные вычисления, но вызвал более широкий интерес из-за физических ограничений, препятствующих частотное масштабирование.[2] Поскольку в последние годы потребление энергии (и, как следствие, тепловыделение) компьютерами стало проблемой,[3] параллельные вычисления стали доминирующей парадигмой в компьютерная архитектура, в основном в виде многоядерные процессоры.[4]
Параллельные вычисления тесно связаны с параллельные вычисления - они часто используются вместе и часто объединяются, хотя они и отличаются друг от друга: возможен параллелизм без параллелизма (например, битовый параллелизм ) и параллелизм без параллелизма (например, многозадачность совместное времяпровождение на одноядерном процессоре).[5][6] При параллельных вычислениях вычислительная задача обычно разбивается на несколько, часто много, очень похожих подзадач, которые могут обрабатываться независимо и чьи результаты объединяются впоследствии по завершении. Напротив, в параллельных вычислениях различные процессы часто не решают связанные задачи; когда они это сделают, как это типично для распределенных вычислений, отдельные задачи могут иметь различный характер и часто требуют межпроцессного взаимодействия во время исполнения.
Параллельные компьютеры можно примерно классифицировать по уровню, на котором оборудование поддерживает параллелизм, с многоядерный и мультипроцессор компьютеры, имеющие несколько элементы обработки в пределах одной машины, а кластеры, MPP, и сетки использовать несколько компьютеров для работы над одной задачей. Специализированные параллельные компьютерные архитектуры иногда используются вместе с традиционными процессорами для ускорения конкретных задач.
В некоторых случаях параллелизм прозрачен для программиста, например, на уровне битов или на уровне команд, но явно параллельные алгоритмы, особенно те, которые используют параллелизм, написать сложнее, чем последовательный те,[7] поскольку параллелизм вводит несколько новых классов потенциальных программные ошибки, из которых условия гонки являются наиболее распространенными. Общение и синхронизация между различными подзадачами обычно являются одними из самых больших препятствий на пути к оптимальной производительности параллельной программы.
Теоретический верхняя граница на ускорение отдельной программы в результате распараллеливания Закон Амдала.
Задний план
Традиционно программное обеспечение был написан для последовательное вычисление. Чтобы решить проблему, алгоритм построен и реализован как последовательный поток инструкций. Эти инструкции выполняются на центральное процессорное устройство на одном компьютере. Одновременно может выполняться только одна инструкция - после завершения этой инструкции выполняется следующая.[8]
С другой стороны, в параллельных вычислениях для решения проблемы одновременно используются несколько элементов обработки. Это достигается путем разбиения задачи на независимые части, чтобы каждый обрабатывающий элемент мог выполнять свою часть алгоритма одновременно с другими. Элементы обработки могут быть разнообразными и включать в себя такие ресурсы, как один компьютер с несколькими процессорами, несколько сетевых компьютеров, специализированное оборудование или любую комбинацию вышеперечисленного.[8] Исторически параллельные вычисления использовались для научных вычислений и моделирования научных проблем, особенно в естественных и технических науках, таких как метеорология. Это привело к разработке параллельного аппаратного и программного обеспечения, а также высокопроизводительные вычисления.[9]
Масштабирование частоты была основной причиной улучшения производительность компьютера с середины 1980-х до 2004 года. время выполнения программы равно количеству инструкций, умноженному на среднее время выполнения одной инструкции. Сохраняя все остальное постоянным, увеличение тактовой частоты уменьшает среднее время, необходимое для выполнения инструкции. Таким образом, увеличение частоты сокращает время работы для всех ограниченный вычислением программы.[10] Однако потребляемая мощность п микросхемой задается уравнением п = C × V 2 × F, где C это емкость переключается за такт (пропорционально количеству транзисторов, входы которых меняются), V является Напряжение, и F - частота процессора (циклов в секунду).[11] Увеличение частоты увеличивает количество энергии, используемой процессором. Увеличение энергопотребления процессора в конечном итоге привело к Intel отмена 8 мая 2004 г. Теджас и Джейхок процессоров, которые обычно называют окончанием масштабирования частоты как доминирующей парадигмы компьютерной архитектуры.[12]
Решить проблему энергопотребления и перегрева основных центральное процессорное устройство Производители (ЦП или процессоров) начали производить энергоэффективные процессоры с несколькими ядрами. Ядро является вычислительным блоком процессора, а в многоядерных процессорах каждое ядро является независимым и может одновременно обращаться к одной и той же памяти. Многоядерные процессоры принесли параллельные вычисления в настольные компьютеры. Таким образом, распараллеливание последовательных программ стало основной задачей программирования. В 2012 году четырехъядерные процессоры стали стандартом для настольные компьютеры, в то время как серверы имеют 10- и 12-ядерные процессоры. От Закон Мура можно прогнозировать, что количество ядер на процессор будет удваиваться каждые 18–24 месяца. Это может означать, что после 2020 года типичный процессор будет иметь десятки или сотни ядер.[13]
An Операционная система может гарантировать, что разные задачи и пользовательские программы выполняются параллельно на доступных ядрах. Однако для того, чтобы программа с последовательным интерфейсом могла полностью использовать преимущества многоядерной архитектуры, программисту необходимо реструктурировать и распараллелить код. Ускорение времени выполнения прикладного программного обеспечения больше не будет достигаться за счет частотного масштабирования, вместо этого программистам придется распараллеливать свой программный код, чтобы воспользоваться преимуществами растущей вычислительной мощности многоядерных архитектур.[14]
Закон Амдала и закон Густафсона
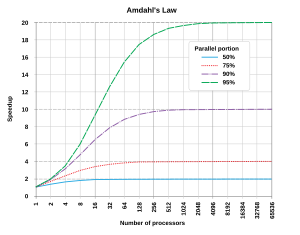
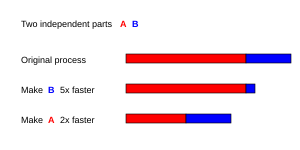
Оптимально ускорение от распараллеливания будет линейным - удвоение числа обрабатывающих элементов должно вдвое сократить время выполнения, а повторное удвоение должно снова сократить вдвое время выполнения. Однако очень немногие параллельные алгоритмы обеспечивают оптимальное ускорение. Большинство из них имеют почти линейное ускорение для небольшого количества элементов обработки, которое выравнивается до постоянного значения для большого количества элементов обработки.
Потенциальное ускорение алгоритма на платформе параллельных вычислений определяется выражением Закон Амдала[15]

где
- Sзадержка это потенциал ускорение в задержка выполнения всей задачи;
- s - ускорение задержки выполнения распараллеливаемой части задачи;
- п - это процент времени выполнения всей задачи относительно распараллеливаемой части задачи до распараллеливания.
поскольку Sзадержка < 1/(1 - п), это показывает, что небольшая часть программы, которую нельзя распараллелить, ограничит общее ускорение, доступное от распараллеливания. Программа, решающая большие математические или инженерные задачи, обычно состоит из нескольких распараллеливаемых частей и нескольких непараллелизируемых (последовательных) частей. Если непараллелизируемая часть программы составляет 10% времени выполнения (п = 0,9), мы можем получить ускорение не более чем в 10 раз, независимо от того, сколько процессоров добавлено. Это устанавливает верхний предел полезности добавления дополнительных модулей параллельного выполнения. «Когда задача не может быть разделена из-за ограничений последовательности, приложение дополнительных усилий не влияет на расписание. Рождение ребенка занимает девять месяцев, независимо от того, сколько женщин назначено».[16]

Закон Амдала применим только к случаям, когда размер проблемы фиксирован. На практике по мере того, как становится доступным больше вычислительных ресурсов, они, как правило, используются для решения более крупных задач (больших наборов данных), и время, затрачиваемое на параллелизируемую часть, часто растет намного быстрее, чем при изначально последовательной работе.[17] В таком случае, Закон Густафсона дает менее пессимистичную и более реалистичную оценку параллельной производительности:[18]

И закон Амдала, и закон Густафсона предполагают, что время работы последовательной части программы не зависит от количества процессоров. Закон Амдала предполагает, что вся проблема имеет фиксированный размер, поэтому общий объем работы, которая должна выполняться параллельно, также независимо от количества процессоров, тогда как закон Густафсона предполагает, что общий объем работы, выполняемой параллельно линейно зависит от количества процессоров.
Зависимости
Понимание зависимости данных имеет основополагающее значение для реализации параллельные алгоритмы. Ни одна программа не может работать быстрее, чем самая длинная цепочка зависимых вычислений (известная как критический путь ), поскольку вычисления, которые зависят от предыдущих вычислений в цепочке, должны выполняться по порядку. Однако большинство алгоритмов не состоят только из длинной цепочки зависимых вычислений; обычно есть возможность выполнять независимые вычисления параллельно.
Позволять пя и пj быть двумя программными сегментами. Условия Бернштейна[19] описывают, когда они независимы и могут выполняться параллельно. Для пя, позволять яя быть всеми входными переменными и Оя выходные переменные, а также для пj. пя и пj независимы, если они удовлетворяют



Нарушение первого условия приводит к поточной зависимости, соответствующей первому сегменту, дающему результат, используемый вторым сегментом. Второе условие представляет собой анти-зависимость, когда второй сегмент создает переменную, необходимую для первого сегмента. Третье и последнее условие представляет выходную зависимость: когда два сегмента записывают в одно и то же место, результат исходит из логически последнего выполненного сегмента.[20]
Рассмотрим следующие функции, которые демонстрируют несколько видов зависимостей:
1: функция Dep (a, b) 2: c: = a * b3: d: = 3 * c4: конечная функция
В этом примере команда 3 не может быть выполнена до (или даже параллельно) с инструкцией 2, потому что инструкция 3 использует результат из инструкции 2. Она нарушает условие 1 и, таким образом, вводит зависимость потока.
1: функция NoDep (a, b) 2: c: = a * b3: d: = 3 * b4: e: = a + b5: конечная функция
В этом примере между инструкциями нет зависимостей, поэтому все они могут выполняться параллельно.
Условия Бернштейна не позволяют разделять память между разными процессами. Для этого необходимы некоторые средства обеспечения порядка между доступами, такие как семафоры, барьеры или какой-то другой метод синхронизации.
Условия гонки, взаимное исключение, синхронизация и параллельное замедление
Подзадачи в параллельной программе часто называют потоки. Некоторые параллельные компьютерные архитектуры используют меньшие, облегченные версии потоков, известные как волокна, в то время как другие используют более крупные версии, известные как процессы. Однако термин «потоки» обычно используется как общий термин для подзадач.[21] Потоки часто понадобятся синхронизированный доступ к объект или другой ресурс, например, когда они должны обновить переменная это разделено между ними. Без синхронизации инструкции между двумя потоками могут чередоваться в любом порядке. Например, рассмотрим следующую программу:
| Поток А | Резьба B |
| 1A: чтение переменной V | 1B: чтение переменной V |
| 2A: добавить 1 к переменной V | 2B: добавить 1 к переменной V |
| 3A: обратная запись в переменную V | 3B: обратная запись в переменную V |
Если команда 1B выполняется между 1A и 3A или если команда 1A выполняется между 1B и 3B, программа выдаст неверные данные. Это известно как состояние гонки. Программист должен использовать замок предоставлять взаимное исключение. Блокировка - это конструкция языка программирования, которая позволяет одному потоку управлять переменной и предотвращать ее чтение или запись другими потоками, пока эта переменная не будет разблокирована. Поток, удерживающий блокировку, может выполнить свое критическая секция (раздел программы, требующий монопольного доступа к некоторой переменной), и для разблокировки данных по завершении. Следовательно, чтобы гарантировать правильное выполнение программы, указанная выше программа может быть переписана для использования блокировок:
| Поток А | Резьба B |
| 1A: переменная блокировки V | 1B: заблокировать переменную V |
| 2A: чтение переменной V | 2B: чтение переменной V |
| 3A: добавить 1 к переменной V | 3B: добавить 1 к переменной V |
| 4A: обратная запись в переменную V | 4B: обратная запись в переменную V |
| 5A: переменная разблокировки V | 5B: переменная разблокировки V |
Один поток успешно заблокирует переменную V, а другой поток будет заблокирован - невозможно продолжить, пока V снова не разблокируется. Это гарантирует правильное выполнение программы. Блокировки могут быть необходимы для обеспечения правильного выполнения программы, когда потоки должны сериализовать доступ к ресурсам, но их использование может значительно замедлить программу и повлиять на ее выполнение. надежность.[22]
Блокировка нескольких переменных с помощью неатомный замки вводит возможность программирования тупик. An атомный замок блокирует сразу несколько переменных. Если он не может заблокировать все из них, он не блокирует ни один из них. Если каждому из двух потоков требуется заблокировать одни и те же две переменные с помощью неатомных блокировок, возможно, что один поток заблокирует одну из них, а второй поток заблокирует вторую переменную. В таком случае ни один поток не может завершиться, что приведет к тупиковой ситуации.[23]
Многие параллельные программы требуют, чтобы их подзадачи действовать синхронно. Это требует использования барьер. Барьеры обычно реализуются с помощью замка или семафор.[24] Один класс алгоритмов, известный как алгоритмы без блокировки и ожидания, полностью избегает использования замков и барьеров. Однако этот подход обычно сложно реализовать и требует правильно спроектированных структур данных.[25]
Не всякое распараллеливание приводит к ускорению. Как правило, по мере того, как задача разбивается на все больше и больше потоков, эти потоки тратят все большую часть своего времени на общение друг с другом или ожидание друг друга для доступа к ресурсам.[26][27] Когда накладные расходы из-за конкуренции за ресурсы или обмена данными преобладают над временем, затрачиваемым на другие вычисления, дальнейшее распараллеливание (то есть разделение рабочей нагрузки на еще большее количество потоков) увеличивает, а не уменьшает время, необходимое для завершения. Эта проблема, известная как параллельное замедление,[28] в некоторых случаях может быть улучшена путем анализа и изменения программного обеспечения.[29]
Мелкозернистый, крупнозернистый и неприятный параллелизм
Приложения часто классифицируются в зависимости от того, как часто их подзадачи должны синхронизироваться или взаимодействовать друг с другом. Приложение демонстрирует мелкозернистый параллелизм, если его подзадачи должны взаимодействовать много раз в секунду; он демонстрирует крупнозернистый параллелизм, если они не обмениваются данными много раз в секунду, и он показывает смущающий параллелизм если они редко или никогда не должны общаться. Досадно параллельные приложения считаются самыми простыми для распараллеливания.
Модели согласованности
Языки параллельного программирования и параллельные компьютеры должны иметь модель согласованности (также известная как модель памяти). Модель согласованности определяет правила того, как операции с память компьютера происходят и как получаются результаты.
Одна из первых моделей согласованности была Лесли Лэмпорт с последовательная последовательность модель. Последовательная согласованность - это свойство параллельной программы, что ее параллельное выполнение дает те же результаты, что и последовательная программа. В частности, программа является последовательной, если «результаты любого выполнения такие же, как если бы операции всех процессоров выполнялись в некотором последовательном порядке, и операции каждого отдельного процессора появляются в этой последовательности в порядке, указанном его программой. ".[30]
Программная транзакционная память - это распространенный тип модели согласованности. Программная транзакционная память заимствует теория баз данных Концепция чего-либо атомарные транзакции и применяет их к доступам к памяти.
Математически эти модели можно представить несколькими способами. Представлен в 1962 году, Сети Петри были ранней попыткой кодифицировать правила моделей согласованности. Теория потока данных позже основывалась на этом, и Архитектуры потока данных были созданы для физической реализации идей теории потоков данных. Начиная с конца 1970-х гг., технологические расчеты такие как Расчет коммуникационных систем и Связь последовательных процессов были разработаны, чтобы позволить алгебраические рассуждения о системах, состоящих из взаимодействующих компонентов. Более свежие дополнения к семейству исчислений процессов, такие как π-исчисление, добавили возможность рассуждать о динамических топологиях. Логика вроде Лампорта TLA +, и математические модели, такие как следы и Диаграммы актерских событий, также были разработаны для описания поведения параллельных систем.
Таксономия Флинна
Майкл Дж. Флинн создал одну из первых систем классификации для параллельных (и последовательных) компьютеров и программ, теперь известную как Таксономия Флинна. Флинн классифицировал программы и компьютеры по тому, работали ли они с одним набором или с несколькими наборами инструкций, и использовали ли эти инструкции один набор или несколько наборов данных.
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
Классификация «одна инструкция - одни данные» (SISD) эквивалентна полностью последовательной программе. Классификация «одна инструкция - несколько данных» (SIMD) аналогична многократному выполнению одной и той же операции над большим набором данных. Обычно это делается в обработка сигнала Приложения. Классификация с несколькими инструкциями и отдельными данными (MISD) используется редко. В то время как компьютерные архитектуры были разработаны для решения этой проблемы (например, систолические массивы ), появилось несколько приложений, подходящих к этому классу. Программы с несколькими инструкциями и несколькими данными (MIMD) являются наиболее распространенным типом параллельных программ.
Согласно с Дэвид А. Паттерсон и Джон Л. Хеннесси «Некоторые машины, конечно, являются гибридами этих категорий, но эта классическая модель сохранилась, потому что она проста, легка для понимания и дает хорошее первое приближение. Это также - возможно, из-за своей понятности - наиболее широко используемая схема . "[31]
Типы параллелизма
Битовый параллелизм
С появлением очень крупномасштабная интеграция (VLSI) технология изготовления компьютерных микросхем в 1970-х и примерно до 1986 года, ускорение компьютерной архитектуры было обусловлено удвоением размер компьютерного слова - объем информации, которым процессор может управлять за цикл.[32] Увеличение размера слова уменьшает количество инструкций, которые процессор должен выполнить, чтобы выполнить операцию с переменными, размер которых превышает длину слова. Например, где 8 бит процессор должен добавить два 16 бит целые числа, процессор должен сначала сложить 8 младших битов из каждого целого числа, используя стандартную инструкцию сложения, затем добавить 8 старших битов, используя инструкцию добавления с переносом и бит для переноски от сложения низшего порядка; таким образом, 8-битный процессор требует двух инструкций для выполнения одной операции, тогда как 16-битный процессор сможет завершить операцию с помощью одной инструкции.
Исторически, 4-битный микропроцессоры были заменены 8-битными, затем 16-битными, затем 32-битными микропроцессорами. Эта тенденция в целом закончилась с появлением 32-разрядных процессоров, которые были стандартом в вычислениях общего назначения в течение двух десятилетий. Только в начале 2000-х, с появлением x86-64 архитектуры, сделал 64-битный процессоры становятся обычным явлением.
Параллелизм на уровне инструкций
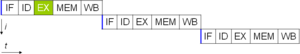

Компьютерная программа - это, по сути, поток инструкций, выполняемых процессором. Без параллелизма на уровне команд процессор может выдать только менее одного инструкция за такт (МПК <1). Эти процессоры известны как субскалярный процессоры. Эти инструкции могут быть переупорядочен и объединяются в группы, которые затем выполняются параллельно без изменения результата программы. Это называется параллелизмом на уровне инструкций. Достижения в области параллелизма на уровне команд доминировали в компьютерной архитектуре с середины 1980-х до середины 1990-х годов.[33]
Все современные процессоры имеют многоступенчатую конвейеры команд. Каждый этап конвейера соответствует разному действию, которое процессор выполняет над этой инструкцией на этом этапе; процессор с N-ступенчатый конвейер может иметь до N разные инструкции на разных стадиях завершения и, таким образом, могут выдавать одну инструкцию за такт (МПК = 1). Эти процессоры известны как скаляр процессоры. Канонический пример конвейерного процессора - это RISC Процессор с пятью этапами: выборка команды (IF), декодирование команды (ID), выполнение (EX), доступ к памяти (MEM) и обратная запись в регистр (WB). В Pentium 4 процессор имел 35-ступенчатый конвейер.[34]
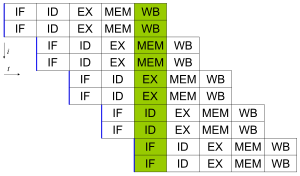
Большинство современных процессоров также имеют несколько исполнительные единицы. Обычно они сочетают эту функцию с конвейерной обработкой и, таким образом, могут выдавать более одной инструкции за такт (МПК> 1). Эти процессоры известны как суперскалярный процессоры. Инструкции можно сгруппировать только в том случае, если нет зависимость данных между ними. Табло и Алгоритм Томасуло (который похож на табло, но использует зарегистрировать переименование ) - два наиболее распространенных метода реализации неупорядоченного выполнения и параллелизма на уровне команд.
Параллелизм задач
Параллелизм задач - это характеристика параллельной программы, заключающаяся в том, что «совершенно разные вычисления могут выполняться как на одном, так и на разных наборах данных».[35] Это контрастирует с параллелизмом данных, когда одни и те же вычисления выполняются на одном и том же или на разных наборах данных. Параллелизм задач включает в себя декомпозицию задачи на подзадачи с последующим выделением каждой подзадачи процессору для выполнения. Затем процессоры будут выполнять эти подзадачи одновременно и часто совместно. Параллелизм задач обычно не зависит от размера проблемы.[36]
Параллелизм на уровне сверхслова
Параллелизм на уровне сверхслова - это векторизация техника, основанная на разворачивание петли и базовая блочная векторизация.Он отличается от алгоритмов векторизации цикла тем, что может использовать параллелизм из встроенный код, например, управление координатами, цветовыми каналами или циклами, развернутыми вручную.[37]
Оборудование
Память и общение
Основная память в параллельном компьютере либо Общая память (совместно используется всеми обрабатывающими элементами в одном адресное пространство ), или распределенная память (в котором каждый обрабатывающий элемент имеет собственное локальное адресное пространство).[38] Распределенная память относится к тому факту, что память распределена логически, но часто подразумевает, что она также распределена физически. Распределенная разделяемая память и виртуализация памяти объединить два подхода, в которых элемент обработки имеет свою собственную локальную память и доступ к памяти на нелокальных процессорах. Доступ к локальной памяти обычно быстрее, чем доступ к нелокальной памяти. На суперкомпьютеры, распределенное пространство разделяемой памяти может быть реализовано с использованием такой модели программирования, как PGAS. Эта модель позволяет процессам на одном вычислительном узле получать прозрачный доступ к удаленной памяти другого вычислительного узла. Все вычислительные узлы также подключены к внешней системе с общей памятью через высокоскоростное соединение, например Infiniband, эта внешняя система с общей памятью известна как пакетный буфер, который обычно строится из массивов энергонезависимая память физически распределены по нескольким узлам ввода-вывода.
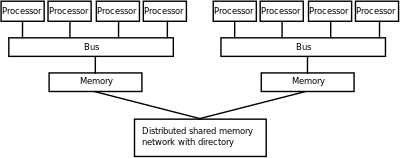
Компьютерные архитектуры, в которых к каждому элементу основной памяти можно обращаться с равными задержка и пропускная способность известны как единый доступ к памяти (UMA) системы. Обычно этого можно добиться только Общая память система, в которой память физически не распределена. Система, не имеющая этого свойства, называется неравномерный доступ к памяти (NUMA) архитектура. Системы с распределенной памятью имеют неравномерный доступ к памяти.
Компьютерные системы используют тайники - небольшие и быстрые запоминающие устройства, расположенные рядом с процессором, в которых хранятся временные копии значений памяти (поблизости как в физическом, так и в логическом смысле). Параллельные компьютерные системы испытывают трудности с кешами, которые могут хранить одно и то же значение более чем в одном месте, с возможностью некорректного выполнения программы. Этим компьютерам требуется согласованность кеша система, которая отслеживает кэшированные значения и стратегически очищает их, обеспечивая тем самым правильное выполнение программы. Слежение за автобусом - один из наиболее распространенных методов отслеживания того, к каким значениям осуществляется доступ (и, следовательно, их следует удалить). Проектирование больших высокопроизводительных систем согласования кэш-памяти - очень сложная проблема в компьютерной архитектуре. В результате компьютерные архитектуры с общей памятью масштабируются хуже, чем системы с распределенной памятью.[38]
Связь между процессором и процессором и памятью процессора может быть реализована на аппаратном уровне несколькими способами, в том числе через совместное использование (многопортовый или мультиплексированный ) память, а поперечный переключатель, общий автобус или межблочная сеть из множества топологии в том числе звезда, кольцо, дерево, гиперкуб, толстый гиперкуб (гиперкуб с более чем одним процессором в узле) или n-мерная сетка.
Параллельные компьютеры на основе взаимосвязанных сетей должны иметь маршрутизация чтобы разрешить передачу сообщений между узлами, которые не связаны напрямую. Среда, используемая для связи между процессорами, скорее всего, будет иерархической в больших многопроцессорных машинах.
Классы параллельных компьютеров
Параллельные компьютеры можно примерно классифицировать по уровню, на котором оборудование поддерживает параллелизм. Эта классификация в целом аналогична расстоянию между базовыми вычислительными узлами. Они не исключают друг друга; например, кластеры симметричных мультипроцессоров довольно распространены.
Многоядерные вычисления
Многоядерный процессор - это процессор, включающий несколько блоки обработки (называемые «ядрами») на одном чипе. Этот процессор отличается от суперскалярный процессор, включающий несколько исполнительные единицы и может выдавать несколько инструкций за такт из одного потока инструкций (потока); Напротив, многоядерный процессор может выдавать несколько инструкций за такт из нескольких потоков инструкций. IBM с Микропроцессор клетки, предназначен для использования в Sony PlayStation 3, является известным многоядерным процессором. Каждое ядро многоядерного процессора потенциально также может быть суперскалярным, то есть в каждом тактовом цикле каждое ядро может выдавать несколько инструкций из одного потока.
Одновременная многопоточность (из которых Intel Hyper Threading является наиболее известным) был ранней формой псевдо-многоядерности. Процессор, способный к одновременной многопоточности, включает в себя несколько исполнительных модулей в одном процессоре, то есть он имеет суперскалярную архитектуру, и может выдавать несколько инструкций за тактовый цикл из множественный потоки. Временная многопоточность с другой стороны, включает в себя один исполнительный блок в одном и том же процессоре и может выдавать по одной инструкции за раз из множественный потоки.
Симметричная многопроцессорная обработка
Симметричный мультипроцессор (SMP) - это компьютерная система с несколькими идентичными процессорами, которые совместно используют память и подключаются через автобус.[39] Автобусный спор предотвращает масштабирование архитектуры шины. В результате SMP обычно состоят не более чем из 32 процессоров.[40] Из-за небольшого размера процессоров и значительного снижения требований к полосе пропускания шины, достигаемого за счет больших кэш-памяти, такие симметричные мультипроцессоры чрезвычайно рентабельны при условии наличия достаточной полосы пропускания памяти.[39]
Распределенных вычислений
Распределенный компьютер (также известный как мультипроцессор с распределенной памятью) - это компьютерная система с распределенной памятью, в которой элементы обработки соединены сетью. Распределенные компьютеры обладают высокой масштабируемостью. Условия "параллельные вычисления "," параллельные вычисления "и" распределенные вычисления "во многом пересекаются, и между ними нет четкого различия.[41] Одна и та же система может быть охарактеризована как «параллельная» и «распределенная»; процессоры в типичной распределенной системе работают одновременно, параллельно.[42]
Кластерные вычисления

Кластер - это группа слабосвязанных компьютеров, которые тесно взаимодействуют друг с другом, поэтому в некоторых отношениях их можно рассматривать как единый компьютер.[43] Кластеры состоят из нескольких автономных машин, соединенных сетью. Хотя машины в кластере не обязательно должны быть симметричными, балансировки нагрузки сложнее, если их нет. Самый распространенный тип кластера - это Кластер Беовульф, который представляет собой кластер, реализованный на нескольких идентичных коммерческая готовая продукция компьютеры, подключенные к TCP / IP Ethernet локальная сеть.[44] Технология Беовульф была первоначально разработана Томас Стерлинг и Дональд Беккер. 87% всех Топ500 суперкомпьютеры - это кластеры.[45] Остальные - это массивно-параллельные процессоры, описание которых приводится ниже.
Поскольку системы грид-вычислений (описанные ниже) могут легко справляться с досадно параллельными проблемами, современные кластеры обычно предназначены для решения более сложных проблем - проблем, которые требуют, чтобы узлы чаще делились друг с другом промежуточными результатами. Это требует высокой пропускной способности и, что более важно, низкойзадержка межсетевое соединение. Многие старые и современные суперкомпьютеры используют специализированное высокопроизводительное сетевое оборудование, специально разработанное для кластерных вычислений, такое как сеть Cray Gemini.[46] По состоянию на 2014 год большинство современных суперкомпьютеров используют некоторое стандартное сетевое оборудование, часто Myrinet, InfiniBand, или Гигабитный Ethernet.
Массивно-параллельные вычисления

Процессор с массовым параллелизмом (MPP) - это отдельный компьютер с множеством сетевых процессоров. MPP имеют многие из тех же характеристик, что и кластеры, но MPP имеют специализированные сети межсоединений (тогда как кластеры используют стандартное оборудование для сетей). MPP также имеют тенденцию быть больше, чем кластеры, обычно с «гораздо большим количеством», чем 100 процессоров.[47] В MPP «каждый ЦП содержит свою собственную память и копию операционной системы и приложения. Каждая подсистема взаимодействует с другими через высокоскоростное соединение».[48]
IBM с Синий Джин / L, пятое по скорости суперкомпьютер в мире по июнь 2009 г. TOP500 рейтинг, является MPP.
Грид-вычисления
Грид-вычисления - это наиболее распространенная форма параллельных вычислений. Он использует компьютеры, обменивающиеся данными через Интернет работать над данной проблемой. Из-за низкой пропускной способности и чрезвычайно высокой задержки, доступных в Интернете, распределенные вычисления обычно имеют дело только с смущающе параллельный проблемы. Многие распределенные вычислительные приложения были созданы, из которых SETI @ home и Складной @ дома являются наиболее известными примерами.[49]
Большинство приложений для грид-вычислений используют промежуточное ПО (программное обеспечение, которое находится между операционной системой и приложением для управления сетевыми ресурсами и стандартизации программного интерфейса). Наиболее распространенным промежуточным ПО для распределенных вычислений является Открытая инфраструктура Беркли для сетевых вычислений (BOINC). Часто программное обеспечение распределенных вычислений использует «запасные циклы», выполняя вычисления в то время, когда компьютер простаивает.
Специализированные параллельные компьютеры
В рамках параллельных вычислений существуют специализированные параллельные устройства, которые остаются интересными нишами. В то время как не специфичный для домена, они, как правило, применимы лишь к нескольким классам параллельных задач.
Реконфигурируемые вычисления с программируемыми вентильными матрицами
Реконфигурируемые вычисления это использование программируемая вентильная матрица (FPGA) в качестве сопроцессора для универсального компьютера. ПЛИС - это, по сути, компьютерный чип, который может перепрограммировать себя для данной задачи.
ПЛИС можно программировать с языки описания оборудования такие как VHDL или Verilog. Однако программирование на этих языках может быть утомительным. Несколько поставщиков создали C в HDL языки, которые пытаются имитировать синтаксис и семантику Язык программирования C, с которым знакомо большинство программистов. Наиболее известными языками от C до HDL являются Митрион-С, Импульс C, DIME-C, и Гендель-C. Конкретные подмножества SystemC на основе C ++ также можно использовать для этой цели.
Решение AMD открыть свой Гипертранспорт Технология для сторонних поставщиков стала технологией, обеспечивающей возможность высокопроизводительных реконфигурируемых вычислений.[50] По словам Майкла Р. Д'Амура, главного операционного директора DRC Computer Corporation, "когда мы впервые пришли в AMD, они назвали нас разъем похитители. Теперь они называют нас своими партнерами ».[50]
Универсальные вычисления на графических процессорах (GPGPU)

Универсальные вычисления на графические процессоры (GPGPU) - довольно недавнее направление в исследованиях компьютерной инженерии. Графические процессоры - это сопроцессоры, которые были сильно оптимизированы для компьютерная графика обработка.[51] Обработка компьютерной графики - это область, в которой преобладают параллельные операции с данными, особенно линейная алгебра матрица операции.
Раньше программы GPGPU использовали обычные графические API для выполнения программ. Однако было создано несколько новых языков программирования и платформ для выполнения вычислений общего назначения на графических процессорах с обоими Nvidia и AMD выпуск среды программирования с CUDA и Stream SDK соответственно. Другие языки программирования GPU включают BrookGPU, PeakStream, и RapidMind. Nvidia также выпустила определенные продукты для вычислений в своих Серия Tesla. Технологический консорциум Khronos Group выпустил OpenCL спецификация, которая представляет собой основу для написания программ, которые выполняются на платформах, состоящих из процессоров и графических процессоров. AMD, яблоко, Intel, Nvidia и другие поддерживают OpenCL.
Интегральные схемы для конкретных приложений
Несколько специализированная интегральная схема (ASIC) подходы были разработаны для работы с параллельными приложениями.[52][53][54]
Поскольку ASIC (по определению) специфичен для данного приложения, он может быть полностью оптимизирован для этого приложения. В результате для данного приложения ASIC имеет тенденцию превосходить по производительности компьютер общего назначения. Однако ASIC создаются УФ фотолитография. Этот процесс требует набора масок, который может быть очень дорогим. Набор масок может стоить более миллиона долларов США.[55] (Чем меньше размер транзисторов, необходимых для микросхемы, тем дороже будет маска.) Между тем, производительность вычислений общего назначения со временем увеличивается (как описано Закон Мура ) стремятся свести на нет этот выигрыш всего за одно или два поколения чипов.[50] Высокая начальная стоимость и тенденция к замене универсальных вычислений, основанных на законе Мура, сделали ASIC неприменимыми для большинства приложений параллельных вычислений. Однако некоторые были построены. Одним из примеров является PFLOPS РИКЕН МДГРАП-3 машина, которая использует специальные ASIC для молекулярная динамика моделирование.
Векторные процессоры

Векторный процессор - это ЦП или компьютерная система, которые могут выполнять одну и ту же инструкцию для больших наборов данных. Векторные процессоры имеют операции высокого уровня, которые работают с линейными массивами чисел или векторов. Пример векторной операции: А = B × C, где А, B, и C каждый из 64-элементных векторов 64-битных плавающая точка числа.[56] Они тесно связаны с классификацией SIMD Флинна.[56]
Cray компьютеры прославились своими компьютерами с векторной обработкой в 1970-х и 1980-х годах. Однако векторные процессоры - как ЦП, так и полноценные компьютерные системы - вообще исчезли. Современный наборы команд процессора включать некоторые инструкции по обработке векторных данных, например, с Freescale Semiconductor с AltiVec и Intel с Потоковые расширения SIMD (SSE).
Программного обеспечения
Языки параллельного программирования
Языки параллельного программирования, библиотеки, API, и модели параллельного программирования (такие как алгоритмические скелеты ) были созданы для программирования параллельных компьютеров. Обычно их можно разделить на классы на основе предположений, которые они делают о базовой архитектуре памяти - совместно используемой памяти, распределенной памяти или совместно используемой распределенной памяти. Языки программирования с общей памятью взаимодействуют, манипулируя переменными общей памяти. Распределенная память использует передача сообщений. Потоки POSIX и OpenMP - два наиболее широко используемых API общей памяти, тогда как Интерфейс передачи сообщений (MPI) - это наиболее широко используемый API системы передачи сообщений.[57] Одна концепция, используемая при программировании параллельных программ, - это концепция будущего, где одна часть программы обещает передать требуемые данные другой части программы в какое-то время в будущем.
CAPS антреприза и Pathscale также координируют свои усилия, чтобы гибридное многоядерное параллельное программирование (HMPP) директивы открытого стандарта, называемого OpenHMPP. Модель программирования на основе директив OpenHMPP предлагает синтаксис для эффективной разгрузки вычислений на аппаратных ускорителях и для оптимизации перемещения данных в / из аппаратной памяти. Директивы OpenHMPP описывают удаленный вызов процедур (RPC) на устройстве-ускорителе (например, GPU) или, в более общем смысле, на наборе ядер. Директивы аннотируют C или Фортран коды для описания двух наборов функций: выгрузка процедур (обозначенных кодлетами) на удаленное устройство и оптимизация передачи данных между основной памятью ЦП и памятью ускорителя.
Рост числа потребительских графических процессоров привел к поддержке вычислить ядра, либо в графических API (называемых вычислить шейдеры ) в выделенных API (например, OpenCL ) или в других языковых расширениях.
Автоматическое распараллеливание
Автоматическое распараллеливание последовательной программы компилятор это «святой Грааль» параллельных вычислений, особенно с учетом вышеупомянутого ограничения частоты процессора. Несмотря на десятилетия работы исследователей компиляторов, автоматическое распараллеливание имело лишь ограниченный успех.[58]
Основные языки параллельного программирования остаются либо явно параллельный или (в лучшем случае) частично неявный, в котором программист дает компилятору директивы для распараллеливания. Существует несколько полностью неявных языков параллельного программирования:СИЗАЛ, Параллельный Haskell, SequenceL, Система C (для ПЛИС ), Митрион-С, VHDL, и Verilog.
Контрольные точки приложения
По мере роста сложности компьютерной системы среднее время наработки на отказ обычно уменьшается. Контрольные точки приложения это метод, с помощью которого компьютерная система делает «снимок» приложения - запись всех текущих распределений ресурсов и состояний переменных, сродни дамп ядра -; эту информацию можно использовать для восстановления программы, если компьютер выйдет из строя. Контрольная точка приложения означает, что программа должна перезапускаться только с последней контрольной точки, а не с начала. Хотя контрольная точка дает преимущества в различных ситуациях, она особенно полезна в высокопараллельных системах с большим количеством процессоров, используемых в высокопроизводительные вычисления.[59]
Алгоритмические методы
Поскольку параллельные компьютеры становятся больше и быстрее, мы теперь можем решать проблемы, выполнение которых раньше занимало слишком много времени. Поля столь же разнообразны, как биоинформатика (для сворачивание белка и анализ последовательности ) и экономики (для математические финансы ) воспользовались преимуществами параллельных вычислений. Общие типы проблем в приложениях для параллельных вычислений включают:[60]
- Плотный линейная алгебра
- Разреженная линейная алгебра
- Спектральные методы (например, Быстрое преобразование Кули – Тьюки Фурье )
- Nпроблемы с телом (такие как Моделирование Barnes – Hut )
- структурированная сетка проблемы (такие как Решеточные методы Больцмана )
- Неструктурированная сетка проблемы (например, найденные в анализ методом конечных элементов )
- Метод Монте-Карло
- Комбинационная логика (такие как методы шифрования методом грубой силы )
- Обход графа (такие как алгоритмы сортировки )
- Динамическое программирование
- Ветвь и переплет методы
- Графические модели (например, обнаружение скрытые марковские модели и строительство Байесовские сети )
- Конечный автомат симуляция
Отказоустойчивость
Параллельные вычисления также могут применяться при проектировании отказоустойчивые компьютерные системы, особенно через шаг системы, выполняющие одну и ту же операцию параллельно. Это обеспечивает избыточность в случае отказа одного из компонентов, а также позволяет автоматически обнаружение ошибок и исправление ошибки если результаты отличаются. Эти методы можно использовать для предотвращения единичных сбоев, вызванных временными ошибками.[61] Хотя во встроенных или специализированных системах могут потребоваться дополнительные меры, этот метод может обеспечить экономичный подход для достижения n-модульной избыточности в готовых коммерческих системах.
История

Истоки настоящего (MIMD) параллелизма восходят к Луиджи Федерико Менабреа и его Эскиз Аналитическая машина Изобретенный Чарльз Бэббидж.[63][64][65]
В апреле 1958 года Стэнли Гилл (Ферранти) обсудил параллельное программирование и необходимость ветвления и ожидания.[66] Также в 1958 году исследователи IBM Джон Кок и Дэниел Слотник впервые обсудили использование параллелизма в численных расчетах.[67] Корпорация Берроуз представил D825 в 1962 году, четырехпроцессорный компьютер, который имел доступ к 16 модулям памяти через поперечный переключатель.[68] В 1967 году Амдал и Слотник опубликовали дискуссию о возможности параллельной обработки на конференции Американской федерации обществ обработки информации.[67] Именно во время этих дебатов Закон Амдала был придуман для определения предела ускорения за счет параллелизма.
В 1969 г. Honeywell представил свой первый Мультики system, симметричная многопроцессорная система, способная работать до восьми процессоров параллельно.[67] C.mmp, многопроцессорный проект на Университет Карнеги Меллон в 1970-х годах был одним из первых мультипроцессоров с более чем несколькими процессорами. Первым мультипроцессором с подключением к шине и кэшами отслеживания был Синапс N + 1 в 1984 г.[64]
История параллельных компьютеров SIMD восходит к 1970-м годам. Мотивация первых компьютеров SIMD заключалась в том, чтобы амортизировать задержка ворот процессора устройство управления над несколькими инструкциями.[69] В 1964 году Слотник предложил построить параллельный компьютер для Национальная лаборатория Лоуренса Ливермора.[67] Его дизайн был профинансирован ВВС США, которая была самой ранней попыткой параллельных вычислений SIMD, ИЛЛИАК IV.[67] Ключом к его конструкции был довольно высокий параллелизм, до 256 процессоров, что позволяло машине работать с большими наборами данных в том, что позже будет известно как векторная обработка. Однако ILLIAC IV был назван «самым печально известным суперкомпьютером», потому что проект был завершен только на четверть, но занял 11 лет и стоил почти в четыре раза больше первоначальной оценки.[62] Когда в 1976 году он, наконец, был готов к запуску своего первого реального приложения, он уступил в производительности существующим коммерческим суперкомпьютерам, таким как Крей-1.
Биологический мозг как массивно-параллельный компьютер
В начале 1970-х гг. Лаборатория компьютерных наук и искусственного интеллекта Массачусетского технологического института, Марвин Мински и Сеймур Паперт приступили к разработке Общество разума теория, которая рассматривает биологический мозг как массивно-параллельный компьютер. В 1986 году Минский опубликовал Общество разума, который утверждает, что «разум состоит из множества маленьких агентов, каждый из которых сам по себе лишен разума».[70] Теория пытается объяснить, как то, что мы называем интеллектом, может быть продуктом взаимодействия неразумных частей. Мински говорит, что самый большой источник идей о теории пришел из его работы по созданию машины, которая использует роботизированную руку, видеокамеру и компьютер для сборки детских кубиков.[71]
Подобные модели (которые также рассматривают биологический мозг как массивно-параллельный компьютер, т.е. мозг состоит из группы независимых или полунезависимых агентов) также были описаны:
- Томас Р. Блейксли,[72]
- Майкл С. Газзанига,[73][74]
- Роберт Э. Орнштейн,[75]
- Эрнест Хилгард,[76][77]
- Мичио Каку,[78]
- Георгий Иванович Гурджиев,[79]
- Модель мозга нейрокластера.[80]
Смотрите также
- Многозадачность компьютера
- Параллелизм (информатика)
- Параллельный процессор с адресацией по содержанию
- Список конференций по распределенным вычислениям
- Список важных публикаций по параллельным, параллельным и распределенным вычислениям
- Машина потока данных Манчестера
- Manycore
- Модель параллельного программирования
- Сериализуемость
- Синхронное программирование
- Транспьютер
- Векторная обработка
использованная литература
- ^ Готтлиб, Аллан; Алмаси, Джордж С. (1989). Высокопараллельные вычисления. Редвуд-Сити, Калифорния: Бенджамин / Каммингс. ISBN 978-0-8053-0177-9.
- ^ С.В. Адве и другие. (Ноябрь 2008 г.). «Исследования в области параллельных вычислений в Иллинойсе: повестка дня UPCRC» В архиве 2018-01-11 в Wayback Machine (PDF). Parallel @ Illinois, Университет штата Иллинойс в Урбана-Шампейн. «Основные методы достижения этих преимуществ в производительности - повышение тактовой частоты и более умные, но все более сложные архитектуры - теперь упираются в так называемую стену питания. компьютерная промышленность признал, что повышение производительности в будущем должно в значительной степени происходить за счет увеличения количества процессоров (или ядер) на кристалле, а не за счет ускорения работы одного ядра ".
- ^ Асанович и другие. Старый [общепринятый взгляд]: Власть бесплатна, но транзисторы дорогие. Новое [общепринятое мнение] заключается в том, что мощность стоит дорого, а транзисторы «бесплатны».
- ^ Асанович, Крсте и другие. (18 декабря 2006 г.). "Пейзаж исследований в области параллельных вычислений: взгляд из Беркли" (PDF). Калифорнийский университет в Беркли. Технический отчет № UCB / EECS-2006-183. «Старая [общепринятая мудрость]: повышение тактовой частоты - это основной метод повышения производительности процессора. Новая [общепринятая мудрость]: увеличение параллелизма - это основной метод повышения производительности процессора… Даже представители Intel, компании, обычно связанной с« более высокими тактовыми частотами » Позиция -speed is better »предупредила, что традиционные подходы к максимальному увеличению производительности за счет увеличения тактовой частоты были доведены до предела».
- ^ «Параллелизм - это не параллелизм», Ваза конференция 11 января 2012 г., Роб Пайк (слайды ) (видео )
- ^ «Параллелизм против параллелизма». Haskell Вики.
- ^ Хеннесси, Джон Л.; Паттерсон, Дэвид А.; Ларус, Джеймс Р. (1999). Компьютерная организация и дизайн: аппаратно-программный интерфейс (2-е изд., 3-е изд.). Сан-Франциско: Кауфманн. ISBN 978-1-55860-428-5.
- ^ а б Барни, Блэз. «Введение в параллельные вычисления». Национальная лаборатория Лоуренса Ливермора. Получено 2007-11-09.
- ^ Томас Раубер; Гудула Рюнгер (2013). Параллельное программирование: для многоядерных и кластерных систем. Springer Science & Business Media. п. 1. ISBN 9783642378010.
- ^ Хеннесси, Джон Л .; Паттерсон, Дэвид А. (2002). Компьютерная архитектура / количественный подход (3-е изд.). Сан-Франциско, Калифорния: International Thomson. п. 43. ISBN 978-1-55860-724-8.
- ^ Rabaey, Ян М. (1996). Цифровые интегральные схемы: взгляд на дизайн. Река Аппер Сэдл, Нью-Джерси: Прентис-Холл. п. 235. ISBN 978-0-13-178609-7.
- ^ Флинн, Лори Дж. (8 мая 2004 г.). «Intel прекращает разработку двух новых микропроцессоров». Газета "Нью-Йорк Таймс. Получено 5 июн 2012.
- ^ Томас Раубер; Гудула Рюнгер (2013). Параллельное программирование: для многоядерных и кластерных систем. Springer Science & Business Media. п. 2. ISBN 9783642378010.
- ^ Томас Раубер; Гудула Рюнгер (2013). Параллельное программирование: для многоядерных и кластерных систем. Springer Science & Business Media. п. 3. ISBN 9783642378010.
- ^ Амдал, Джин М. (1967). «Обоснованность однопроцессорного подхода к достижению крупномасштабных вычислительных возможностей». Proceeding AFIPS '67 (Spring) Proceedings of the 18–20 апреля 1967 г., Spring Joint Computer Conference: 483–485. Дои:10.1145/1465482.1465560.
- ^ Брукс, Фредерик П. (1996). Мифический месяц человека: эссе по разработке программного обеспечения (Юбилейное изд., Препр. С корр., 5. [доктор] ред.). Ридинг, Массачусетс [u.a.]: Addison-Wesley. ISBN 978-0-201-83595-3.
- ^ Майкл МакКул; Джеймс Рейндерс; Арка Робисон (2013). Структурированное параллельное программирование: шаблоны для эффективных вычислений. Эльзевир. п. 61.
- ^ Густафсон, Джон Л. (май 1988 г.). «Переоценка закона Амдала». Коммуникации ACM. 31 (5): 532–533. CiteSeerX 10.1.1.509.6892. Дои:10.1145/42411.42415. S2CID 33937392. Архивировано из оригинал на 2007-09-27.
- ^ Бернштейн, А. Дж. (1 октября 1966 г.). «Анализ программ для параллельной обработки». Транзакции IEEE на электронных компьютерах. ИС-15 (5): 757–763. Дои:10.1109 / PGEC.1966.264565.
- ^ Рооста, Сейед Х. (2000). Параллельная обработка и параллельные алгоритмы: теория и вычисления. Нью-Йорк, штат Нью-Йорк [u.a.]: Springer. п. 114. ISBN 978-0-387-98716-3.
- ^ «Процессы и потоки». Сеть разработчиков Microsoft. Корпорация Microsoft 2018. Получено 2018-05-10.
- ^ Краусс, Кирк Дж (2018). «Безопасность потоков для производительности». Разработка для повышения производительности. Получено 2018-05-10.
- ^ Таненбаум, Эндрю С. (2002-02-01). Введение в тупиковые ситуации в операционной системе. Информит. Pearson Education, Информит. Получено 2018-05-10.
- ^ Сесил, Дэвид (2015-11-03). «Внутренняя синхронизация - семафор». Встроенный. AspenCore. Получено 2018-05-10.
- ^ Прешинг, Джефф (2012-06-08). «Введение в программирование без блокировки». Подготовка к программированию. Получено 2018-05-10.
- ^ "Что противоположно" досадно параллельному "?". Переполнение стека. Получено 2018-05-10.
- ^ Шварц, Дэвид (2011-08-15). "Что такое конкуренция потоков?". Переполнение стека. Получено 2018-05-10.
- ^ Куканов, Алексей (2008-03-04). «Почему простой тест может иметь параллельное замедление». Получено 2015-02-15.
- ^ Краусс, Кирк Дж (2018). «Многопоточность для повышения производительности». Разработка для повышения производительности. Получено 2018-05-10.
- ^ Лэмпорт, Лесли (1 сентября 1979 г.). «Как сделать многопроцессорный компьютер, который правильно выполняет многопроцессорные программы». Транзакции IEEE на компьютерах. С-28 (9): 690–691. Дои:10.1109 / TC.1979.1675439. S2CID 5679366.
- ^ Паттерсон и Хеннесси, стр. 748.
- ^ Сингх, Дэвид Каллер; J.P. (1997). Параллельная компьютерная архитектура ([Nachdr.] Ред.). Сан-Франциско: Morgan Kaufmann Publ. п. 15. ISBN 978-1-55860-343-1.
- ^ Culler et al. п. 15.
- ^ Патт, Йельский университет (Апрель 2004 г.). "Микропроцессор через десять лет: каковы проблемы и как мы их решаем? В архиве 2008-04-14 на Wayback Machine (WMV). Выступление заслуженного лектора на Университет Карнеги Меллон. Проверено 7 ноября, 2007.
- ^ Culler et al. п. 124.
- ^ Culler et al. п. 125.
- ^ Самуэль Ларсен; Саман Амарасингхе. "Использование параллелизма на уровне сверхслова с помощью наборов мультимедийных инструкций" (PDF).
- ^ а б Паттерсон и Хеннесси, стр. 713.
- ^ а б Хеннесси и Паттерсон, стр. 549.
- ^ Паттерсон и Хеннесси, стр. 714.
- ^ Гош (2007), п. 10. Кейдар (2008).
- ^ Линч (1996), п. XIX, 1-2. Пелег (2000), п. 1.
- ^ Что такое кластеризация? Компьютерный словарь Webopedia. Проверено 7 ноября, 2007.
- ^ Определение Беовульфа. Журнал ПК. Проверено 7 ноября, 2007.
- ^ «Список статистики | ТОП500 суперкомпьютерных сайтов». www.top500.org. Получено 2018-08-05.
- ^ «Интерконнект» В архиве 2015-01-28 в Wayback Machine.
- ^ Хеннесси и Паттерсон, стр. 537.
- ^ Определение MPP. Журнал ПК. Проверено 7 ноября, 2007.
- ^ Киркпатрик, Скотт (2003). «КОМПЬЮТЕРНАЯ НАУКА: впереди тяжелые времена». Наука. 299 (5607): 668–669. Дои:10.1126 / science.1081623. PMID 12560537. S2CID 60622095.
- ^ а б c Д'Амур, Майкл Р., главный операционный директор, DRC Computer Corporation. «Стандартные реконфигурируемые вычисления». Приглашенный докладчик в Университете Делавэра, 28 февраля 2007 г.
- ^ Богган, Ша'Киа и Дэниел М. Прессел (август 2007 г.). Графические процессоры: новая платформа для вычислений общего назначения В архиве 2016-12-25 на Wayback Machine (PDF). ARL-SR-154, Исследовательская лаборатория армии США. Проверено 7 ноября, 2007.
- ^ Масленников, Олег (2002). «Систематическая генерация исполняемых программ для процессорных элементов в параллельных системах на базе ASIC или FPGA и их преобразование в VHDL-описания блоков управления процессорных элементов». Конспект лекций по информатике, 2328/2002: п. 272.
- ^ Shimokawa, Y .; Fuwa, Y .; Арамаки, Н. (18–21 ноября 1991 г.). «Параллельный нейрокомпьютер ASIC VLSI для большого количества нейронов и скорости миллиардов соединений в секунду». Международная совместная конференция по нейронным сетям. 3: 2162–2167. Дои:10.1109 / IJCNN.1991.170708. ISBN 978-0-7803-0227-3. S2CID 61094111.
- ^ Acken, Kevin P .; Ирвин, Мэри Джейн; Оуэнс, Роберт М. (июль 1998 г.). «Параллельная архитектура ASIC для эффективного кодирования фрактальных изображений». Журнал обработки сигналов СБИС. 19 (2): 97–113. Дои:10.1023 / А: 1008005616596. S2CID 2976028.
- ^ Канг, Эндрю Б. (21 июня 2004 г.) "Обзор проблемы DFM в полупроводниковой промышленности В архиве 2008-01-31 на Wayback Machine. »Калифорнийский университет, Сан-Диего.« Технологии будущего проектирования для производства (DFM) должны снижать затраты на проектирование [невозмещаемые затраты] и напрямую касаться производства [невозмещаемых расходов] - стоимости набора масок и платы датчика, - которые составляет более 1 миллиона долларов на технологическом узле 90 нм и значительно сдерживает инновации в области полупроводников ".
- ^ а б Паттерсон и Хеннесси, стр. 751.
- ^ В Премия Сиднея Фернбаха вручена изобретателю MPI Биллу Гроппу В архиве 2011-07-25 на Wayback Machine называет MPI «доминирующим коммуникационным интерфейсом HPC»
- ^ Шен, Джон Пол; Микко Х. Липасти (2004). Дизайн современного процессора: основы суперскалярных процессоров (1-е изд.). Дубьюк, Айова: Макгроу-Хилл. п. 561. ISBN 978-0-07-057064-1.
Однако святой Грааль таких исследований - автоматическое распараллеливание последовательных программ - еще не материализовался. Хотя было продемонстрировано автоматическое распараллеливание определенных классов алгоритмов, такой успех был в основном ограничен научными и числовыми приложениями с предсказуемым управлением потоком (например, структуры вложенных циклов со статически определенным счетчиком итераций) и статически анализируемыми шаблонами доступа к памяти. (например, обходит большие многомерные массивы данных с плавающей запятой).
- ^ Энциклопедия параллельных вычислений, том 4 Дэвид Падуя, 2011 г. ISBN 0387097651 стр. 265
- ^ Асанович, Крсте и др. (18 декабря 2006 г.). "Пейзаж исследований в области параллельных вычислений: взгляд из Беркли" (PDF). Калифорнийский университет в Беркли. Технический отчет № UCB / EECS-2006-183. См. Таблицу на страницах 17–19.
- ^ Добель Б., Хартиг Х. и Энгель М. (2012) "Поддержка операционной системы для избыточной многопоточности". Труды Десятой Международной конференции ACM по встроенному ПО, 83–92. Дои:10.1145/2380356.2380375
- ^ а б Паттерсон и Хеннесси, стр. 749–50: «Несмотря на успех в продвижении нескольких технологий, полезных в более поздних проектах, ILLIAC IV потерпел неудачу в качестве компьютера. Расходы выросли с 8 миллионов долларов, оцененных в 1966 году, до 31 миллиона долларов к 1972 году, несмотря на строительство только четверть запланированной машины. Это был, пожалуй, самый печально известный суперкомпьютер. Проект стартовал в 1965 году, а первое настоящее приложение было запущено в 1976 году ».
- ^ Менабреа, Л.Ф. (1842). Набросок аналитической машины, изобретенной Чарльзом Бэббиджем. Bibliothèque Universelle de Genève. Проверено 7 ноября 2007 г. Цитата: «когда должна быть выполнена длинная серия идентичных вычислений, например, тех, которые требуются для формирования числовых таблиц, машина может быть задействована так, чтобы выдавать несколько результатов одновременно. , что значительно сократит весь объем процессов ».
- ^ а б Паттерсон и Хеннесси, стр. 753.
- ^ Р. В. Хокни, К. Р. Джесшоп. Параллельные компьютеры 2: Архитектура, программирование и алгоритмы, Том 2. 1988. с. 8 цитата: «Самым ранним упоминанием параллелизма в компьютерном проектировании считается публикация генерала Л. Ф. Менабреа в… 1842 г., озаглавленная Эскиз аналитической машины, изобретенной Чарльзом Бэббиджем".
- ^ «Параллельное программирование», С. Гилл, Компьютерный журнал Vol. 1 # 1, pp2-10, British Computer Society, апрель 1958 г.
- ^ а б c d е Уилсон, Грегори В. (1994). «История развития параллельных вычислений». Технологический университет Вирджинии / Государственный университет Норфолка, интерактивное обучение с помощью цифровой библиотеки в области компьютерных наук. Получено 2008-01-08.
- ^ Анфес, Гри (19 ноября 2001 г.). «Сила параллелизма». Computerworld. Архивировано из оригинал 31 января 2008 г.. Получено 2008-01-08.
- ^ Паттерсон и Хеннесси, стр. 749.
- ^ Минский, Марвин (1986). Общество разума. Нью-Йорк: Саймон и Шустер. стр.17. ISBN 978-0-671-60740-1.
- ^ Минский, Марвин (1986). Общество разума. Нью-Йорк: Саймон и Шустер. стр.29. ISBN 978-0-671-60740-1.
- ^ Блейксли, Томас (1996). За пределами сознательного разума. Раскрытие секретов самости. стр.6–7.
- ^ Газзанига, Майкл; Леду, Джозеф (1978). Интегрированный разум. С. 132–161.
- ^ Газзанига, Майкл (1985). Социальный мозг. Открытие сетей разума. стр.77–79.
- ^ Орнштейн, Роберт (1992). Эволюция сознания: истоки нашего мышления. стр.2.
- ^ Хилгард, Эрнест (1977). Разделенное сознание: множественные элементы управления человеческими мыслями и действиями. Нью-Йорк: Вили. ISBN 978-0-471-39602-4.
- ^ Хилгард, Эрнест (1986). Разделенное сознание: множественные элементы управления человеческими мыслями и действиями (расширенное издание). Нью-Йорк: Вили. ISBN 978-0-471-80572-4.
- ^ Каку, Мичио (2014). Будущее разума.
- ^ Успенский Петр (1992). "Глава 3". В поисках чудесного. Фрагменты неизвестного учения. С. 72–83.
- ^ "Официальный сайт модели мозга нейрокластера". Получено 22 июля, 2017.
дальнейшее чтение
- Rodriguez, C .; Villagra, M .; Баран Б. (29 августа 2008 г.). «Асинхронные командные алгоритмы для логической выполнимости». Биологические модели сетевых, информационных и вычислительных систем, 2007. Бионетика, 2007. 2-е.: 66–69. Дои:10.1109 / BIMNICS.2007.4610083. S2CID 15185219.
- Сечин, А .; Параллельные вычисления в фотограмметрии. GIM International. №1, 2016, с. 21–23.
внешние ссылки
- Обучающие видеоролики по CAF в стандарте Fortran от Джона Рида (см. Приложение B)
- Параллельные вычисления в Керли
- Ливерморская национальная лаборатория Лоуренса: Введение в параллельные вычисления
- Проектирование и создание параллельных программ, Ян Фостер
- Интернет-архив параллельных вычислений
- Тематическая область параллельной обработки в IEEE Distributed Computing Online
- Бесплатная онлайн-книга о параллельных вычислениях
- Границы суперкомпьютеров Бесплатная онлайн-книга по таким темам, как алгоритмы и промышленные приложения
- Универсальный исследовательский центр параллельных вычислений
- Курс параллельного программирования в Колумбийском университете (в сотрудничестве с проектом IBM T.J. Watson X10)
- Вычисление параллельных и распределенных базисов Грёбнера в JAS, смотрите также Основа Грёбнера
- Курс параллельных вычислений в Университете Висконсин-Мэдисон
- Berkeley Par Lab: прогресс в области параллельных вычислений, Редакторы: Дэвид Паттерсон, Деннис Гэннон и Майкл Ринн, 23 августа 2013 г.
- Беда с многоядерностью, Дэвид Паттерсон, опубликовано 30 июня 2010 г.
- Пейзаж исследований в области параллельных вычислений: взгляд из Беркли (слишком много неработающих ссылок на этом сайте)
- Введение в параллельные вычисления
- Coursera: параллельное программирование
| Общее | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Оборудование | |
| API | |
| Проблемы | |
| |