Упорядочивание памяти - Memory ordering
Упорядочивание памяти описывает порядок доступа ЦП к памяти компьютера. Термин может относиться либо к упорядочиванию памяти, создаваемому компилятор в течение время компиляции, или в порядок памяти, сгенерированный ЦП во время время выполнения.
В современном микропроцессоры, порядок памяти характеризует способность ЦП переупорядочивать операции с памятью - это тип внеочередное исполнение. Переупорядочивание памяти может использоваться для полного использования пропускной способности шины различных типов памяти, таких как тайники и банки памяти.
На большинстве современных однопроцессорных устройств операции с памятью не выполняются в порядке, заданном программным кодом. В однопоточных программах все операции выполняются в указанном порядке, при этом все неупорядоченное выполнение скрыто от программиста - однако в многопоточных средах (или при взаимодействии с другим оборудованием через шины памяти) это может привести к проблемы. Чтобы избежать проблем, барьеры памяти можно использовать в этих случаях.
Упорядочивание памяти во время компиляции
Большинство языков программирования имеют некоторое представление о потоке выполнения, который выполняет операторы в определенном порядке. Традиционные компиляторы преобразуют выражения высокого уровня в последовательность инструкций низкого уровня относительно счетчик команд на уровне базовой машины.
Эффекты выполнения видны на двух уровнях: в программном коде на высоком уровне и на машинном уровне с точки зрения других потоков или элементов обработки в параллельное программирование или во время отладки при использовании аппаратного средства отладки с доступом к состоянию машины (некоторая поддержка для этого часто встроена непосредственно в ЦП или микроконтроллер как функционально независимая схема, кроме ядра выполнения, которое продолжает работать, даже когда само ядро остановлено для статического контроля состояния исполнения). Порядок памяти во время компиляции касается первого и не касается других представлений.
Общие вопросы заказа программы
Эффекты программного порядка оценки выражений
Во время компиляции аппаратные инструкции часто генерируются с более высокой степенью детализации, чем указано в коде высокого уровня. Основной наблюдаемый эффект в процедурное программирование это присвоение нового значения именованной переменной.
сумма = а + б + с; печать (сумма);
Оператор печати следует за оператором, который присваивает переменной sum, и, таким образом, когда оператор печати ссылается на вычисленную переменную сумма он ссылается на этот результат как на наблюдаемый эффект предыдущей последовательности выполнения. В соответствии с правилами выполнения программы, когда Распечатать ссылки на вызовы функций сумма, значение сумма должно быть последним выполненным присвоением переменной сумма (в данном случае непосредственно предыдущее утверждение).
На машинном уровне несколько машин могут сложить три числа в одной инструкции, поэтому компилятору придется преобразовать это выражение в две операции сложения. Если семантика языка программы ограничивает компилятор переводом выражения в порядке слева направо (например), то сгенерированный код будет выглядеть так, как если бы программист написал следующие операторы в исходной программе:
сумма = а + б; сумма = сумма + с;
Если компилятору разрешено использовать ассоциативное свойство кроме того, вместо этого он может генерировать:
сумма = b + c; сумма = а + сумма;
Если компилятору также разрешено использовать коммутативная собственность кроме того, вместо этого он может генерировать:
сумма = а + с; сумма = сумма + b;
Обратите внимание, что целочисленный тип данных в большинстве языков программирования следует только за алгеброй для математических целых чисел при отсутствии целочисленное переполнение и это арифметика с плавающей запятой на тип данных с плавающей запятой, доступный в большинстве языков программирования, не является коммутативным в эффектах округления, что делает эффекты порядка выражения видимыми в небольших различиях вычисленного результата (однако небольшие начальные различия могут каскадно превращаться в произвольно большие различия в течение более длительного вычисления).
Если программист обеспокоен целочисленным переполнением или эффектами округления в числах с плавающей запятой, ту же программу можно закодировать на исходном высоком уровне следующим образом:
сумма = а + б; сумма = сумма + с;
Эффекты программного порядка, включающие вызовы функций
Во многих языках граница оператора рассматривается как точка последовательности, принудительно завершая все эффекты одного оператора перед выполнением следующего оператора. Это заставит компилятор сгенерировать код, соответствующий выраженному порядку операторов. Однако заявления часто бывают более сложными и могут содержать внутренние вызовы функций.
сумма = f (a) + g (b) + h (c);
На машинном уровне вызов функции обычно включает в себя настройку кадр стека для вызова функции, который включает в себя множество операций чтения и записи в машинную память. В большинстве компилируемых языков компилятор может свободно заказывать вызовы функций ж, грамм, и час как он считает удобным, что приводит к масштабным изменениям порядка памяти программ. В функциональном языке программирования вызовам функций запрещено иметь побочные эффекты на видимое состояние программы (кроме возвращаемое значение ), а разница в порядке машинной памяти из-за порядка вызова функций не будет иметь значения для семантики программы. В процедурных языках вызываемые функции могут иметь побочные эффекты, такие как выполнение Операция ввода / вывода или обновление переменной в глобальной области программы, оба из которых производят видимые эффекты с моделью программы.
Опять же, программист, озабоченный этими эффектами, может стать более педантичным в выражении исходной исходной программы:
сумма = f (а); сумма = сумма + g (b); сумма = сумма + h (c);
В языках программирования, где граница оператора определяется как точка последовательности, функция вызывает ж, грамм, и час теперь должны выполняться именно в этом порядке.
Конкретные вопросы порядка памяти
Эффекты порядка программы, включающие выражения указателя
Теперь рассмотрим то же суммирование, выраженное косвенным указателем, на таком языке, как C / C ++, который поддерживает указатели:
сумма = * а + * б + * с;
Оценка выражения *Икс Называется "разыменование "указатель и включает чтение из памяти в месте, указанном текущим значением Икс. Эффекты чтения из указателя определяются архитектурой. модель памяти. При чтении из стандартного хранилища программ отсутствуют побочные эффекты из-за порядка операций чтения из памяти. В Встроенная система программирования, очень часто ввод-вывод с отображением памяти где чтение и запись в память запускают операции ввода-вывода или изменения рабочего режима процессора, которые являются заметными побочными эффектами. Для приведенного выше примера предположим, что указатели указывают на обычную программную память без этих побочных эффектов. Компилятор может переупорядочивать эти чтения в порядке программ по своему усмотрению, и не будет никаких видимых программных побочных эффектов.
Что, если назначенный значение также является косвенным указателем?
* сумма = * а + * б + * с;
Здесь определение языка вряд ли позволит компилятору разбить это на части следующим образом:
// как переписано компилятором // вообще запрещено * sum = * a + * b; * сумма = * сумма + * c;
В большинстве случаев это не будет считаться эффективным, а запись указателя может иметь побочные эффекты на видимое состояние машины. Поскольку компилятор нет разрешил это конкретное преобразование разделения, единственную запись в ячейку памяти сумма должен логически следовать за тремя чтениями указателя в выражении значения.
Предположим, однако, что программист обеспокоен видимой семантикой целочисленного переполнения и разделяет оператор на программный уровень следующим образом:
// написано непосредственно программистом // с проблемами псевдонима * sum = * a + * b; * сумма = * сумма + * c;
Первый оператор кодирует два чтения из памяти, которые должны предшествовать (в любом порядке) первой записи в * сумма. Второй оператор кодирует два чтения памяти (в любом порядке), которые должны предшествовать второму обновлению * сумма. Это гарантирует порядок двух операций сложения, но потенциально создает новую проблему адресации. сглаживание: любой из этих указателей потенциально может относиться к одному и тому же месту в памяти.
Например, предположим в этом примере, что * c и * сумма имеют псевдонимы в одной и той же ячейке памяти, и перепишите обе версии программы с * сумма заменяя обоих.
* сумма = * a + * b + * сумма;
Здесь нет никаких проблем. Исходное значение того, что мы изначально писали как * c теряется при назначении * сумма, как и исходное значение * сумма но это было изначально перезаписано, и это не вызывает особого беспокойства.
// что программа становится с псевдонимами * c и * sum * sum = * a + * b; * сумма = * сумма + * сумма;
Здесь исходное значение * сумма перезаписывается перед первым обращением, и вместо этого мы получаем алгебраический эквивалент:
// алгебраический эквивалент случая с псевдонимом выше * sum = (* a + * b) + (* a + * b);
который присваивает совершенно другое значение * сумма в связи с перестановкой выписки.
Из-за возможных эффектов сглаживания выражения указателя трудно переставить без риска видимых программных эффектов. В общем случае может не быть никакого эффекта сглаживания, поэтому код работает нормально, как и раньше. Но в крайнем случае, когда присутствует наложение, могут возникнуть серьезные программные ошибки. Даже если эти крайние случаи полностью отсутствуют при нормальном выполнении, это открывает дверь злоумышленнику, чтобы изобрести вход, где существует псевдоним, что потенциально может привести к компьютерной безопасности. эксплуатировать.
Безопасный переупорядочивание предыдущей программы выглядит следующим образом:
// объявляем временный локальная переменная 'temp' подходящего типа temp = * a + * b; * сумма = темп + * c;
Наконец, рассмотрим косвенный случай с добавленными вызовами функций:
* сумма = f (* a) + g (* b);
Компилятор может выбрать оценку * а и * б перед вызовом любой функции он может отложить оценку * б до тех пор, пока после вызова функции ж или это может отложить оценку * а до тех пор, пока после вызова функции грамм. Если функция ж и грамм свободны от видимых программных побочных эффектов, все три варианта будут производить программу с одинаковыми видимыми программными эффектами. Если реализация ж или же грамм содержат побочный эффект любой записи указателя, подверженной псевдониму с указателями а или же б, эти три варианта могут привести к различным видимым программным эффектам.
Порядок памяти в спецификации языка
В общем, скомпилированные языки недостаточно подробны в своей спецификации, чтобы компилятор мог формально во время компиляции определить, какие указатели потенциально имеют псевдонимы, а какие нет. Самый безопасный способ действий для компилятора - это предположить, что все указатели потенциально имеют псевдонимы в любое время. Такой уровень консервативного пессимизма, как правило, приводит к ужасным результатам по сравнению с оптимистическим предположением, что никакого псевдонима никогда не существует.
В результате многие компилируемые языки высокого уровня, такие как C / C ++, эволюционировали, чтобы иметь замысловатые и изощренные семантические спецификации относительно того, где компилятору разрешено делать оптимистические предположения при переупорядочении кода в поисках максимально возможной производительности, а где - компилятор должен делать пессимистические предположения при переупорядочении кода, чтобы избежать семантических опасностей.
Безусловно, самый большой класс побочных эффектов в современном процедурном языке связан с операциями записи в память, поэтому правила, касающиеся порядка памяти, являются доминирующим компонентом в определении семантики порядка программ. Переупорядочение вызовов функций выше может показаться другим соображением, но обычно это сводится к проблемам с внутренними эффектами памяти для вызываемых функций, взаимодействующих с операциями с памятью в выражении, которое генерирует вызов функции.
Дополнительные трудности и осложнения
Оптимизация под "как если бы"
Современные компиляторы иногда делают шаг вперед с помощью как если бы правило, в котором разрешено любое переупорядочение (даже между операторами), если оно не влияет на видимые результаты семантики программы. В соответствии с этим правилом порядок операций в переведенном коде может сильно отличаться от указанного в программе. Если компилятору разрешено делать оптимистические предположения о различных выражениях указателей, не имеющих перекрытия псевдонимов в случае, когда такое наложение псевдонимов действительно существует (обычно это классифицируется как плохо сформированная программа), неблагоприятные результаты агрессивного преобразования оптимизации кода будут невозможно угадать до выполнения кода или непосредственной проверки кода. Царство неопределенное поведение имеет почти безграничные проявления.
Программист обязан проконсультироваться со спецификацией языка, чтобы избежать написания некорректных программ, семантика которых потенциально может быть изменена в результате любой законной оптимизации компилятора. Фортран традиционно на программиста возлагается большая нагрузка, поскольку он должен знать об этих проблемах. системное программирование языки C и C ++ не отстают.
Некоторые языки высокого уровня полностью исключают конструкции указателей, так как этот уровень бдительности и внимания к деталям считается слишком высоким, чтобы его можно было надежно поддерживать даже среди профессиональных программистов.
Полное понимание семантики порядка памяти считается загадочной специализацией даже среди подгруппы профессиональных системных программистов, которые обычно лучше всего осведомлены в этой предметной области. Большинство программистов соглашаются на адекватное рабочее понимание этих вопросов в рамках обычной области их знаний в области программирования. На самом краю специализации в семантике порядка памяти находятся программисты, которые создают программные фреймворки в поддержку параллельные вычисления модели.
Псевдонимы локальных переменных
Обратите внимание, что нельзя считать, что локальные переменные свободны от псевдонимов, если указатель на такую переменную ускользает в «дикий»:
сумма = f (& a) + g (a);
Неизвестно, что это за функция ж мог бы сделать с предоставленным указателем на а, включая сохранение копии в глобальном состоянии, которое функция грамм более поздние обращения. В простейшем случае ж записывает новое значение в переменную а, что делает это выражение некорректным в порядке выполнения. ж можно заметно предотвратить это, применив квалификатор const к объявлению аргумента-указателя, что делает выражение хорошо определенным. Таким образом, современная культура C / C ++ стала в некоторой степени одержима предоставлением квалификаторов const для объявлений аргументов функций во всех жизнеспособных случаях.
C и C ++ позволяют использовать внутренние ж к приведение типа атрибут константности как опасное средство. Если ж делает это способом, который может нарушить приведенное выше выражение, он не должен в первую очередь объявлять тип аргумента указателя как const.
Другие языки высокого уровня склоняются к такому атрибуту объявления, составляющему сильную гарантию без лазеек, нарушающих эту гарантию, предоставляемую в самом языке; все ставки на эту языковую гарантию не принимаются, если ваше приложение связывает библиотеку, написанную на другом языке программирования (хотя это считается вопиюще плохим дизайном).
Реализация барьера памяти во время компиляции
Эти барьеры не позволяют компилятору переупорядочивать инструкции во время компиляции - они не препятствуют переупорядочению со стороны ЦП во время выполнения.
- Оператор встроенного ассемблера GNU
asm volatile ("" ::: "память");или даже
__asm__ __volatile__ ("" ::: "память");запрещает GCC компилятор, чтобы изменить порядок чтения и записи команд вокруг него.[1]
- Функция C11 / C ++ 11
atomic_signal_fence (memory_order_acq_rel);
запрещает компилятору переупорядочивать команды чтения и записи вокруг него.[2]
- Компилятор Intel ICC использует "полный забор компилятора"
__memory_barrier ()
- Microsoft Visual C ++ Компилятор:[5]
_ReadWriteBarrier ()
Комбинированные барьеры
Во многих языках программирования различные типы барьеров можно комбинировать с другими операциями (такими как загрузка, сохранение, атомарное приращение, атомарное сравнение и своп), поэтому дополнительный барьер памяти не требуется до или после него (или обоих). В зависимости от целевой архитектуры ЦП эти языковые конструкции будут транслироваться либо в специальные инструкции, либо в несколько инструкций (например, барьер и загрузка), либо в обычные инструкции, в зависимости от гарантий упорядочения памяти оборудования.
Упорядочивание памяти во время выполнения
В микропроцессорных системах с симметричной многопроцессорной обработкой (SMP)
Есть несколько моделей согласованности памяти для SMP системы:
- Последовательная согласованность (все чтения и все записи в порядке)
- Расслабленная последовательность (разрешены некоторые виды переупорядочивания)
- Загрузки могут быть переупорядочены после загрузок (для лучшей работы согласованности кеша, лучшего масштабирования)
- Возможен повторный заказ грузов после складирования
- Магазины могут быть переупорядочены после магазинов
- Возможность повторного заказа магазинов после загрузки
- Слабая согласованность (чтение и запись произвольно переупорядочиваются, ограничиваются только явным барьеры памяти )
На некоторых процессорах
- Атомарные операции можно переупорядочивать вместе с грузами и магазинами.[6]
- Может быть некогерентный конвейер кеширования инструкций, который предотвращает самомодифицирующийся код от выполнения без специальных инструкций по очистке / перезагрузке кеша.
- Зависимые нагрузки могут быть переупорядочены (это уникально для Alpha). Если процессор получает указатель на некоторые данные после этого переупорядочения, он может не получать сами данные, а использовать устаревшие данные, которые он уже кэшировал и еще не аннулировал. Разрешение этого ослабления делает аппаратное кэширование более простым и быстрым, но приводит к необходимости барьеров памяти для читателей и писателей.[7] На оборудовании Alpha (например, многопроцессорном Альфа 21264 systems) сообщения о недействительности строк кэша, отправленные другим процессорам, по умолчанию обрабатываются ленивым способом, если явно не запрашивается обработка между зависимыми загрузками. Спецификация архитектуры Alpha также допускает другие формы переупорядочения зависимых нагрузок, например, с использованием спекулятивного чтения данных до того, как будет известен реальный указатель, который нужно разыменовать.
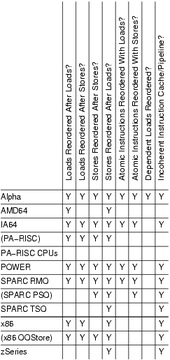
| Тип | Альфа | ARMv7 | MIPS | RISC-V | PA-RISC | МОЩНОСТЬ | SPARC | x86 [а] | AMD64 | IA-64 | z / Архитектура | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ВМО | TSO | RMO | PSO | TSO | ||||||||||
| Заказ грузов может быть изменен после загрузки | Y | Y | зависит от выполнение | Y | Y | Y | Y | Y | ||||||
| Возможен повторный заказ грузов после складирования | Y | Y | Y | Y | Y | Y | Y | |||||||
| Магазины могут быть переупорядочены после магазинов | Y | Y | Y | Y | Y | Y | Y | Y | ||||||
| Возможность повторного заказа магазинов после загрузки | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | |
| Атомик можно переупорядочивать с загрузкой | Y | Y | Y | Y | Y | Y | ||||||||
| Атомик можно переупорядочить в магазинах | Y | Y | Y | Y | Y | Y | Y | |||||||
| Зависимые нагрузки могут быть переупорядочены | Y | |||||||||||||
| Непоследовательный конвейер кеширования инструкций | Y | Y | Y | Y | Y | Y | Y | Y | Y | |||||
Модели заказа памяти RISC-V:
- ВМО
- Порядок слабой памяти (по умолчанию)
- TSO
- Общий заказ магазина (поддерживается только с расширением Ztso)
Режимы упорядочивания памяти SPARC:
- TSO
- Общий заказ магазина (по умолчанию)
- RMO
- Ослабленный порядок памяти (не поддерживается на последних процессорах)
- PSO
- Частичный порядок хранения (не поддерживается на последних процессорах)
Реализация аппаратного барьера памяти
Многие архитектуры с поддержкой SMP имеют специальные аппаратные инструкции для очистки чтения и записи во время время выполнения.
lfence (asm), void _mm_lfence (void) sfence (asm), void _mm_sfence (недействительно)[11]mfence (asm), void _mm_mfence (недействительно)[12]
синхронизация (asm)
синхронизация (asm)
mf (asm)
dcs (asm)
дмб (асм) дсб (асм) исб (асм)
Поддержка компилятором аппаратных барьеров памяти
Некоторые компиляторы поддерживают встроенные которые испускают инструкции аппаратного барьера памяти:
- GCC,[14] версия 4.4.0 и новее,[15] имеет
__sync_synchronize. - Поскольку C11 и C ++ 11
atomic_thread_fence ()команда была добавлена. - В Microsoft Visual C ++ компилятор[16] имеет
MemoryBarrier (). - Компиляторный люкс Sun Studio[17] имеет
__machine_r_barrier,__machine_w_barrierи__machine_rw_barrier.
Смотрите также
Рекомендации
- ^ Компилятор GCC-gcc.h В архиве 2011-07-24 на Wayback Machine
- ^ [1]
- ^ Компилятор ECC-intel.h В архиве 2011-07-24 на Wayback Machine
- ^ Справочник по встроенным функциям компилятора Intel (R) C ++
Создает барьер, через который компилятор не будет планировать инструкции доступа к данным. Компилятор может размещать локальные данные в регистрах через барьер памяти, но не глобальные данные.
- ^ Справочник по языку Visual C ++ _ReadWriteBarrier
- ^ Виктор Алессандрини, 2015. Программирование приложений с общей памятью: концепции и стратегии в программировании многоядерных приложений. Elsevier Science. п. 176. ISBN 978-0-12-803820-8.
- ^ Переупорядочивание на процессоре Alpha, Курош Гарачорлоо
- ^ Упорядочивание памяти в современных микропроцессорах Пол МакКенни
- ^ Барьеры памяти: взгляд на оборудование для программных хакеров, Рисунок 5 на странице 16
- ^ Таблица 1. Сводная информация о порядке памяти, из "Упорядочивание памяти в современных микропроцессорах, часть I"
- ^ SFENCE - Ограждение магазина
- ^ MFENCE - Забор памяти
- ^ Барьер памяти данных, барьер синхронизации данных и барьер синхронизации инструкций.
- ^ Атомарные встроенные конструкции
- ^ "36793 - x86-64 не получает права __sync_synchronize".
- ^ Макрос MemoryBarrier
- ^ Обработка упорядочения памяти в многопоточных приложениях с помощью Oracle Solaris Studio 12, обновление 2: часть 2, барьеры памяти и ограждение памяти [2]
{kind=link}
дальнейшее чтение
- Компьютерная архитектура - количественный подход. 4-е издание. Дж. Хеннесси, Д. Паттерсон, 2007. Глава 4.6.
- Сарита В. Адве, Курош Гарачорлоо, Модели согласованности общей памяти: Учебное пособие
- Информационный документ по заказу памяти для архитектуры Intel 64
- Порядок памяти в современных микропроцессорах, часть 1
- Порядок памяти в современных микропроцессорах, часть 2
- IA (архитектура Intel) Заказ памяти на YouTube - Google Tech Talk