Полнотекстовый поиск - Full-text search
Было предложено, чтобы эта статья была слился в поиск информации. (Обсуждать) Предлагается с октября 2020 года. |
эта статья нужны дополнительные цитаты для проверка. (Август 2012 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
В поиск текста, полнотекстовый поиск относится к методам поиска одного компьютер -хранится документ или сборник в полнотекстовая база данных. Полнотекстовый поиск отличается от поиска на основе метаданные или на частях оригинальных текстов, представленных в базах данных (таких как заголовки, рефераты, избранные разделы или библиографические ссылки).
В полнотекстовом поиске поисковый движок проверяет все слова в каждом сохраненном документе, поскольку он пытается соответствовать критериям поиска (например, текст, указанный пользователем). Методы полнотекстового поиска стали обычным явлением в Интернете. библиографические базы данных в 1990-е гг.[требуется проверка ] Многие веб-сайты и прикладные программы (например, обработка текста программное обеспечение) обеспечивают возможности полнотекстового поиска. Некоторые поисковые системы, например AltaVista, используют методы полнотекстового поиска, в то время как другие индексируют только часть веб-страниц, проверенных их системами индексации.[1]
Индексирование
При работе с небольшим количеством документов система полнотекстового поиска может напрямую сканировать содержимое документов с каждым запрос, стратегия под названием "последовательное сканирование ". Это то, что некоторые инструменты, такие как grep, делать при поиске.
Однако, когда количество документов для поиска потенциально велико или количество поисковых запросов, которые необходимо выполнить, является значительным, проблема полнотекстового поиска часто разделяется на две задачи: индексирование и поиск. На этапе индексации будет сканироваться текст всех документов и составлен список поисковых запросов (часто называемых показатель, но правильнее называть согласованность ). На этапе поиска при выполнении определенного запроса делается ссылка только на индекс, а не на текст исходных документов.[2]
Индексатор сделает запись в указателе для каждого термина или слова, найденного в документе, и, возможно, отметит их относительное положение в документе. Обычно индексатор игнорирует стоп слова (например, «и»), которые являются общими и недостаточно значимыми, чтобы быть полезными при поиске. Некоторые индексаторы также используют зависящие от языка остановка по индексируемым словам. Например, слова «диски», «управляемые» и «управляемые» будут записаны в указателе под одним концептуальным словом «драйв».
Компромисс между точностью и отзывчивостью
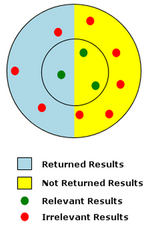
Отзыв измеряет количество релевантных результатов, возвращаемых поиском, а точность - это мера качества возвращаемых результатов. Напоминание - это отношение возвращенных релевантных результатов ко всем релевантным результатам. Точность - это количество возвращенных релевантных результатов по отношению к общему количеству возвращенных результатов.
На диаграмме справа представлен поиск с низкой точностью и быстрым отзывом. На диаграмме красные и зеленые точки представляют общую совокупность потенциальных результатов поиска для данного поиска. Красные точки представляют собой нерелевантные результаты, а зеленые точки - соответствующие результаты. На релевантность указывает близость результатов поиска к центру внутреннего круга. Из всех возможных результатов те, которые действительно были возвращены поиском, показаны на голубом фоне. В этом примере был возвращен только 1 релевантный результат из 3 возможных релевантных результатов, поэтому отзыв является очень низким соотношением 1/3, или 33%. Точность для этого примера составляет очень низкую 1/4 или 25%, так как только 1 из 4 возвращенных результатов был релевантным.[3]
Из-за двусмысленности естественный язык системы полнотекстового поиска обычно включают такие параметры, как стоп слова для повышения точности и остановка чтобы увеличить отзыв. Контролируемая лексика поиск также помогает решить проблемы с низкой точностью, маркировка документы таким образом, чтобы исключить двусмысленность. Компромисс между точностью и отзывом прост: увеличение точности может снизить общий отзыв, в то время как увеличение отзыва снижает точность.[4]
Ложноположительная проблема
Полнотекстовый поиск может найти много документов, которые не соответствующие к предназначена поисковый вопрос. Такие документы называются ложные срабатывания (увидеть Ошибка типа I ). Поиск нерелевантных документов часто вызван присущей им двусмысленностью естественный язык. На схеме справа ложные срабатывания представлены нерелевантными результатами (красные точки), которые были возвращены поиском (на голубом фоне).
Методы кластеризации на основе Байесовский алгоритмы могут помочь уменьшить количество ложных срабатываний. Для поискового слова «банк» кластеризация может использоваться для категоризации вселенной документов / данных на «финансовое учреждение», «место для сидения», «место для хранения» и т. Д. В зависимости от встречаемости слов, относящихся к категориям, условия поиска или результат поиска могут быть помещены в одну или несколько категорий. Этот метод широко применяется в электронное открытие домен.[требуется разъяснение ]
Улучшения производительности
Недостатки свободного поиска по тексту устраняются двумя способами: путем предоставления пользователям инструментов, которые позволяют им более точно выражать свои поисковые вопросы, и путем разработки новых алгоритмов поиска, повышающих точность поиска.
Улучшенные инструменты запросов
- Ключевые слова. Создателей документов (или обученных индексаторов) просят предоставить список слов, описывающих тему текста, включая синонимы слов, описывающих эту тему. Ключевые слова улучшают запоминание, особенно если список ключевых слов включает поисковое слово, которого нет в тексте документа.
- Поиск с ограничением по полю. Некоторые поисковые системы позволяют пользователям ограничивать свободный текстовый поиск определенным поле в пределах сохраненного запись данных, например «Название» или «Автор».
- Логические запросы. Поиски, использующие Булево операторы (например, "энциклопедия" И "онлайн" НЕТ "Энкарта") может значительно повысить точность поиска по произвольному тексту. В И По сути, оператор говорит: «Не извлекайте какой-либо документ, если он не содержит оба этих термина». В НЕТ По сути, оператор говорит: «Не извлекайте документы, содержащие это слово». Если список поиска извлекает слишком мало документов, ИЛИ ЖЕ оператор может использоваться для увеличения отзыв; рассмотрим, например, «энциклопедия» И «онлайн» ИЛИ ЖЕ «Интернет» НЕ «Энкарта». В ходе этого поиска будут найдены документы об онлайн-энциклопедиях, в которых используется термин «Интернет» вместо «онлайн». Такое повышение точности очень часто приводит к обратным результатам, поскольку обычно сопровождается резкой потерей отзыва.[5]
- Поиск по фразе. Поиск по фразе соответствует только тем документам, которые содержат указанную фразу, например "Википедия, свободная энциклопедия."
- Поиск концепции. Поиск, основанный на концепции, состоящей из нескольких слов, например Обработка сложных терминов. Этот тип поиска становится популярным во многих решениях для электронных открытий.
- Поиск соответствия. Поиск соответствия дает алфавитный список всех основных слов, которые встречаются в текст с их непосредственным контекстом.
- Поиск близости. Поиск по фразе находит только те документы, которые содержат два или более слов, разделенных указанным количеством слов; поиск «Википедия» ВНУТРИ2 «бесплатно» будет извлекать только те документы, в которых слова «Википедия» и «бесплатно» встречаются в пределах двух слов друг от друга.
- Регулярное выражение. Регулярное выражение использует сложный, но мощный запрос синтаксис которые можно использовать для точного определения условий поиска.
- Нечеткий поиск будет искать документ, который соответствует заданным условиям и некоторым вариациям вокруг них (например, используя редактировать расстояние для порога множественной вариации)
- Поиск по шаблону. Поиск, который заменяет один или несколько символов в поисковом запросе на подстановочный знак, например звездочка. Например, использование звездочки в поисковом запросе "дерьмо" найдет в тексте «грех», «сын», «солнце» и т. д.
Улучшенные алгоритмы поиска
В PageRank алгоритм, разработанный Google уделяет больше внимания документам, которым другие веб-страница связались.[6] Видеть Поисковый движок для дополнительных примеров.
Программного обеспечения
Ниже приведен неполный список доступных программных продуктов, основная цель которых - выполнять полнотекстовое индексирование и поиск. Некоторые из них сопровождаются подробным описанием их теории работы или внутренних алгоритмов, которые могут дать дополнительную информацию о том, как может выполняться полнотекстовый поиск.
Бесплатное программное обеспечение с открытым исходным кодом
Проприетарное программное обеспечение
- Алголия
- Автономная корпорация
- Поиск в Azure
- Проект Бар Илана Респонса
- Базовая база данных
- Brainware
- BRS / Поиск
- Concept Searching Limited
- Dieselpoint
- dtSearch
- Endeca
- Exalead
- Funnelback
- Быстрый поиск и перевод
- Инктоми
- Locayta (переименован в ATTRAQT в 2014 г.)[нужна цитата ]
- Осознанное воображение
- MarkLogic
- SAP HANA[7]
- Swiftype
- ООО «Тандерстоун Софтвер».
- Вивисимо
Рекомендации
- ^ На практике может быть сложно определить, как работает данная поисковая система. В алгоритмы поиска данные, фактически используемые поисковыми службами, редко раскрываются полностью из-за опасений, что веб-предприниматели будут использовать поисковая оптимизация методы повышения их значимости в поисковых списках.
- ^ «Возможности системы полнотекстового поиска». Архивировано из оригинал 23 декабря 2010 г.
- ^ Коулз, Майкл (2008). Профессиональный полнотекстовый поиск в SQL Server 2008 (Версия 1-е изд.). Издательская Компания Апресс. ISBN 1-4302-1594-1.
- ^ Б., Ювоно; Ли, Д. Л. (1996). Алгоритмы поиска и ранжирования для поиска ресурсов во всемирной паутине. 12-я Международная конференция по инженерии данных (ICDE'96). п. 164.
- ^ Исследования неоднократно показывали, что большинство пользователей не понимают негативного воздействия логических запросов.[1]
- ^ США 6285999, Пейдж, Лоуренс, "Метод ранжирования узлов в связанной базе данных", опубликовано 1998-01-09, выпущено 2001-09-04. «Метод присваивает ранги важности узлам в связанной базе данных, такой как любая база данных документов, содержащих цитаты, всемирная паутина или любая другая база данных гипермедиа. Рейтинг, присвоенный документу, рассчитывается на основе рангов документов, цитирующих его. Кроме того, , ранг документа ... "
- ^ «SAP добавляет программные пакеты на основе HANA в портфель IoT | Советник по MarTech». www.martechadvisor.com.
Смотрите также
- Сопоставление с образцом и соответствие строк
- Обработка сложных терминов
- Корпоративный поиск
- Извлечение информации
- Поиск информации
- Фасетный поиск
- Список поставщиков поисковой системы предприятия
- WebCrawler, первый двигатель FTS
- Индексирование поисковой системой - как поисковые системы генерируют индексы для поддержки полнотекстового поиска