Алгоритм поиска A * - A* search algorithm
| Учебный класс | Алгоритм поиска |
|---|---|
| Структура данных | График |
| Худший случай спектакль | |
| Худший случай космическая сложность |


| График и дерево алгоритмы поиска |
|---|
| Списки |
|
| похожие темы |
А * (произносится как «звезда А») - это обход графа и поиск пути алгоритм, который часто используется во многих областях компьютерных наук из-за его полноты, оптимальности и оптимальной эффективности.[1] Одним из основных практических недостатков является то, что пространственная сложность, так как все сгенерированные узлы хранятся в памяти. Таким образом, на практике системы маршрутизации путешествий, он обычно проигрывает алгоритмам, которые могут предварительно обработать график для достижения лучшей производительности,[2] а также подходы с ограничением памяти; тем не менее, A * по-прежнему остается лучшим решением во многих случаях.[3]

Питер Харт, Нильс Нильссон и Бертрам Рафаэль Стэнфордского исследовательского института (ныне SRI International ) впервые опубликовал алгоритм в 1968 году.[4] Его можно рассматривать как продолжение Эдсгер Дейкстра 1959 алгоритм. A * обеспечивает лучшую производительность за счет использования эвристика чтобы вести его поиск.
История

A * был создан как часть проект Shakey, целью которого было создание мобильного робота, который мог бы планировать свои собственные действия. Нильс Нильссон первоначально предложил использовать алгоритм Graph Traverser[5] для планирования пути Шейки.[6] Graph Traverser руководствуется эвристической функцией час(п), расчетное расстояние от узла п к целевому узлу: он полностью игнорирует грамм(п), расстояние от начального узла до п. Бертрам Рафаэль предложил использовать сумму, грамм(п) + час(п).[6] Питер Харт изобрел концепции, которые мы сейчас называем допустимость и последовательность эвристических функций. Первоначально A * был разработан для поиска путей с наименьшей стоимостью, когда стоимость пути является суммой его затрат, но было показано, что A * может использоваться для поиска оптимальных путей для любой задачи, удовлетворяющей условиям алгебры затрат.[7]
Оригинальная газета A * 1968 года[4] содержала теорему о том, что ни один A * -подобный алгоритм[8] может расширить меньше узлов, чем A *, если эвристическая функция согласована и правильно выбрано правило A *. Через несколько лет была опубликована «поправка».[9] утверждая, что согласованность не требуется, но это было показано в окончательном исследовании Дехтера и Перла оптимальности A * (теперь называемой оптимальной эффективностью), в котором приведен пример A * с допустимой эвристикой, но не последовательным расширением произвольно больше узлов, чем альтернативный A * -подобный алгоритм.[10]
Описание
A * - это алгоритм информированного поиска, или поиск лучшего первого, что означает, что он сформулирован в терминах взвешенные графики: начиная с определенного старта узел графа, он стремится найти путь к заданному целевому узлу с наименьшей стоимостью (наименьшее пройденное расстояние, наименьшее время и т. д.). Он делает это, поддерживая дерево путей, берущих начало в начальном узле и продолжающих эти пути по одному ребру за раз, пока не будет удовлетворен критерий завершения.
На каждой итерации основного цикла A * необходимо определить, какой из его путей нужно продолжить. Это делается на основе стоимости пути и оценки затрат, необходимых для продления пути до цели. В частности, A * выбирает путь, который минимизирует

куда п следующий узел на пути, грамм(п) стоимость пути от начального узла до п, и час(п) это эвристический функция, оценивающая стоимость самого дешевого пути из п к цели. A * завершается, когда путь, который он выбирает для продолжения, является путем от начала до цели или если нет путей, подходящих для расширения. Эвристическая функция зависит от задачи. Если эвристическая функция допустимый, что означает, что он никогда не переоценивает фактическую стоимость достижения цели, A * гарантированно вернет путь с наименьшими затратами от начала до цели.
Типичные реализации A * используют приоритетная очередь выполнить повторный выбор узлов минимальной (оценочной) стоимости для расширения. Эта приоритетная очередь известна как открытый набор или же челка. На каждом шаге алгоритма узел с наименьшим ж(Икс) значение удаляется из очереди, ж и грамм соответственно обновляются значения его соседей, и эти соседи добавляются в очередь. Алгоритм продолжается до удаленного узла (таким образом, узел с наименьшим ж значение из всех периферийных узлов) является целевым узлом.[а] В ж тогда значение этой цели также является стоимостью кратчайшего пути, поскольку час на цели равен нулю в допустимой эвристике.
Описанный алгоритм дает нам только длину кратчайшего пути. Чтобы найти фактическую последовательность шагов, алгоритм можно легко изменить, чтобы каждый узел на пути следил за своим предшественником. После запуска этого алгоритма конечный узел будет указывать на своего предшественника и так далее, пока предшественник какого-либо узла не станет начальным узлом.
Например, при поиске кратчайшего маршрута на карте час(Икс) может представлять расстояние по прямой к цели, поскольку это физически наименьшее возможное расстояние между любыми двумя точками. Для карты сетки из видеоигры с помощью Манхэттенское расстояние или октильное расстояние становится лучше в зависимости от набора доступных движений (4-стороннее или 8-стороннее).
Если эвристический час удовлетворяет дополнительному условию час(Икс) ≤ d(Икс, у) + час(у) для каждого края (Икс, у) графа (где d обозначает длину этого ребра), то час называется монотонный или последовательный. При последовательной эвристике A * гарантированно найдет оптимальный путь без обработки какого-либо узла более одного раза, а A * эквивалентно выполнению Алгоритм Дейкстры с сниженная стоимость d '(Икс, у) = d(Икс, у) + час(у) − час(Икс).
Псевдокод
Следующее псевдокод описывает алгоритм:
функция реконструировать_путь(пришли из, Текущий) total_path := {Текущий} пока Текущий в пришли из.Ключи: Текущий := пришли из[Текущий] total_path.добавить(Текущий) возвращаться total_path// A * находит путь от начала до цели.// h - эвристическая функция. h (n) оценивает стоимость достижения цели от узла n.функция Звезда(Начните, Цель, час) // Набор обнаруженных узлов, которые, возможно, потребуется (повторно) расширить. // Изначально известен только начальный узел. // Обычно это реализуется как min-heap или приоритетная очередь, а не как хэш-набор. openSet := {Начните} // Для узла n cameFrom [n] - это узел, непосредственно предшествующий ему на самом дешевом пути от начала // на данный момент известно. пришли из := ан пустой карта // Для узла n gScore [n] - это стоимость самого дешевого пути от начала до n, известного в настоящее время. gScore := карта с дефолт ценить из бесконечность gScore[Начните] := 0 // Для узла n fScore [n]: = gScore [n] + h (n). fScore [n] представляет наше лучшее предположение относительно // насколько коротким может быть путь от начала до конца, если он проходит через n. fScore := карта с дефолт ценить из бесконечность fScore[Начните] := час(Начните) пока openSet является нет пустой // Эта операция может произойти за O (1) раз, если openSet является min-heap или приоритетной очередью Текущий := то узел в openSet имея то самый низкий fScore[] ценить если Текущий = Цель возвращаться реконструировать_путь(пришли из, Текущий) openSet.Удалять(Текущий) за каждый сосед из Текущий // d (текущий, сосед) - вес ребра от текущего до соседнего // tentative_gScore - это расстояние от начала до соседа через текущий предварительная_ оценка := gScore[Текущий] + d(Текущий, сосед) если предварительная_ оценка < gScore[сосед] // Этот путь к соседу лучше, чем любой предыдущий. Запиши это! пришли из[сосед] := Текущий gScore[сосед] := предварительная_ оценка fScore[сосед] := gScore[сосед] + час(сосед) если сосед нет в openSet openSet.Добавить(сосед) // Открытый набор пуст, но цель так и не была достигнута возвращаться отказЗамечание: В этом псевдокоде, если узел достигнут одним путем, удален из openSet, а затем достигнут более дешевым путем, он будет снова добавлен в openSet. Это важно для гарантии того, что возвращаемый путь является оптимальным, если эвристическая функция допустимый но нет последовательный. Если эвристика согласована, когда узел удаляется из openSet, путь к нему гарантированно будет оптимальным, поэтому тест ‘tentative_gScore Пример алгоритма A * в действии, где узлами являются города, соединенные дорогами, а h (x) - расстояние по прямой до целевой точки: Ключ: зеленый: начало; синий: цель; оранжевый: посетил Алгоритм A * также имеет реальные приложения. В этом примере ребра - это железные дороги, а h (x) - это расстояние по дуге (кратчайшее возможное расстояние по сфере) до цели. Алгоритм ищет путь между Вашингтоном, округ Колумбия, и Лос-Анджелесом. Существует ряд простых оптимизаций или деталей реализации, которые могут существенно повлиять на производительность реализации A *. Первая деталь, которую следует отметить, заключается в том, что способ обработки связей приоритетной очередью может в некоторых ситуациях существенно влиять на производительность. Если связи разорваны, очередь ведет себя как LIFO образом, A * будет вести себя как поиск в глубину среди путей с одинаковой стоимостью (избегая изучения более одного одинаково оптимального решения). Когда в конце поиска требуется путь, обычно для каждого узла сохраняется ссылка на его родителя. В конце поиска эти ссылки можно использовать для восстановления оптимального пути. Если эти ссылки сохраняются, может быть важно, чтобы один и тот же узел не появлялся в очереди приоритетов более одного раза (каждая запись соответствует разному пути к узлу и каждая с разной стоимостью). Стандартный подход здесь - проверить, появляется ли уже добавляемый узел в очереди приоритетов. Если это так, то приоритет и родительские указатели изменяются, чтобы соответствовать пути с более низкой стоимостью. Стандарт двоичная куча очередь на основе приоритета не поддерживает напрямую операцию поиска одного из своих элементов, но может быть дополнена хеш-таблица который сопоставляет элементы с их положением в куче, позволяя выполнять эту операцию с пониженным приоритетом за логарифмическое время. В качестве альтернативы Куча Фибоначчи может выполнять те же операции с пониженным приоритетом в постоянном амортизированное время. Алгоритм Дейкстры, как еще один пример алгоритма поиска с равномерной стоимостью, можно рассматривать как частный случай A *, где для всех Икс.[11][12] Общий поиск в глубину может быть реализовано с использованием A *, учитывая наличие глобального счетчика C инициализирован очень большим значением. Каждый раз, когда мы обрабатываем узел, мы назначаем C всем своим недавно обнаруженным соседям. После каждого отдельного задания мы уменьшаем счетчик C одним. Таким образом, чем раньше обнаружен узел, тем выше его ценить. И алгоритм Дейкстры, и поиск в глубину могут быть реализованы более эффективно без включения значение в каждом узле. На конечных графах с неотрицательными весами ребер A * гарантированно завершается и является полный, т.е. он всегда найдет решение (путь от начала до цели), если оно существует. На бесконечных графах с конечным фактором ветвления и стоимостью ребер, отличными от нуля ( для некоторых фиксированных ), A * гарантированно завершится, только если существует решение. Алгоритм поиска называется допустимый если гарантированно вернется оптимальное решение. Если эвристическая функция, используемая A *, допустимый, то A * допустимо. Интуитивное ″ доказательство ″ этого заключается в следующем: Когда A * завершает свой поиск, он нашел путь от начала до цели, фактическая стоимость которого ниже, чем предполагаемая стоимость любого пути от начала до цели через любой открытый узел (узел ценить). Когда эвристика допустима, эти оценки оптимистичны (не совсем - см. Следующий абзац), поэтому A * может спокойно игнорировать эти узлы, потому что они не могут привести к более дешевому решению, чем то, которое у него уже есть. Другими словами, A * никогда не упускает из виду возможность более дешевого пути от начала до цели и поэтому будет продолжать поиск до тех пор, пока таких возможностей не будет. Фактическое доказательство немного сложнее, потому что не гарантируется, что значения открытых узлов будут оптимистичными, даже если эвристика допустима. Это потому, что оптимальные значения открытых узлов не гарантируются, поэтому сумма не гарантирует оптимизма. Алгоритм A оптимально эффективен по отношению к набору альтернативных алгоритмов Альтс по набору проблем п если для каждой задачи P в п и каждый алгоритм A ′ в Альтс, набор узлов, расширенный A при решении P, является подмножеством (возможно, равным) набора узлов, расширенных A ′ при решении P. Окончательное исследование оптимальной эффективности A * проводится Риной Дехтер и Джудеа Перл.[10]Они рассмотрели множество определений Альтс и п в сочетании с тем, что эвристика A * просто допустима или является одновременно последовательной и допустимой. Наиболее интересный положительный результат, который они доказали, заключается в том, что A * с последовательной эвристикой оптимально эффективен по отношению ко всем допустимым алгоритмам A * -подобного поиска во всех «непатологических» задачах поиска. Грубо говоря, их представление о непатологической проблеме - это то, что мы сейчас подразумеваем под «до разрешения проблем». Этот результат неверен, если эвристика A * допустима, но несовместима. В этом случае Дехтер и Перл показали, что существуют допустимые A * -подобные алгоритмы, которые могут расширять сколь угодно меньшее количество узлов, чем A *, для некоторых непатологических проблем. Оптимальная эффективность - это набор узлов расширено, а не номер расширений узлов (количество итераций основного цикла A *). Когда используемая эвристика допустима, но не согласована, узел может быть расширен на A * много раз, а в худшем случае - экспоненциальное количество раз.[13]В таких обстоятельствах алгоритм Дейкстры мог бы с большим отрывом превзойти A *. Хотя критерий допустимости гарантирует оптимальный путь решения, он также означает, что A * должен исследовать все равнозначные пути, чтобы найти оптимальный путь. Чтобы вычислить приблизительные кратчайшие пути, можно ускорить поиск за счет оптимальности, ослабив критерий допустимости. Часто мы хотим ограничить эту релаксацию, чтобы гарантировать, что путь решения не хуже, чем (1 + ε) умножить на оптимальный путь решения. Эта новая гарантия называется ε-допустимый. Есть ряд ε-допустимые алгоритмы: В временная сложность A * зависит от эвристики. В худшем случае неограниченного пространства поиска количество расширенных узлов равно экспоненциальный в глубине решения (кратчайший путь) d: О(бd), куда б это фактор ветвления (среднее количество преемников на государство).[21] Это предполагает, что целевое состояние вообще существует, и достижимый из начального состояния; если это не так и пространство состояний бесконечно, алгоритм не завершится. Эвристическая функция оказывает большое влияние на практическую производительность поиска A *, поскольку хорошая эвристика позволяет A * отсечь многие из бd узлы, которые расширится неосведомленный поиск. Его качество можно выразить через эффективный фактор ветвления б*, который может быть определен эмпирически для экземпляра проблемы путем измерения количества узлов, созданных расширением, N, и глубина решения, затем решение[22] Хорошая эвристика - это эвристика с низким эффективным фактором ветвления (оптимальное значение б* = 1). Временная сложность многочлен когда область поиска представляет собой дерево, существует одно целевое состояние и эвристическая функция час соответствует следующему условию: куда час* оптимальная эвристика, точная стоимость, чтобы получить от Икс к цели. Другими словами, ошибка час не будет расти быстрее, чем логарифм "совершенной эвристики" час* который возвращает истинное расстояние от Икс к цели.[15][21] В космическая сложность of A * примерно такой же, как и у всех других алгоритмов поиска по графу, поскольку он сохраняет все сгенерированные узлы в памяти.[23] На практике это оказывается самым большим недостатком поиска A *, приводящим к развитию эвристических поисков с ограничением памяти, таких как Итеративное углубление A *, ограниченная память A * и SMA *. A * часто используется для общего Найти путь проблема в приложениях, таких как видеоигры, но изначально была разработана как общий алгоритм обхода графа.[4]Он находит применение в самых разных проблемах, включая проблему разбор с помощью стохастические грамматики в НЛП.[24]Другие случаи включают информационный поиск с онлайн-обучением.[25] Что отличает A * от жадный алгоритм поиска best-first учитывает стоимость / пройденное расстояние, грамм(п), в учетную запись. Некоторые распространенные варианты Алгоритм Дейкстры можно рассматривать как частный случай A *, где эвристический для всех узлов;[11][12] в свою очередь, и Дейкстра, и A * являются частными случаями динамическое программирование.[26]Сама A * является частным случаем обобщения ветвь и переплет.[27] A * также можно адаптировать к двунаправленный поиск алгоритм. Особое внимание следует уделять критерию остановки.[34]
Пример
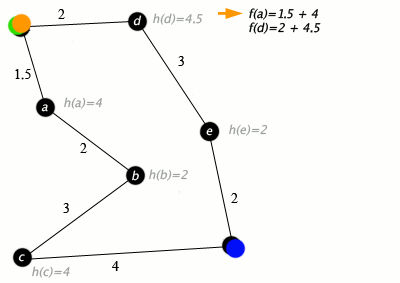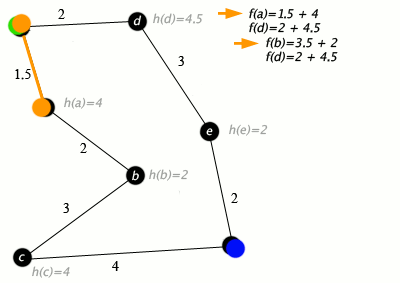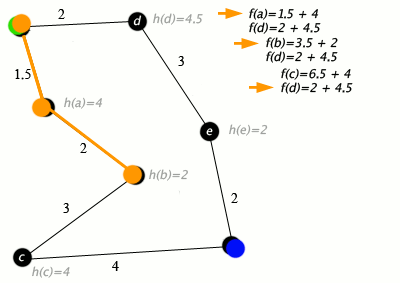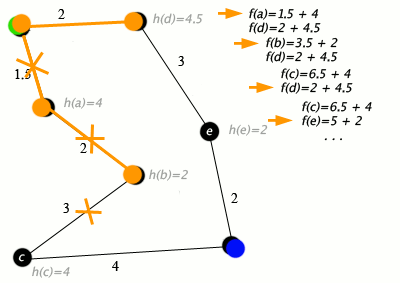

Детали реализации
Особые случаи
Характеристики
Прекращение и завершенность
Допустимость
Оптимальная эффективность
Ограниченное расслабление

Сложность
Приложения
Отношения к другим алгоритмам
Варианты
Смотрите также
Примечания
Рекомендации
| журнал = (помощь)| журнал = (помощь)| журнал = (помощь) из Университет Принстонадальнейшее чтение
внешняя ссылка


















