Выравнивание последовательности - Sequence alignment
эта статья нужны дополнительные цитаты для проверка. (Март 2009 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
В биоинформатика, а выравнивание последовательностей это способ организации последовательностей ДНК, РНК, или белок для выявления областей сходства, которые могут быть следствием функциональной структурный, или эволюционный отношения между последовательностями.[1] Выровненные последовательности нуклеотид или аминокислота остатки обычно представлены в виде строк внутри матрица. Между остатки так, чтобы идентичные или похожие символы были выровнены в последовательных столбцах. Выравнивание последовательностей также используется для небиологических последовательностей, таких как вычисление стоимость расстояния между строк в естественный язык или в финансовых данных.

Последовательности аминокислоты для остатков 120-180 белков. Остатки, которые сохраняются во всех последовательностях, выделены серым цветом. Ниже белковых последовательностей находится ключ, обозначающий консервативная последовательность (*), консервативные мутации (:), полуконсервативные мутации (.) и неконсервативные мутации ( ).[2]
Интерпретация
Если две последовательности в выравнивании имеют общего предка, несоответствия можно интерпретировать как точечные мутации и пробелы как инделы (то есть инсерционные или делеционные мутации), введенные в одну или обе линии в то время, когда они расходились друг от друга. При выравнивании последовательностей белков степень сходства между аминокислоты занятие определенной позиции в последовательности можно интерпретировать как грубую меру того, как консервированный конкретный регион или мотив последовательности находится среди родословных. Отсутствие замен или наличие только очень консервативных замен (то есть замена аминокислот, боковые цепи имеют аналогичные биохимические свойства) в определенной области последовательности, предполагают [3] что этот регион имеет структурное или функциональное значение. Хотя ДНК и РНК нуклеотид основания более похожи друг на друга, чем аминокислоты, сохранение пар оснований может указывать на аналогичную функциональную или структурную роль.
Методы совмещения
Очень короткие или очень похожие последовательности можно выровнять вручную. Однако наиболее интересные проблемы требуют выравнивания длинных, сильно вариабельных или чрезвычайно многочисленных последовательностей, которые не могут быть выровнены исключительно усилиями человека. Вместо этого человеческие знания применяются при построении алгоритмов для получения высококачественных выравниваний последовательностей, а иногда и при корректировке окончательных результатов для отражения закономерностей, которые сложно представить алгоритмически (особенно в случае нуклеотидных последовательностей). Вычислительные подходы к выравниванию последовательностей обычно делятся на две категории: глобальные согласования и местные выравнивания. Расчет глобального выравнивания - это форма глобальная оптимизация это «заставляет» выравнивание охватывать всю длину всех последовательностей запроса. Напротив, локальные выравнивания идентифицируют области сходства в длинных последовательностях, которые в целом часто сильно расходятся. Часто предпочтительнее локальное выравнивание, но его бывает труднее вычислить из-за дополнительной проблемы, связанной с идентификацией областей сходства.[4] К задаче выравнивания последовательностей были применены различные вычислительные алгоритмы. К ним относятся медленные, но формально правильные методы, такие как динамическое программирование. К ним также относятся эффективные, эвристические алгоритмы или вероятностный методы, предназначенные для крупномасштабного поиска в базе данных, которые не гарантируют нахождение наилучшего соответствия.
Представления
Ref. : GTCGTAGAATA
Читать: CACGTAG - TA
СИГАРА: 2С5М2Д2М
где:
2S = 2 несовпадения
5M = 5 совпадений
2D = 2 удаления
2M = 2 совпадения
Выравнивания обычно представлены как графически, так и в текстовом формате. Почти во всех представлениях выравнивания последовательностей последовательности записываются в ряды, расположенные так, чтобы выровненные остатки появлялись в последовательных столбцах. В текстовых форматах выровненные столбцы, содержащие одинаковые или похожие символы, обозначаются системой символов сохранения. Как и на изображении выше, звездочка или вертикальная черта используются для обозначения идентичности между двумя столбцами; другие менее распространенные символы включают двоеточие для консервативных замен и точку для полуконсервативных замен. Многие программы визуализации последовательностей также используют цвет для отображения информации о свойствах отдельных элементов последовательности; в последовательностях ДНК и РНК это равносильно присвоению каждому нуклеотиду своего собственного цвета. При выравнивании белков, например, на изображении выше, цвет часто используется для обозначения свойств аминокислот, чтобы помочь в оценке сохранение данной аминокислотной замены. Для нескольких последовательностей последняя строка в каждом столбце часто является консенсусная последовательность определяется раскладом; консенсусная последовательность также часто представляется в графическом формате с логотип последовательности в котором размер каждой буквы нуклеотида или аминокислоты соответствует степени ее сохранения.[5]
Выравнивания последовательностей могут храниться в широком спектре текстовых форматов файлов, многие из которых изначально были разработаны в связи с конкретной программой или реализацией выравнивания. Большинство веб-инструментов позволяют использовать ограниченное количество форматов ввода и вывода, например Формат FASTA и GenBank формат и вывод нелегко редактировать. Доступно несколько программ преобразования, которые предоставляют графический интерфейс и / или интерфейс командной строки.[мертвая ссылка ], такие как READSEQ и EMBOSS. Есть также несколько программных пакетов, которые обеспечивают эту функцию преобразования, например Биопайтон, BioRuby и BioPerl. В Файлы SAM / BAM используйте строковый формат CIGAR (Compact Idiosyncratic Gapped Alignment Report) для представления выравнивания последовательности по ссылке путем кодирования последовательности событий (например, совпадение / несоответствие, вставки, удаления).[6]
Глобальное и локальное выравнивание
Глобальное выравнивание, при котором пытаются выровнять каждый остаток в каждой последовательности, наиболее полезно, когда последовательности в наборе запроса похожи и примерно одинакового размера. (Это не означает, что глобальное выравнивание не может начинаться и / или заканчиваться пробелами.) Общий метод глобального выравнивания - это Алгоритм Нидлмана – Вунша, который основан на динамическом программировании. Локальное выравнивание более полезно для разнородных последовательностей, которые, как предполагается, содержат области сходства или сходные мотивы последовательностей в их более крупном контексте последовательности. В Алгоритм Смита – Уотермана - это общий метод локального выравнивания, основанный на той же схеме динамического программирования, но с дополнительными вариантами начала и конца в любом месте.[4]
Гибридные методы, известные как полуглобальные или «глокальные» (сокращение от gloбал-локал) методы поиска наилучшего возможного частичного выравнивания двух последовательностей (другими словами, комбинация одного или обоих начала и одного или обоих концов, как указано, выровненных). Это может быть особенно полезно, когда нисходящая часть одной последовательности перекрывается с восходящей частью другой последовательности. В этом случае ни глобальное, ни локальное выравнивание не является полностью подходящим: глобальное выравнивание будет пытаться заставить выравнивание выходить за пределы области перекрытия, в то время как локальное выравнивание может не полностью покрывать область перекрытия.[7] Другой случай, когда полезно полуглобальное выравнивание, - это когда одна последовательность короткая (например, последовательность гена), а другая очень длинная (например, последовательность хромосомы). В этом случае короткая последовательность должна быть глобально (полностью) выровнена, но для длинной последовательности желательно только локальное (частичное) выравнивание.
Быстрое распространение генетических данных бросает вызов скорости текущих алгоритмов выравнивания последовательностей ДНК. Существенные потребности в эффективном и точном методе обнаружения вариантов ДНК требуют инновационных подходов для параллельной обработки в реальном времени. Оптические вычисления подходы были предложены в качестве многообещающей альтернативы текущим электрическим реализациям, но их применимость еще предстоит проверить. [1].
Попарное выравнивание
Методы попарного выравнивания последовательностей используются для поиска наиболее подходящих кусочных (локальных или глобальных) выравниваний двух запрашиваемых последовательностей. Попарное выравнивание можно использовать только между двумя последовательностями одновременно, но они эффективны для вычислений и часто используются для методов, не требующих высокой точности (таких как поиск в базе данных последовательностей с высоким сходством с запросом). Три основных метода получения парных выравниваний - это методы точечной матрицы, динамическое программирование и методы слов;[1] однако методы множественного выравнивания последовательностей также позволяют выравнивать пары последовательностей. Хотя у каждого метода есть свои сильные и слабые стороны, все три попарных метода имеют трудности с повторяющимися последовательностями низких значений. информационное содержание - особенно если количество повторов различается в двух выравниваемых последовательностях. Одним из способов количественной оценки полезности данного попарного выравнивания является «максимальное уникальное совпадение» (MUM) или самая длинная подпоследовательность, которая встречается в обеих запросных последовательностях. Более длинные последовательности MUM обычно отражают более близкое родство.
Точечно-матричные методы
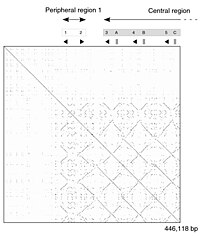 Самостоятельное сравнение части генома линии мыши. Точечный график показывает мозаику линий, демонстрирующих дублированные сегменты ДНК. |
 ДНК точечный график из человек цинковый палец фактор транскрипции (Идентификатор GenBank NM_002383), показывающий региональный самоподобие. Основная диагональ представляет собой выравнивание последовательности с самой собой; линии от главной диагонали представляют собой похожие или повторяющиеся узоры в последовательности. Это типичный пример сюжет повторения. |
Точечно-матричный подход, который неявно производит семейство выравниваний для отдельных участков последовательности, качественно и концептуально прост, хотя и требует времени для анализа в крупном масштабе. В отсутствие шума можно легко визуально идентифицировать определенные особенности последовательности, такие как вставки, удаления, повторы или перевернутые повторы - с точечно-матричного графика. Чтобы построить матричный график, две последовательности записываются в верхней строке и крайнем левом столбце двумерного матрица и точка ставится в любой точке, где совпадают символы в соответствующих столбцах - это типичный сюжет повторения. Некоторые реализации изменяют размер или интенсивность точки в зависимости от степени сходства двух символов, чтобы обеспечить возможность консервативных замен. Точечные графики очень тесно связанных последовательностей будут отображаться в виде одной линии вдоль матрицы. главная диагональ.
Проблемы с точечными графиками как методом отображения информации включают: шум, нечеткость, неинтуитивность, сложность извлечения сводной статистики совпадений и положения совпадений на двух последовательностях. Также существует много бесполезного места, где данные соответствия по своей природе дублируются по диагонали, и большая часть фактической области графика занята либо пустым пространством, либо шумом, и, наконец, точечные графики ограничены двумя последовательностями. Ни одно из этих ограничений не применяется к диаграммам выравнивания Miropeats, но у них есть свои особые недостатки.
Точечные графики также можно использовать для оценки повторяемости в одной последовательности. Последовательность может быть нанесена на график против самой себя, и области, которые имеют существенное сходство, будут отображаться в виде линий от главной диагонали. Этот эффект может возникать, когда белок состоит из нескольких одинаковых структурные области.
Динамическое программирование
Техника динамическое программирование может применяться для глобального выравнивания через Алгоритм Нидлмана-Вунша, и локальные выравнивания через Алгоритм Смита-Уотермана. Обычно при выравнивании белков используется матрица замещения для присвоения баллов совпадениям или несоответствиям аминокислот и штраф за разрыв для сопоставления аминокислоты в одной последовательности с разрывом в другой. Для выравнивания ДНК и РНК можно использовать матрицу оценок, но на практике часто просто присваивают положительную оценку совпадения, отрицательную оценку несоответствия и отрицательный штраф за пропуски. (В стандартном динамическом программировании оценка каждой позиции аминокислоты не зависит от идентичности ее соседей, и, следовательно, базовая укладка эффекты не принимаются во внимание. Тем не менее, можно учесть такие эффекты, изменив алгоритм.) Обычным расширением стандартных затрат линейных разрывов является использование двух различных штрафов за разрыв для открытия разрыва и для увеличения разрыва. Обычно первый намного больше второго, например -10 для открытия промежутка и -2 для расширения промежутка. Таким образом, количество промежутков в выравнивании обычно уменьшается, а остатки и промежутки сохраняются вместе, что обычно имеет более биологический смысл. Алгоритм Гото реализует затраты на аффинный разрыв с помощью трех матриц.
Динамическое программирование может быть полезно при выравнивании нуклеотидных последовательностей с белковыми последовательностями, задача, усложняемая необходимостью учитывать сдвиг рамки мутации (обычно вставки или делеции). Метод поиска по кадрам производит серию глобальных или локальных попарных выравниваний между запрашиваемой нуклеотидной последовательностью и поисковым набором последовательностей белков, или наоборот. Его способность оценивать сдвиг кадров, смещенный произвольным числом нуклеотидов, делает этот метод полезным для последовательностей, содержащих большое количество отступов, которые может быть очень трудно согласовать с более эффективными эвристическими методами. На практике этот метод требует больших вычислительных мощностей или системы, архитектура которой специализирована для динамического программирования. В ВЗРЫВ и EMBOSS наборы предоставляют базовые инструменты для создания транслированных выравниваний (хотя некоторые из этих подходов используют побочные эффекты возможностей поиска последовательности инструментов). Более общие методы доступны из программное обеспечение с открытым исходным кодом такие как GeneWise.
Гарантируется, что метод динамического программирования найдет оптимальное выравнивание с учетом конкретной оценочной функции; однако определение хорошей оценочной функции часто является эмпирическим, а не теоретическим вопросом. Хотя динамическое программирование расширяется до более чем двух последовательностей, оно недопустимо медленное для большого количества последовательностей или очень длинных последовательностей.
Методы Word
Методы Word, также известные как k-корочечные методы, являются эвристический методы, которые не гарантируют найти оптимальное решение для выравнивания, но значительно более эффективны, чем динамическое программирование. Эти методы особенно полезны при крупномасштабном поиске в базе данных, когда понятно, что большая часть последовательностей-кандидатов не будет иметь существенного совпадения с последовательностью запроса. Методы Word наиболее известны своей реализацией в средствах поиска по базам данных. ФАСТА и ВЗРЫВ семья.[1] Методы Word идентифицируют серию коротких неперекрывающихся подпоследовательностей («слов») в последовательности запроса, которые затем сопоставляются с последовательностями базы данных кандидатов. Относительные позиции слова в двух сравниваемых последовательностях вычитаются для получения смещения; это укажет на область выравнивания, если несколько разных слов производят одинаковое смещение. Только если эта область обнаружена, эти методы применяют более чувствительные критерии выравнивания; таким образом, устраняется множество ненужных сравнений с последовательностями, не имеющими заметного сходства.
В методе FASTA пользователь определяет значение k использовать в качестве длины слова для поиска в базе данных. Метод медленнее, но более чувствителен при меньших значениях k, которые также предпочтительны для поиска с очень короткой последовательностью запросов. Семейство методов поиска BLAST предоставляет ряд алгоритмов, оптимизированных для определенных типов запросов, таких как поиск отдаленно связанных совпадений последовательностей. BLAST был разработан, чтобы предоставить более быструю альтернативу FASTA без ущерба для точности; как и FASTA, BLAST использует поиск слова по длине k, но оценивает совпадение только наиболее значимых слов, а не совпадение каждого слова, как это делает FASTA. Большинство реализаций BLAST используют фиксированную длину слова по умолчанию, которая оптимизирована для запроса и типа базы данных и изменяется только при особых обстоятельствах, например, при поиске с повторяющимися или очень короткими последовательностями запросов. Реализации можно найти на нескольких веб-порталах, таких как EMBL FASTA и NCBI BLAST.
Множественное выравнивание последовательностей

Множественное выравнивание последовательностей представляет собой расширение попарного выравнивания, позволяющее одновременно включать более двух последовательностей. Методы множественного выравнивания пытаются выровнять все последовательности в заданном наборе запросов. Множественные выравнивания часто используются для идентификации консервированный области последовательностей в группе последовательностей, предположительно связанных эволюционно. Такие консервативные мотивы последовательностей можно использовать в сочетании со структурными и механистический информация для поиска каталитического активные сайты из ферменты. Выравнивания также используются для помощи в установлении эволюционных отношений путем построения филогенетические деревья. Множественное выравнивание последовательностей сложно произвести с помощью вычислений, и большинство формулировок проблемы приводит к НП-полный комбинаторные задачи оптимизации.[8][9] Тем не менее, использование этих выравниваний в биоинформатике привело к развитию множества методов, подходящих для выравнивания трех или более последовательностей.
Динамическое программирование
Техника динамического программирования теоретически применима к любому количеству последовательностей; однако, поскольку это требует больших вычислительных ресурсов как по времени, так и по объем памяти, он редко используется для более чем трех или четырех последовательностей в его самой простой форме. Этот метод требует построения п-мерный эквивалент матрицы последовательностей, сформированной из двух последовательностей, где п - количество последовательностей в запросе. Стандартное динамическое программирование сначала используется для всех пар запрашиваемых последовательностей, а затем «пространство для выравнивания» заполняется путем рассмотрения возможных совпадений или пробелов в промежуточных положениях, в конечном итоге создавая выравнивание по существу между каждым выравниванием двух последовательностей. Хотя этот метод является дорогостоящим с точки зрения вычислений, его гарантия глобального оптимального решения полезна в случаях, когда необходимо точно выровнять только несколько последовательностей. Один из методов сокращения вычислительных затрат динамического программирования, основанный на «сумме пар» целевая функция, был реализован в MSA пакет программного обеспечения.[10]
Прогрессивные методы
Прогрессивные, иерархические или древовидные методы генерируют множественное выравнивание последовательностей, сначала выравнивая наиболее похожие последовательности, а затем добавляя последовательно менее связанные последовательности или группы к выравниванию до тех пор, пока весь набор запросов не будет включен в решение. Исходное дерево, описывающее родство последовательностей, основано на парных сравнениях, которые могут включать эвристические методы попарного выравнивания, подобные ФАСТА. Результаты прогрессивного выравнивания зависят от выбора «наиболее родственных» последовательностей и, таким образом, могут быть чувствительны к неточностям в начальных парных выравниваниях. Большинство методов прогрессивного множественного выравнивания последовательностей дополнительно взвешивают последовательности в наборе запроса в соответствии с их родством, что снижает вероятность неправильного выбора исходных последовательностей и, таким образом, повышает точность выравнивания.
Множество вариаций Clustal прогрессивная реализация[11][12][13] используются для множественного выравнивания последовательностей, построения филогенетического дерева и в качестве входных данных для предсказание структуры белка. Более медленный, но более точный вариант прогрессивного метода известен как Т-кофе.[14]
Итерационные методы
Итерационные методы пытаются улучшить сильную зависимость от точности начальных попарных выравниваний, что является слабым местом прогрессивных методов. Итерационные методы оптимизируют целевая функция на основе выбранного метода оценки выравнивания путем назначения начального глобального выравнивания, а затем повторного выравнивания подмножеств последовательностей. Повторно выровненные подмножества затем сами выравниваются, чтобы произвести множественное выравнивание последовательностей в следующей итерации. Рассмотрены различные способы выбора подгрупп последовательности и целевой функции.[15]
Поиск мотива
Поиск мотивов, также известный как анализ профиля, создает глобальные множественные выравнивания последовательностей, которые пытаются выровнять короткие консервативные последовательность мотивов среди последовательностей в наборе запроса. Обычно это делается путем построения общего глобального множественного выравнивания последовательностей, после чего консервированный области изолированы и используются для построения набора профильных матриц. Матрица профиля для каждой консервативной области устроена как матрица оценок, но ее частотные подсчеты для каждой аминокислоты или нуклеотида в каждом положении выводятся из распределения признаков консервативной области, а не из более общего эмпирического распределения. Затем матрицы профилей используются для поиска в других последовательностях вхождений мотива, который они характеризуют. В тех случаях, когда оригинал набор данных содержали небольшое количество последовательностей или только очень родственные последовательности, псевдосчета добавляются для нормализации распределения символов, представленных в мотиве.
Методы, вдохновленные информатикой

Разнообразие общих оптимизация Алгоритмы, обычно используемые в информатике, также применялись к проблеме множественного выравнивания последовательностей. Скрытые марковские модели были использованы для получения оценок вероятности для семейства возможных множественных выравниваний последовательностей для данного набора запросов; Хотя ранние методы, основанные на HMM, давали невысокую производительность, более поздние приложения обнаружили их особенно эффективными при обнаружении отдаленно связанных последовательностей, поскольку они менее восприимчивы к шуму, создаваемому консервативными или полуконсервативными заменами.[16] Генетические алгоритмы и имитация отжига также использовались при оптимизации оценок множественного выравнивания последовательностей, о чем судили с помощью функции оценки, такой как метод суммы пар. Более подробную информацию и программные пакеты можно найти в основной статье. множественное выравнивание последовательностей.
В Преобразование Барроуза – Уиллера успешно применяется для быстрого выравнивания короткого чтения в популярных инструментах, таких как Галстук-бабочка и BWA. Увидеть FM-индекс.
Структурное выравнивание
Структурные выравнивания, которые обычно специфичны для последовательностей белков, а иногда и РНК, используют информацию о вторичный и третичная структура молекулы белка или РНК, чтобы помочь в выравнивании последовательностей. Эти методы можно использовать для двух или более последовательностей и обычно дают локальное выравнивание; однако, поскольку они зависят от наличия структурной информации, они могут использоваться только для последовательностей, соответствующие структуры которых известны (обычно через Рентгеновская кристаллография или ЯМР-спектроскопия ). Поскольку структура как белка, так и РНК более консервативна с точки зрения эволюции, чем последовательность,[17] структурное выравнивание может быть более надежным между последовательностями, которые очень отдаленно связаны и которые разошлись настолько широко, что сравнение последовательностей не может надежно обнаружить их сходство.
Структурные выравнивания используются как «золотой стандарт» при оценке выравниваний на основе гомологии. предсказание структуры белка[18] потому что они явно выравнивают области белковой последовательности, которые структурно похожи, а не полагаются исключительно на информацию о последовательности. Однако явно структурное выравнивание нельзя использовать при прогнозировании структуры, потому что по крайней мере одна последовательность в наборе запроса является целью для моделирования, для которой структура неизвестна. Было показано, что при структурном выравнивании между последовательностью-мишенью и последовательностью-матрицей можно получить высокоточные модели последовательности белка-мишени; главный камень преткновения в предсказании структуры на основе гомологии - получение структурно точных выравниваний с учетом только информации о последовательности.[18]
ДАЛИ
Метод DALI, или матрица расстояний выравнивание - это метод на основе фрагментов для построения структурных выравниваний на основе паттернов контактного сходства между последовательными гексапептидами в запрашиваемых последовательностях.[19] Он может генерировать попарные или множественные выравнивания и определять структурных соседей запрашиваемой последовательности в Банк данных белков (PDB). Он был использован для построения ФССП база данных структурного выравнивания (складчатая классификация на основе структурного выравнивания белков или семейств структурно похожих белков). Доступ к веб-серверу DALI можно получить по адресу ДАЛИ и ФССП находится по адресу База данных Дали.
SSAP
SSAP (программа последовательного выравнивания структур) - это метод структурного выравнивания, основанный на динамическом программировании, который использует в качестве точек сравнения векторы атом-атом в пространстве структуры. Он был расширен с момента его первоначального описания, чтобы включить как множественные, так и попарные выравнивания,[20] и был использован при строительстве CATH (Класс, Архитектура, Топология, Гомология) иерархическая классификация белковых складок в базе данных.[21] Доступ к базе данных CATH можно получить по адресу Классификация структуры белка CATH.
Комбинаторное расширение
Метод комбинаторного удлинения структурного выравнивания генерирует попарное структурное выравнивание за счет использования локальной геометрии для выравнивания коротких фрагментов двух анализируемых белков, а затем собирает эти фрагменты в более крупное выравнивание.[22] На основе таких мер, как твердое тело среднеквадратичное расстояние, остаточные расстояния, локальная вторичная структура и окружающие особенности окружающей среды, такие как соседние остатки гидрофобность локальные сопоставления, называемые «выровненными парами фрагментов», генерируются и используются для построения матрицы сходства, представляющей все возможные структурные сопоставления в пределах заранее определенных критериев отсечения. Затем путь от одного состояния структуры белка к другому прослеживается через матрицу путем расширения растущего выравнивания по одному фрагменту за раз. Оптимальный такой путь определяет комбинаторно-расширенное выравнивание. Веб-сервер, реализующий метод и предоставляющий базу данных парных сопоставлений структур в Protein Data Bank, расположен в Комбинаторное расширение интернет сайт.
Филогенетический анализ
Филогенетика и выравнивание последовательностей - тесно связанные области из-за общей необходимости оценки родства последовательностей.[23] Поле филогенетика широко использует выравнивание последовательностей при построении и интерпретации филогенетические деревья, которые используются для классификации эволюционных отношений между гомологичными гены представлен в геномы расходящихся видов. Степень, в которой последовательности в наборе запроса различаются, качественно связана с эволюционным расстоянием последовательностей друг от друга. Грубо говоря, высокая идентичность последовательностей предполагает, что рассматриваемые последовательности имеют сравнительно молодой возраст. самый последний общий предок, в то время как низкая идентичность предполагает, что дивергенция более древняя. Это приближение, отражающее "молекулярные часы "гипотеза о том, что примерно постоянная скорость эволюционных изменений может использоваться для экстраполяции времени, прошедшего с момента первого расхождения двух генов (т. е. слияние время), предполагает, что эффекты мутации и отбор постоянны по всем линиям последовательностей. Следовательно, он не учитывает возможные различия между организмами или видами в скорости Ремонт ДНК или возможная функциональная консервация конкретных областей в последовательности.(В случае нуклеотидных последовательностей гипотеза молекулярных часов в ее самой основной форме также не учитывает разницу в скорости принятия между тихие мутации которые не меняют значения данного кодон и другие мутации, которые приводят к другому аминокислота включается в белок). Более статистически точные методы позволяют варьировать скорость эволюции на каждой ветви филогенетического дерева, тем самым обеспечивая более точные оценки времени слияния генов.
Методы прогрессивного множественного выравнивания по необходимости создают филогенетическое дерево, потому что они включают последовательности в растущее выравнивание в порядке родства. Другие методы, которые объединяют множественные выравнивания последовательностей и филогенетические деревья, сначала оценивают и сортируют деревья, а также вычисляют множественное выравнивание последовательностей из дерева с наивысшей оценкой. Обычно используемые методы построения филогенетического дерева в основном эвристический потому что проблема выбора оптимального дерева, как и проблема выбора оптимального множественного выравнивания последовательностей, является NP-жесткий.[24]
Оценка значимости
Выравнивание последовательностей полезно в биоинформатике для определения сходства последовательностей, создания филогенетических деревьев и разработки моделей гомологии белковых структур. Однако биологическая значимость выравнивания последовательностей не всегда ясна. Часто предполагается, что совпадения отражают степень эволюционных изменений между последовательностями, происходящими от общего предка; однако формально возможно, что конвергентная эволюция может вызывать очевидное сходство между белками, которые эволюционно не связаны, но выполняют аналогичные функции и имеют сходные структуры.
При поиске в базе данных, таком как BLAST, статистические методы могут определять вероятность конкретного выравнивания между последовательностями или участками последовательностей, возникающих случайно, с учетом размера и состава базы данных, в которой выполняется поиск. Эти значения могут значительно различаться в зависимости от области поиска. В частности, вероятность случайного обнаружения данного выравнивания увеличивается, если база данных состоит только из последовательностей того же организма, что и запрашиваемая последовательность. Повторяющиеся последовательности в базе данных или запросе также могут исказить как результаты поиска, так и оценку статистической значимости; BLAST автоматически фильтрует такие повторяющиеся последовательности в запросе, чтобы избежать очевидных совпадений, которые являются статистическими артефактами.
В литературе доступны методы оценки статистической значимости выравниваний последовательностей с разрывом.[23][25][26][27][28][29][30][31]
Оценка достоверности
Статистическая значимость указывает на вероятность того, что выравнивание данного качества могло произойти случайно, но не указывает, насколько данное выравнивание превосходит альтернативные выравнивания тех же последовательностей. Меры достоверности выравнивания указывают на степень, в которой выравнивания с наилучшей оценкой для данной пары последовательностей по существу сходны. В литературе доступны методы оценки достоверности выравнивания для выравнивания последовательностей с разрывом.[32]
Функции подсчета очков
Выбор функции оценки, которая отражает биологические или статистические наблюдения за известными последовательностями, важен для получения хорошего выравнивания. Последовательности белков часто выравнивают с использованием матрицы замещения которые отражают вероятности данной замены символа на символ. Серия матриц, называемая Матрицы PAM (Матрицы принятой точки мутации, первоначально определенные Маргарет Дейхофф и иногда называемые «матрицами Дейхоффа») явно кодируют эволюционные приближения, касающиеся скоростей и вероятностей конкретных аминокислотных мутаций. Еще одна распространенная серия оценочных матриц, известная как BLOSUM (Матрица замещения блоков), кодирует эмпирически полученные вероятности замещения. Варианты обоих типов матриц используются для обнаружения последовательностей с разными уровнями дивергенции, что позволяет пользователям BLAST или FASTA ограничивать поиск более близкими совпадениями или расширять для обнаружения более расходящихся последовательностей. Штрафы за пробелы учитывать введение пробела - на эволюционной модели, вставки или делеции мутации - как в нуклеотидных, так и в белковых последовательностях, и, следовательно, значения штрафа должны быть пропорциональны ожидаемой частоте таких мутаций. Таким образом, качество произведенных выравниваний зависит от качества функции подсчета очков.
Может быть очень полезно и поучительно попробовать одно и то же выравнивание несколько раз с разными вариантами матрицы скоринга и / или значений штрафа за пробелы и сравнить результаты. Области, в которых решение является слабым или неуникальным, часто можно определить, наблюдая, какие области выравнивания устойчивы к изменениям параметров выравнивания.
Другое биологическое использование
Секвенированные РНК, такие как выраженные теги последовательности и полноразмерные мРНК, могут быть согласованы с секвенированным геномом, чтобы найти, где находятся гены, и получить информацию о альтернативное сращивание[33] и Редактирование РНК.[34] Выравнивание последовательностей также является частью сборка генома, где последовательности выравниваются, чтобы найти перекрытие, так что контиги (длинные участки последовательности) могут быть сформированы.[35] Другое использование SNP анализ, при котором последовательности от разных индивидуумов выравниваются, чтобы найти отдельные пары оснований, которые часто отличаются в популяции.[36]
Небиологические применения
Методы, используемые для выравнивания биологических последовательностей, также нашли применение в других областях, в первую очередь в обработка естественного языка и в социальных науках, где Алгоритм Нидлмана-Вунша обычно упоминается как Оптимальное соответствие.[37] Методы, которые генерируют набор элементов, из которых будут выбираться слова в алгоритмах генерации естественного языка, заимствовали множество методов выравнивания последовательностей из биоинформатики для создания лингвистических версий компьютерных математических доказательств.[38] В области историко-сравнительной лингвистика, выравнивание последовательностей было использовано для частичной автоматизации сравнительный метод с помощью которого лингвисты традиционно реконструируют языки.[39] Бизнес-исследования и маркетинговые исследования также применяли несколько методов выравнивания последовательностей для анализа серий покупок с течением времени.[40]
Программного обеспечения
Более полный список доступного программного обеспечения с разбивкой по алгоритму и типу выравнивания доступен по адресу программное обеспечение для выравнивания последовательностей, но общие программные инструменты, используемые для общих задач выравнивания последовательностей, включают ClustalW2[41] и Т-кофе[42] для выравнивания и BLAST[43] и FASTA3x[44] для поиска в базе данных. Коммерческие инструменты, такие как DNASTAR Lasergene, Гениальный, и PatternHunter также доступны. Инструменты, отмеченные как эффективные выравнивание последовательностей перечислены в bio.tools реестр.
Алгоритмы выравнивания и программное обеспечение можно напрямую сравнивать друг с другом, используя стандартизированный набор ориентир ссылаться на множественные выравнивания последовательностей, известные как BAliBASE.[45] Набор данных состоит из структурных выравниваний, которые можно рассматривать как стандарт, с которым сравниваются методы, основанные исключительно на последовательностях. Относительная эффективность многих распространенных методов центровки при решении часто встречающихся проблем центровки сведена в таблицу, а отдельные результаты опубликованы на сайте BAliBASE.[46][47] Исчерпывающий список оценок BAliBASE для многих (в настоящее время 12) различных инструментов выравнивания можно вычислить в программе STRAP.[48]
Смотрите также
- Гомология последовательностей
- Последовательный майнинг
- ВЗРЫВ
- Алгоритм поиска строки
- Анализ последовательности без выравнивания
- UGENE
- Алгоритм Нидлмана – Вунша
использованная литература
- ^ а б c Крепление DM. (2004). Биоинформатика: анализ последовательности и генома (2-е изд.). Пресса лаборатории Колд-Спринг-Харбор: Колд-Спринг-Харбор, Нью-Йорк. ISBN 978-0-87969-608-5.
- ^ "Часто задаваемые вопросы по Clustal # Символы". Clustal. Архивировано из оригинал 24 октября 2016 г.. Получено 8 декабря 2014.
- ^ Ng PC; Хеникофф С (май 2001 г.). «Прогнозирование вредных аминокислотных замен». Genome Res. 11 (5): 863–74. Дои:10.1101 / гр.176601. ЧВК 311071. PMID 11337480.
- ^ а б Поляновский, В. О .; Ройтберг, М. А .; Туманян, В. Г. (2011). «Сравнительный анализ качества глобального алгоритма и локального алгоритма выравнивания двух последовательностей». Алгоритмы молекулярной биологии. 6 (1): 25. Дои:10.1186/1748-7188-6-25. ЧВК 3223492. PMID 22032267. S2CID 2658261.
- ^ Schneider TD; Стивенс Р.М. (1990). «Логотипы последовательностей: новый способ отображения согласованных последовательностей». Нуклеиновые кислоты Res. 18 (20): 6097–6100. Дои:10.1093 / нар / 18.20.6097. ЧВК 332411. PMID 2172928.
- ^ «Выравнивание последовательности / спецификация формата карты» (PDF).
- ^ Брудно М; Malde S; Поляков А; Сделайте CB; Couronne O; Дубчак I; Бацоглу С (2003). «Глокальное выравнивание: поиск перестановок во время выравнивания». Биоинформатика. 19. Дополнение 1 (90001): i54–62. Дои:10.1093 / биоинформатика / btg1005. PMID 12855437.
- ^ Ван Л; Цзян Т. (1994). «О сложности множественного выравнивания последовательностей». J Comput Biol. 1 (4): 337–48. CiteSeerX 10.1.1.408.894. Дои:10.1089 / cmb.1994.1.337. PMID 8790475.
- ^ Элиас, Исаак (2006). «Урегулирование неразрешимости множественного выравнивания». J Comput Biol. 13 (7): 1323–1339. CiteSeerX 10.1.1.6.256. Дои:10.1089 / cmb.2006.13.1323. PMID 17037961.
- ^ Lipman DJ; Альтшул С.Ф .; Kececioglu JD (1989). «Инструмент для множественного выравнивания последовательностей». Proc Natl Acad Sci USA. 86 (12): 4412–5. Bibcode:1989PNAS ... 86.4412L. Дои:10.1073 / pnas.86.12.4412. ЧВК 287279. PMID 2734293.
- ^ Хиггинс Д.Г., Sharp PM (1988). «CLUSTAL: пакет для выполнения множественного выравнивания последовательностей на микрокомпьютере». Ген. 73 (1): 237–44. Дои:10.1016/0378-1119(88)90330-7. PMID 3243435.
- ^ Томпсон JD; Хиггинс Д.Г.; Гибсон Т.Дж. (1994). «CLUSTAL W: повышение чувствительности прогрессивного множественного выравнивания последовательностей за счет взвешивания последовательностей, штрафов за пропуски в зависимости от позиции и выбора весовой матрицы». Нуклеиновые кислоты Res. 22 (22): 4673–80. Дои:10.1093 / nar / 22.22.4673. ЧВК 308517. PMID 7984417.
- ^ Chenna R; Sugawara H; Koike T; Lopez R; Гибсон Т.Дж.; Хиггинс Д.Г.; Томпсон JD. (2003). «Множественное выравнивание последовательностей с помощью программ серии Clustal». Нуклеиновые кислоты Res. 31 (13): 3497–500. Дои:10.1093 / нар / гкг500. ЧВК 168907. PMID 12824352.
- ^ Notredame C; Хиггинс Д.Г.; Херинга Дж. (2000). «T-Coffee: новый метод быстрого и точного выравнивания множественных последовательностей». Дж Мол Биол. 302 (1): 205–17. Дои:10.1006 / jmbi.2000.4042. PMID 10964570. S2CID 10189971.
- ^ Hirosawa M; Totoki Y; Hoshida M; Исикава М. (1995). «Комплексное исследование итерационных алгоритмов множественного выравнивания последовательностей». Comput Appl Biosci. 11 (1): 13–8. Дои:10.1093 / биоинформатика / 11.1.13. PMID 7796270.
- ^ Karplus K; Barrett C; Хьюи Р. (1998). «Скрытые марковские модели для обнаружения удаленных гомологий белков». Биоинформатика. 14 (10): 846–856. Дои:10.1093 / биоинформатика / 14.10.846. PMID 9927713.
- ^ Chothia C; Леск AM. (Апрель 1986 г.). «Связь между расхождением последовательности и структуры в белках». EMBO J. 5 (4): 823–6. Дои:10.1002 / j.1460-2075.1986.tb04288.x. ЧВК 1166865. PMID 3709526.
- ^ а б Zhang Y; Сколник Дж. (2005). «Проблема предсказания структуры белка может быть решена с использованием текущей библиотеки PDB». Proc Natl Acad Sci USA. 102 (4): 1029–34. Bibcode:2005PNAS..102.1029Z. Дои:10.1073 / pnas.0407152101. ЧВК 545829. PMID 15653774.
- ^ Holm L; Сандер С. (1996). «Картографирование белковой вселенной». Наука. 273 (5275): 595–603. Bibcode:1996Sci ... 273..595H. Дои:10.1126 / science.273.5275.595. PMID 8662544. S2CID 7509134.
- ^ Тейлор WR; Флорес ТП; Оренго CA. (1994). «Множественное выравнивание структуры белка». Белковая наука. 3 (10): 1858–70. Дои:10.1002 / pro.5560031025. ЧВК 2142613. PMID 7849601.[постоянная мертвая ссылка ]
- ^ Оренго CA; Michie AD; Джонс С; Jones DT; Swindells MB; Торнтон Дж. М. (1997). «CATH - иерархическая классификация доменных структур белков». Структура. 5 (8): 1093–108. Дои:10.1016 / S0969-2126 (97) 00260-8. PMID 9309224.
- ^ Шиндялов И.Н.; Bourne PE. (1998). «Выравнивание структуры белка путем возрастающего комбинаторного удлинения (CE) оптимального пути». Protein Eng. 11 (9): 739–47. Дои:10.1093 / белок / 11.9.739. PMID 9796821.
- ^ а б Ortet P; Бастьен О. (2010). "Откуда взялась форма распределения оценок выравнивания?". Эволюционная биоинформатика. 6: 159–187. Дои:10.4137 / EBO.S5875. ЧВК 3023300. PMID 21258650.
- ^ Фельзенштейн Дж. (2004). Вывод филогении. Sinauer Associates: Сандерленд, Массачусетс. ISBN 978-0-87893-177-4.
- ^ Альтшул С.Ф .; Гиш В. (1996). Статистика местного выравнивания. Meth.Enz. Методы в энзимологии. 266. С. 460–480. Дои:10.1016 / S0076-6879 (96) 66029-7. ISBN 9780121821678. PMID 8743700.
- ^ Хартманн А.К. (2002). «Выборка редких событий: статистика локальных сопоставлений последовательностей». Phys. Ред. E. 65 (5): 056102. arXiv:cond-mat / 0108201. Bibcode:2002PhRvE..65e6102H. Дои:10.1103 / PhysRevE.65.056102. PMID 12059642. S2CID 193085.
- ^ Ньюберг Л.А. (2008). «Значение выравнивания последовательностей с разрывом». J Comput Biol. 15 (9): 1187–1194. Дои:10.1089 / cmb.2008.0125. ЧВК 2737730. PMID 18973434.
- ^ Эдди СР; Рост, Буркхард (2008). Рост, Буркхард (ред.). «Вероятностная модель локального выравнивания последовательностей, упрощающая оценку статистической значимости». PLOS Comput Biol. 4 (5): e1000069. Bibcode:2008PLSCB ... 4E0069E. Дои:10.1371 / journal.pcbi.1000069. ЧВК 2396288. PMID 18516236. S2CID 15640896.
- ^ Bastien O; Aude JC; Рой С; Marechal E (2004). «Основы массового автоматического попарного выравнивания последовательностей белков: теоретическое значение статистики Z-значения». Биоинформатика. 20 (4): 534–537. Дои:10.1093 / биоинформатика / btg440. PMID 14990449.
- ^ Agrawal A; Хуан X (2011). «Парная статистическая значимость локального выравнивания последовательностей с использованием матриц замещения, специфичных для последовательностей и позиций». IEEE / ACM Transactions по вычислительной биологии и биоинформатике. 8 (1): 194–205. Дои:10.1109 / TCBB.2009.69. PMID 21071807. S2CID 6559731.
- ^ Agrawal A; Брендель В.П .; Хуан X (2008). «Попарная статистическая значимость и эмпирическое определение эффективных штрафов за открытие пробелов для локального выравнивания последовательностей белков». Международный журнал компьютерной биологии и дизайна лекарств. 1 (4): 347–367. Дои:10.1504 / IJCBDD.2008.022207. PMID 20063463. Архивировано из оригинал 28 января 2013 г.
- ^ Ньюберг Л.А.; Лоуренс CE (2009). «Точное вычисление распределений целых чисел с применением для выравнивания последовательностей». J Comput Biol. 16 (1): 1–18. Дои:10.1089 / cmb.2008.0137. ЧВК 2858568. PMID 19119992.
- ^ Ким Н; Ли С. (2008). Биоинформатика обнаружение альтернативного сплайсинга. Методы Мол. Биол. Методы молекулярной биологии ™. 452. С. 179–97. Дои:10.1007/978-1-60327-159-2_9. ISBN 978-1-58829-707-5. PMID 18566765.
- ^ Ли Дж. Б., Леванон Е. Ю., Юн Дж. К. и др. (Май 2009 г.). «Полногеномная идентификация сайтов редактирования РНК человека путем параллельного захвата ДНК и секвенирования». Наука. 324 (5931): 1210–3. Bibcode:2009Sci ... 324.1210L. Дои:10.1126 / наука.1170995. PMID 19478186. S2CID 31148824.
- ^ Blazewicz J, Bryja M, Figlerowicz M, et al. (Июнь 2009 г.). «Сборка всего генома из результатов секвенирования 454 с использованием модифицированной концепции графа ДНК». Comput Biol Chem. 33 (3): 224–30. Дои:10.1016 / j.compbiolchem.2009.04.005. PMID 19477687.
- ^ Duran C; Appleby N; Варды М; Имелфорт М; Эдвардс Д; Бэтли Дж. (Май 2009 г.). «Открытие однонуклеотидного полиморфизма ячменя с помощью autoSNPdb». Plant Biotechnol. J. 7 (4): 326–33. Дои:10.1111 / j.1467-7652.2009.00407.x. PMID 19386041.
- ^ Abbott A .; Цай А. (2000). «Последовательный анализ и методы оптимального сопоставления в социологии, обзоре и перспективах». Социологические методы и исследования. 29 (1): 3–33. Дои:10.1177/0049124100029001001. S2CID 121097811.
- ^ Barzilay R; Ли Л. (2002). «Начальный лексический выбор посредством многопоследовательного выравнивания» (PDF). Труды конференции по эмпирическим методам обработки естественного языка (EMNLP). 10: 164–171. arXiv:cs / 0205065. Bibcode:2002cs ........ 5065B. Дои:10.3115/1118693.1118715. S2CID 7521453.
- ^ Кондрак, Гжегож (2002). «Алгоритмы реконструкции языка» (PDF). Университет Торонто, Онтарио. Архивировано из оригинал (PDF) 17 декабря 2008 г.. Получено 21 января 2007. Цитировать журнал требует
| журнал =(Помогите) - ^ Prinzie A .; Д. Ван ден Поэль (2006). «Включение последовательной информации в традиционные модели классификации с помощью чувствительного к элементу / позиции SAM». Системы поддержки принятия решений. 42 (2): 508–526. Дои:10.1016 / j.dss.2005.02.004. См. Также статью Принци и Ван ден Поэль. Prinzie, A; Ванденпол, Д. (2007). «Прогнозирование последовательностей приобретения бытовой техники: Марков / Марков для анализа дискриминации и выживаемости для моделирования последовательной информации в моделях NPTB». Системы поддержки принятия решений. 44 (1): 28–45. Дои:10.1016 / j.dss.2007.02.008.
- ^ EMBL-EBI. «ClustalW2 <Выравнивание множественных последовательностей
- ^ Т-кофе
- ^ "BLAST: Базовый инструмент поиска местного выравнивания". blast.ncbi.nlm.NIH.gov. Получено 12 июн 2017.
- ^ "UVA FASTA Server". fasta.bioch.Virginia.edu. Получено 12 июн 2017.
- ^ Томпсон JD; Plewniak F; Почта О (1999). «BAliBASE: эталонная база данных по согласованию для оценки нескольких программ по согласованию». Биоинформатика. 15 (1): 87–8. Дои:10.1093 / биоинформатика / 15.1.87. PMID 10068696.
- ^ BAliBASE
- ^ Томпсон JD; Plewniak F; Поч О. (1999). «Комплексное сравнение нескольких программ выравнивания последовательностей». Нуклеиновые кислоты Res. 27 (13): 2682–90. Дои:10.1093 / nar / 27.13.2682. ЧВК 148477. PMID 10373585.
- ^ «Множественное выравнивание последовательностей: планка». 3d-alignment.eu. Получено 12 июн 2017.
внешние ссылки
 СМИ, связанные с Выравнивание последовательности в Wikimedia Commons
СМИ, связанные с Выравнивание последовательности в Wikimedia Commons