UPGMA - UPGMA
UPGMA (невзвешенный парно-групповой метод со средним арифметическим) представляет собой простую агломерацию (снизу вверх) иерархическая кластеризация метод. Метод обычно относят к Сокаль и Michener.[1]
Метод UPGMA аналогичен его взвешенный вариант, WPGMA метод.
Обратите внимание, что невзвешенный член указывает на то, что все расстояния в равной степени влияют на каждое вычисляемое среднее значение, и не относится к математике, с помощью которой оно достигается. Таким образом, простое усреднение в WPGMA дает взвешенный результат, а пропорциональное усреднение в UPGMA дает невзвешенный результат (см. рабочий пример ).[2]
Алгоритм
Алгоритм UPGMA строит корневое дерево (дендрограмма ), который отражает структуру, присутствующую в попарном матрица сходства (или матрица несходства На каждом шаге ближайшие два кластера объединяются в кластер более высокого уровня. Расстояние между любыми двумя кластерами и , каждый размером (т.е., мощность ) и , принимается среднее значение всех расстояний между парами объектов в и в , то есть среднее расстояние между элементами каждого кластера:








Другими словами, на каждом шаге кластеризации обновленное расстояние между объединенными кластерами и новый кластер дается пропорциональным усреднением и расстояния:





Алгоритм UPGMA создает корневые дендрограммы и требует предположения о постоянной скорости, то есть предполагает наличие ультраметрический дерево, в котором расстояния от корня до каждого конца ветки равны. Когда подсказки - это молекулярные данные (т.е., ДНК, РНК и белок ), отобранных одновременно, ультраметричность предположение становится эквивалентным предположению молекулярные часы.
Рабочий пример
Этот рабочий пример основан на JC69 матрица генетических расстояний, вычисленная из 5S рибосомальная РНК выравнивание последовательностей пяти бактерий: Bacillus subtilis (), Bacillus stearothermophilus (), Лактобациллы viridescens (), Ахолеплазма хоть (), и Micrococcus luteus ().[3][4]





Первый шаг
- Первая кластеризация
Предположим, что у нас есть пять элементов и следующая матрица попарных расстояний между ними:


| а | б | c | d | е | |
|---|---|---|---|---|---|
| а | 0 | 17 | 21 | 31 | 23 |
| б | 17 | 0 | 30 | 34 | 21 |
| c | 21 | 30 | 0 | 28 | 39 |
| d | 31 | 34 | 28 | 0 | 43 |
| е | 23 | 21 | 39 | 43 | 0 |
В этом примере это наименьшее значение , поэтому мы соединяем элементы и .

- Оценка длины первой ветви
Позволять обозначим узел, к которому и теперь подключены. Параметр гарантирует, что элементы и равноудалены от . Это соответствует ожиданиям ультраметричность гипотеза. и к тогда имейте длину (см. финальную дендрограмму )



- Первое обновление матрицы расстояний
Затем мы приступаем к обновлению исходной матрицы расстояний в новую матрицу расстояний (см. ниже), уменьшенного в размере на одну строку и один столбец из-за кластеризации с Значения жирным шрифтом в соответствуют новым расстояниям, рассчитанным по усреднение расстояний между каждым элементом первого кластера и каждый из оставшихся элементов:





Значения, выделенные курсивом в не затрагиваются обновлением матрицы, поскольку они соответствуют расстояниям между элементами, не участвующими в первом кластере.
Второй шаг
- Вторая кластеризация
Теперь мы повторяем три предыдущих шага, начиная с новой матрицы расстояний.
| (а, б) | c | d | е | |
|---|---|---|---|---|
| (а, б) | 0 | 25.5 | 32.5 | 22 |
| c | 25.5 | 0 | 28 | 39 |
| d | 32.5 | 28 | 0 | 43 |
| е | 22 | 39 | 43 | 0 |
Здесь, это наименьшее значение , поэтому мы присоединяемся к кластеру и элемент .

- Оценка длины второй ветви
Позволять обозначим узел, к которому и теперь подключены. Из-за ограничения ультраметричности ветви, соединяющиеся или же к , и к равны и имеют следующую длину:


Вычисляем недостающую длину ветки: (увидеть окончательную дендрограмму )

- Обновление матрицы второго расстояния
Затем мы приступаем к обновлению в новую матрицу расстояний (см. ниже), уменьшенного в размере на одну строку и один столбец из-за кластеризации с . Значения, выделенные жирным шрифтом соответствуют новым расстояниям, рассчитанным по пропорциональное усреднение:


Благодаря этому пропорциональному среднему вычисление этого нового расстояния учитывает больший размер кластер (два элемента) относительно (один элемент). По аналогии:

Таким образом, пропорциональное усреднение дает равный вес начальным расстояниям матрицы . Это причина, по которой метод невзвешенныйне по математической процедуре, а по отношению к начальным расстояниям.
Третий шаг
- Третья кластеризация
Мы снова повторяем три предыдущих шага, начиная с обновленной матрицы расстояний. .
| ((а, б), д) | c | d | |
|---|---|---|---|
| ((а, б), д) | 0 | 30 | 36 |
| c | 30 | 0 | 28 |
| d | 36 | 28 | 0 |
Здесь, это наименьшее значение , поэтому мы соединяем элементы и .

- Оценка длины третьей ветви
Позволять обозначим узел, к которому и подключены. и к тогда имейте длину (увидеть окончательную дендрограмму )


- Обновление третьей матрицы расстояний
Необходимо обновить одну запись, имея в виду, что два элемента и каждый имеет вклад в среднее вычисление:


Заключительный этап
Финал матрица:

| ((а, б), д) | (CD) | |
|---|---|---|
| ((а, б), д) | 0 | 33 |
| (CD) | 33 | 0 |
Итак, мы присоединяемся к кластерам и .


Позволять обозначают (корневой) узел, к которому и подключены. и к тогда имейте длины:


Вычисляем две оставшиеся длины ветвей:


Дендрограмма UPGMA
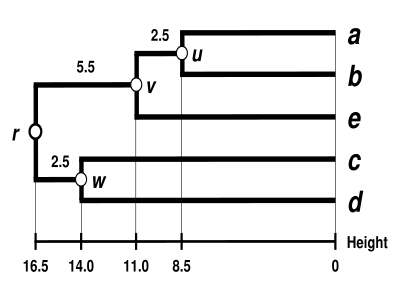
Дендрограмма завершена.[5] Он ультраметрический, потому что все наконечники ( к ) равноудалены от :

Таким образом, дендрограмма основана на , его самый глубокий узел.
Сравнение с другими связями
Альтернативные схемы связи включают однократная кластеризация, полная кластеризация связей, и Кластеризация средних связей WPGMA. Реализация другой связи - это просто вопрос использования другой формулы для расчета межкластерных расстояний на этапах обновления матрицы расстояний в вышеупомянутом алгоритме. Полная кластеризация связей позволяет избежать недостатка альтернативного метода кластеризации одиночных связей - так называемого явление сцепления, где кластеры, сформированные с помощью кластеризации с одной связью, могут быть принудительно объединены из-за того, что отдельные элементы находятся близко друг к другу, даже если многие элементы в каждом кластере могут быть очень удалены друг от друга. Полная связь имеет тенденцию находить компактные группы приблизительно равного диаметра.[6]
 |  |  |  |
| Односвязная кластеризация. | Кластеризация с полной связью. | Кластеризация средней связи: WPGMA. | Средняя кластеризация связей: UPGMA. |
Использует
- В экология, это один из самых популярных методов классификации единиц выборки (например, участков растительности) на основе их попарного сходства в соответствующих переменных дескриптора (таких как видовой состав).[7] Например, его использовали для понимания трофического взаимодействия между морскими бактериями и простейшими.[8]
- В биоинформатика, UPGMA используется для создания фенетический деревья (фенограммы). UPGMA изначально был разработан для использования в электрофорез белков исследований, но в настоящее время наиболее часто используется для создания направляющих деревьев для более сложных алгоритмов. Этот алгоритм, например, используется в выравнивание последовательностей процедур, поскольку он предлагает один порядок, в котором последовательности будут выровнены. Действительно, направляющее дерево нацелено на группировку наиболее похожих последовательностей, независимо от их скорости эволюции или филогенетического сходства, и это как раз и является целью UPGMA.[9]
- В филогенетика, UPGMA предполагает постоянную скорость эволюции (гипотеза молекулярных часов ) и что все последовательности были отобраны одновременно, и это не является хорошо зарекомендовавшим себя методом вывода взаимосвязей, если это предположение не было проверено и обосновано для используемого набора данных. Обратите внимание, что даже в условиях «строгой синхронизации» последовательности, выбранные в разное время, не должны приводить к ультраметрическому дереву.
Сложность времени
Тривиальная реализация алгоритма построения дерева UPGMA имеет временная сложность, а использование кучи для каждого кластера для сохранения расстояния от другого кластера сокращает время до . Фионн Муртаг представил некоторые другие подходы для особых случаев, алгоритм времени Дей и Эдельсбруннер[10] для k-мерных данных, что оптимально для постоянного k, а другой алгоритм для ограниченных входов, когда «агломерационная стратегия удовлетворяет свойству сводимости».[11]




Смотрите также
- Соседство
- Кластерный анализ
- Односвязная кластеризация
- Кластеризация с полной связью
- Иерархическая кластеризация
- Модели эволюции ДНК
- Молекулярные часы
Рекомендации
- ^ Сокаль, Michener (1958). «Статистический метод оценки систематических взаимосвязей». Бюллетень науки Канзасского университета. 38: 1409–1438.
- ^ Гарсия С., Пуигбо П. "DendroUPGMA: Утилита для построения дендрограмм" (PDF). п. 4.
- ^ Эрдманн В.А., Вольтерс Дж. (1986). «Коллекция опубликованных последовательностей рибосомных РНК 5S, 5.8S и 4.5S». Исследования нуклеиновых кислот. 14 Suppl (Suppl): r1–59. Дои:10.1093 / nar / 14.suppl.r1. ЧВК 341310. PMID 2422630.
- ^ Olsen GJ (1988). «Филогенетический анализ с использованием рибосомальной РНК». Методы в энзимологии. 164: 793–812. Дои:10.1016 / с0076-6879 (88) 64084-5. PMID 3241556.
- ^ Swofford DL, Olsen GJ, Waddell PJ, Hillis DM (1996). «Филогенетический вывод». В Hillis DM, Moritz C, Mable BK (ред.). Молекулярная систематика, 2-е издание. Сандерленд, Массачусетс: Синауэр. С. 407–514. ISBN 9780878932825.
- ^ Everitt, B.S .; Ландау, С .; Лиз, М. (2001). Кластерный анализ. 4-е издание. Лондон: Арнольд. п. 62–64.
- ^ Лежандр П, Лежандр Л (1998). Числовая экология. Развитие экологического моделирования. 20 (Второе английское изд.). Амстердам: Эльзевир.
- ^ Васкес-Домингес Э., Касамайор Э.О., Катала П., Лебарон П. (апрель 2005 г.). «Различные морские гетеротрофные нанофлагелляты по-разному влияют на состав обогащенных бактериальных сообществ». Микробная экология. 49 (3): 474–85. Дои:10.1007 / s00248-004-0035-5. JSTOR 25153200. PMID 16003474. S2CID 22300174.
- ^ Уилер Т.Дж., Кечечиоглу Д.Д. (июль 2007 г.). «Множественное выравнивание путем выравнивания выравниваний». Биоинформатика. 23 (13): i559–68. Дои:10.1093 / биоинформатика / btm226. PMID 17646343.
- ^ День WH, Эдельсбруннер Х (1984-12-01). «Эффективные алгоритмы методов агломеративной иерархической кластеризации». Журнал классификации. 1 (1): 7–24. Дои:10.1007 / BF01890115. ISSN 0176-4268. S2CID 121201396.
- ^ Муртаг Ф (1984). «Сложности иерархических алгоритмов кластеризации: современное состояние». Вычислительная статистика ежеквартально. 1: 101–113.
внешняя ссылка
- Реализация алгоритма кластеризации UPGMA на Ruby (AI4R)
- Пример расчета UPGMA с использованием матрицы сходства
- Пример расчета UPGMA с использованием матрицы расстояний
| Соответствующие поля | ||
|---|---|---|
| Базовые концепты | ||
| Методы вывода | ||
| Текущие темы | ||
| Групповые черты | ||
| Типы групп | ||
| Номенклатура | ||
| ||