Связывание сущностей - Entity linking
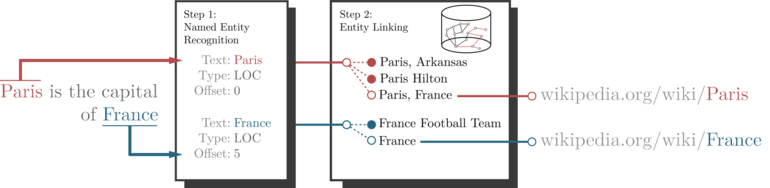
В обработка естественного языка, соединение сущностей, также называемый связывание именованных сущностей (NEL),[1] неоднозначность именованного объекта (NED), распознавание именованных сущностей и устранение неоднозначности (NERD) или нормализация именованных сущностей (NEN)[2] это задача присвоения уникальной идентичности сущностям (таким как известные люди, места или компании), упомянутым в тексте. Например, учитывая предложение "Париж - столица Франции", идея состоит в том, чтобы определить, что "Париж" относится к городу Париж а не Пэрис Хилтон или любой другой субъект, который можно назвать "Париж". Связывание сущностей отличается от признание именного объекта (NER) в этом NER идентифицирует появление именованного объекта в тексте, но не определяет, какой именно объект он представляет (см. Отличия от других техник ).

Вступление
При связывании объектов интересующие слова (имена людей, местоположения и компании) сопоставляются из входящего текста с соответствующими уникальными объектами в целевом объекте. база знаний. Слова интереса называются названные объекты (NE), упоминания или поверхностные формы. Целевая база знаний зависит от предполагаемого приложения, но для систем связывания сущностей, предназначенных для работы с текстом в открытой области, обычно используются базы знаний, полученные из Википедия (Такие как Викиданные или же DBpedia ).[2][3] В этом случае каждая отдельная страница Википедии рассматривается как отдельный объект. Методы связывания сущностей, которые сопоставляют именованные сущности с сущностями Википедии, также называются викификация.[4]
Рассматривая снова пример предложения "Париж - столица Франции", ожидаемый результат системы связывания сущностей будет Париж и Франция. Эти единые указатели ресурсов (URL-адреса) могут использоваться как уникальные унифицированные идентификаторы ресурсов (URI) для сущностей в базе знаний. Использование другой базы знаний вернет разные URI, но для баз знаний, созданных на основе Википедии, существует однозначное сопоставление URI.[5]
В большинстве случаев базы знаний создаются вручную,[6] но в приложениях, где большой текстовые корпуса доступны, база знаний может быть выведена автоматически из доступный текст.[7]
Связывание сущностей - важный шаг для соединения веб-данных с базами знаний, что полезно для аннотирования огромного количества необработанных и часто зашумленных данных в сети и способствует видению Семантическая сеть.[8] Помимо связывания сущностей, есть другие важные шаги, включая, помимо прочего, извлечение событий,[9] и связывание событий[10] и Т. Д.
Приложения
Связывание сущностей полезно в полях, которым необходимо извлекать абстрактные представления из текста, как это происходит при анализе текста, рекомендательные системы, семантический поиск и чат-боты. Во всех этих полях понятия, относящиеся к приложению, отделены от текста и других не значимых данных.[11][12]
Например, обычная задача, которую выполняет поисковые системы заключается в том, чтобы найти документы, похожие на тот, что указан в качестве входных данных, или найти дополнительную информацию о лицах, упомянутых в нем. Рассмотрим предложение, содержащее выражение «столица Франции»: без привязки сущностей поисковая система, просматривающая содержимое документов, не сможет напрямую получить документы, содержащие слово "Париж", что приводит к так называемым ложные отрицания (FN). Хуже того, поисковая система может выдавать ложные совпадения (или ложные срабатывания (FP)), например, поиск документов, относящихся к "Франция" как страна.
Существует множество подходов, ортогональных связыванию сущностей, для извлечения документов, подобных входному документу. Например, латентно-семантический анализ (LSA) или сравнение вложений документов, полученных сdoc2vec. Однако эти методы не позволяют использовать такой же детальный контроль, который предлагается при связывании сущностей, поскольку они будут возвращать другие документы вместо создания высокоуровневых представлений исходного документа. Например, получение схематической информации о "Париж", как представлено в Википедии инфобоксы будет гораздо менее простым, а иногда и невозможным, в зависимости от сложности запроса.[13]
Более того, связывание сущностей было использовано для повышения производительности поиск информации системы[2] и для повышения эффективности поиска в электронных библиотеках.[14] Связывание сущностей также является ключевым фактором для семантический поиск.[15]
Проблемы при связывании сущностей
Система связывания сущностей должна решить ряд проблем, прежде чем будет работать в реальных приложениях. Некоторые из этих проблем являются неотъемлемой частью задачи связывания сущностей,[16] такие как неоднозначность текста, в то время как другие, такие как масштабируемость и время выполнения, становятся важными при рассмотрении использования таких систем в реальной жизни.
- Варианты имени: тот же объект может отображаться с текстовыми представлениями. Источники этих вариаций включают сокращения (Нью-Йорк, Нью-Йорк), псевдонимы (Нью-Йорк, Большое яблоко) или варианты написания и ошибки (Нью йокр).
- Двусмысленность: одно и то же упоминание может часто относиться ко многим различным объектам, в зависимости от контекста, поскольку многие имена объектов, как правило, многозначный (т.е. иметь несколько значений). Слово Париж, среди прочего, может относиться к Французская столица или чтобы Пэрис Хилтон. В некоторых случаях (как в столица Франции) отсутствует текстовое сходство между текстом упоминания и фактическим целевым объектом (Париж).
- Отсутствие: иногда некоторые именованные сущности могут не иметь правильной ссылки на сущность в целевой базе знаний. Это может произойти при работе с очень специфическими или необычными объектами или при обработке документов о недавних событиях, в которых могут быть упоминания лиц или событий, для которых еще нет соответствующей сущности в базе знаний. Другая распространенная ситуация, в которой отсутствуют объекты, - это использование баз знаний для конкретной предметной области (например, базы знаний по биологии или базы данных фильмов). Во всех этих случаях система связывания сущностей должна возвращать
Нольссылка на объект. Понимание, когда вернутьНольпредсказание не является простым, и было предложено много разных подходов; например, установив порог некоторой степени достоверности в системе связывания сущностей, или добавив дополнительныйНольобъект в базу знаний, которая обрабатывается так же, как и другие объекты. Более того, в некоторых случаях предоставление неверного, но связанного предсказания связи объектов может быть лучше, чем полное отсутствие результата с точки зрения конечного пользователя.[16]
- Масштабируемость и скорость: желательно, чтобы система связывания промышленных объектов предоставляла результаты в разумные сроки, а часто и в режиме реального времени. Это требование критически важно для поисковых систем, чат-ботов и систем связывания сущностей, предлагаемых платформами анализа данных. Обеспечение малого времени выполнения может быть сложной задачей при использовании больших баз знаний или при обработке больших документов.[17] Например, в Википедии почти 9 миллионов субъектов и более 170 миллионов отношений между ними.
- Развивающаяся информация: система связывания сущностей также должна иметь дело с развивающейся информацией и легко интегрировать обновления в базу знаний. Проблема развития информации иногда связана с проблемой недостающих сущностей, например, при обработке недавних новостных статей, в которых есть упоминания событий, для которых нет соответствующей записи в базе знаний из-за их новизны.[18]
- Несколько языков: системы связывания сущностей могут поддерживать запросы, выполняемые на нескольких языках. В идеале на точность системы связывания сущностей не должен влиять язык ввода, а сущности в базе знаний должны быть одинаковыми на разных языках.[19]
Отличия от других техник
Связывание сущностей также известно как устранение неоднозначности именованных сущностей (NED) и тесно связано с викификацией и связь записи.[20]Определения часто расплывчаты и незначительно различаются у разных авторов: Alhelbawy и другие.[21] Рассматривайте связывание сущностей как более широкую версию NED, поскольку NED должен предполагать, что сущность, которая правильно соответствует определенному упоминанию сущности с текстовым именем, находится в базе знаний. Системы связывания сущностей могут иметь дело со случаями, когда в справочной базе знаний отсутствует запись для названной сущности. Другие авторы не делают такого различия и используют эти два имени как синонимы.[22][23]
- Викификация - это задача связывания текстовых упоминаний с объектами в Википедии (как правило, ограничение объема английской Википедии в случае межъязыковой викификации).
- Запись связи (RL) считается более широкой областью, чем связывание сущностей, и заключается в поиске записей в нескольких и часто разнородных наборах данных, которые относятся к одной и той же сущности.[14] Связь с записями является ключевым компонентом оцифровки архивов и объединения нескольких баз знаний.[14]
- Признание именной организации находит и классифицирует именованные объекты в неструктурированном тексте по заранее определенным категориям, таким как имена, организации, местоположения и т. д. Например, следующее предложение:
Париж - столица Франции.
- будет обработан системой NER для получения следующего вывода:
[Париж]Город столица [Франция]Страна.
- Распознавание именованных сущностей обычно является этапом предварительной обработки системы связывания сущностей, поскольку может быть полезно заранее знать, какие слова должны быть связаны с сущностями базы знаний.
- Разрешение Coreference понимает, относятся ли несколько слов в тексте к одному и тому же объекту. Например, может быть полезно понять слово, к которому относится местоимение. Рассмотрим следующий пример:
Париж - столица Франции. Это также самый большой город Франции.
- В этом примере алгоритм разрешения кореферентности определит, что местоимение Это относится к Париж, а не Франция или другому лицу. Заметное отличие от связывания сущностей заключается в том, что Coreference Resolution не присваивает какой-либо уникальный идентификатор словам, которые он соответствует, а просто говорит, относятся ли они к одному и тому же объекту или нет.
Подходы к увязке сущностей
Связывание сущностей было горячей темой в промышленности и академических кругах в последнее десятилетие. Однако на сегодняшний день большинство существующих вызовы все еще не решены, и было предложено множество систем связывания сущностей с сильно различающимися сильными и слабыми сторонами.[24]
Вообще говоря, современные системы связывания сущностей можно разделить на две категории:
- Текстовые подходы, которые используют текстовые функции, извлеченные из больших текстовых корпусов (например, Частота термина - обратная частота документа (Tf-Idf), вероятности совпадения слов и т. Д.).[25][16]
- Графические подходы, которые используют структуру графики знаний для представления контекста и отношения сущностей.[3][26]
Часто системы связывания сущностей нельзя строго разделить ни на одну из категорий, но они используют графы знаний, которые были обогащены дополнительными текстовыми функциями, извлеченными, например, из корпусов текстов, которые использовались для построения самих графов знаний.[22][23]
Связывание сущностей на основе текста
Основополагающая работа Кучерсана в 2007 году предложила одну из первых систем связывания сущностей, появившихся в литературе, и решила задачу викификации, связывая текстовые упоминания со страницами Википедии.[25] Эта система разделяет страницы на страницы сущностей, значений или списков, используемых для назначения категорий каждой сущности. Набор сущностей, представленных на каждой странице сущности, используется для построения контекста сущности. Последний этап связывания сущностей - это коллективное устранение неоднозначности, выполняемое путем сравнения двоичных векторов, полученных из созданных вручную функций и из контекста каждой сущности. Система связывания сущностей Кучерсана все еще используется в качестве основы для многих недавних работ.[27]
Работа Rao et al. это хорошо известная статья в области связывания сущностей.[16] Авторы предлагают двухэтапный алгоритм для связывания именованных сущностей с сущностями в целевой базе знаний. Сначала выбирается набор объектов-кандидатов с использованием сопоставления строк, сокращений и известных псевдонимов. Затем выбирается лучшая ссылка среди кандидатов с рейтингом Машина опорных векторов (SVM), использующий лингвистические функции.
Современные системы, такие как предложенная Tsai et al.,[20] использовать вложения слов, полученные с помощью скип-грамм модель в качестве языковых функций и может применяться к любому языку, если предоставляется большой корпус для построения встраивания слов. Как и в большинстве систем связывания сущностей, связывание выполняется в два этапа, с первоначальным выбором объектов-кандидатов и SVM с линейным ранжированием в качестве второго этапа.
Были опробованы различные подходы к решению проблемы неоднозначности сущностей. В оригинальном подходе Милна и Виттена контролируемое обучение используется с использованием якорные тексты сущностей Википедии в качестве обучающих данных.[28] Другие подходы также собирали данные обучения на основе однозначных синонимов.[29]Кулкарни и другие. использовали общее свойство, состоящее в том, что тематически согласованные документы относятся к объектам, принадлежащим к сильно связанным типам.[27]
Связывание сущностей на основе графа
Современные системы связывания сущностей не ограничивают свой анализ текстовыми функциями, созданными из входных документов или текстовых корпусов, но используют большие графики знаний созданы на основе баз знаний, таких как Википедия. Эти системы извлекают сложные функции, которые используют топологию графа знаний или многоступенчатые связи между объектами, которые могут быть скрыты простым анализом текста. Более того, создание многоязычных систем связывания сущностей на основе обработка естественного языка (НЛП) по своей сути сложно, так как требует либо больших текстовых корпусов, которые часто отсутствуют для многих языков, либо созданных вручную правил грамматики, которые сильно различаются между языками. Хан и другие. предложить создание графа неоднозначности (подграф базы знаний, содержащий объекты-кандидаты).[3] Этот график используется для чисто коллективной процедуры ранжирования, которая находит наиболее подходящую ссылку для каждого текстового упоминания.
Другой известный подход к связыванию сущностей - AIDA, который использует серию сложных графовых алгоритмов и жадный алгоритм, который идентифицирует последовательные упоминания в плотном подграфе, также учитывая сходство контекста и особенности важности вершин для выполнения коллективного устранения неоднозначности.[26]
Ранжирование графа (или ранжирование вершин) обозначает такие алгоритмы, как PageRank (PR) и Поиск тем по гиперссылкам (HITS), цель которого - присвоить каждой вершине оценку, отражающую ее относительную важность в общем графике. Система связывания сущностей, представленная в Alhelbawy et al. использует PageRank для выполнения коллективного связывания сущностей на графе разрешения неоднозначности и для понимания того, какие сущности более тесно связаны друг с другом и будут представлять лучшую связь.[21]
Связывание математических сущностей
Математические выражения (символы и формулы) могут быть связаны с семантическими сущностями (например, Википедия статьи[30] или же Викиданные Предметы[31]) помечены их значениями на естественном языке. Это важно для устранения неоднозначности, поскольку символы могут иметь разные значения (например, "E" может быть "энергией" или "ожидаемым значением" и т. Д.).[32][31] Процесс связывания математических объектов можно упростить и ускорить с помощью рекомендаций по аннотации, например, с помощью системы «AnnoMathTeX», размещенной на Wikimedia.[33][34]
Смотрите также
- Контролируемый словарный запас
- Явный семантический анализ
- Геопарсинг
- Извлечение информации
- Связанные данные
- Именованная сущность
- Признание именной организации
- Запись связи
- Устранение неоднозначности смысла слова
- Имя автора Значение
- Coreference
- Аннотации
Рекомендации
- ^ Хачи, Бен; Рэдфорд, Уилл; Нотман, Джоэл; Хоннибал, Мэтью; Карран, Джеймс Р. (1 января 2013 г.). «Искусственный интеллект, Википедия и полуструктурированные ресурсыОценка сущности, связывающейся с Википедией». Искусственный интеллект. 194: 130–150. Дои:10.1016 / j.artint.2012.04.005.
- ^ а б c М. А. Халид, В. Джиджкун и М. де Рийке (2008). Влияние нормализации именованных сущностей на поиск информации для ответов на вопросы. Proc. ECIR.
- ^ а б c Хан, Сяньбэй; Солнце, Ле; Чжао, июнь (2011). «Коллективное связывание сущностей в веб-тексте: метод на основе графиков». Материалы 34-й Международной конференции ACM SIGIR по исследованиям и разработкам в области информационного поиска. ACM: 765–774. Дои:10.1145/2009916.2010019. S2CID 14428938.
- ^ Рада Михалча и Андраш Чомаи (2007)Wikify! Связывание документов с энциклопедическими знаниями. Proc. CIKM.
- ^ «Ссылки на Википедию».
- ^ Викиданные
- ^ Аарон М. Коэн (2005). Неконтролируемая нормализация именованных сущностей генов / белков с использованием автоматически извлекаемых словарей. Proc. ACL -ISMB Workshop on Linking Biological Literature, Ontology and Databases: Mining Biological Semantics, стр. 17–24.
- ^ Шен В., Ван Дж., Хан Дж. Связь сущности с базой знаний: проблемы, методы и решения [J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 27 (2): 443-460.
- ^ Чанг И Ц., Чу Ч., Су И Ц. и др. PIPE: модуль экстракции пассажа белок-белкового взаимодействия для проблемы BioCreative [J]. База данных, 2016, 2016.
- ^ Лу П, Джимено Йепес А., Чжан З. и др. BioNorm: нормализация событий на основе глубокого обучения для управления базами данных реакций [J]. Биоинформатика, 2020, 36 (2): 611-620.
- ^ Славский, Билл. «Как Google использует устранение неоднозначности именованных сущностей для сущностей с одинаковыми именами».
- ^ Чжоу, Мин; Lv, Weifeng; Рен, Пэнцзе; Вэй, Фуру; Тан, Чуаньци (2017). «Связывание сущностей для запросов путем поиска предложений в Википедии». Труды конференции 2017 г. по эмпирическим методам обработки естественного языка. С. 68–77. arXiv:1704.02788. Дои:10.18653 / v1 / D17-1007. S2CID 1125678.
- ^ Ле, Куок; Миколов, Томас (2014). «Распределенные представления приговоров и документов». Труды 31-й Международной конференции Международной конференции по машинному обучению - Том 32. JMLR.org: II – 1188 – II – 1196.
- ^ а б c Хуэй Хан, Хунюань Чжа, К. Ли Джайлс, «Устранение неоднозначности имен в цитировании авторов с использованием метода спектральной кластеризации K-типа», Совместная конференция ACM / IEEE по электронным библиотекам 2005 (JCDL 2005): 334-343, 2005
- ^ STICS
- ^ а б c d Рао, Делип; Макнейми, Пол; Дредзе, Марк (2013). «Связывание сущностей: поиск извлеченных сущностей в базе знаний». Извлечение и обобщение информации из нескольких источников и на нескольких языках. Теория и приложения обработки естественного языка. Springer Berlin Heidelberg: 93–115. Дои:10.1007/978-3-642-28569-1_5. ISBN 978-3-642-28568-4.
- ^ Парравичини, Альберто; Патра, Ричек; Bartolini, Davide B .; Сантамброджо, Марко Д. (2019). «Быстрое и точное связывание сущностей с помощью встраивания графов». Труды 2-го совместного международного семинара по опыту и системам управления графическими данными (GRADES) и аналитике сетевых данных (NDA). ACM: 10: 1–10: 9. Дои:10.1145/3327964.3328499. HDL:11311/1119019. ISBN 9781450367899. S2CID 195357229.
- ^ Хоффарт, Йоханнес; Алтун, Ясемин; Вейкум, Герхард (2014). «Обнаружение новых сущностей с неоднозначными названиями». Материалы 23-й Международной конференции по всемирной паутине. ACM: 385–396. Дои:10.1145/2566486.2568003. ISBN 9781450327442. S2CID 7562986.
- ^ Doermann, David S .; Орд, Дуглас В.; Лори, Дон Дж .; Мэйфилд, Джеймс; Макнейми, Пол (2011). «Межъязыковое связывание сущностей». Неопределенный. S2CID 3801685.
- ^ а б Цай, Чен-Цзы; Рот, Дэн (2016). «Межъязыковая викификация с использованием многоязычных вложений». Труды NAACL-HLT 2016: 589–598. Цитировать журнал требует
| журнал =(помощь) - ^ а б Алхелбави, Айман; Гайзаускас, Роберт. «Коллективное устранение неоднозначности именованных сущностей с использованием подходов ранжирования графов и разбиения по кликам». Материалы 25-й Международной конференции по компьютерной лингвистике COLING 2014: Технические документы (Дублинский городской университет и Ассоциация компьютерной лингвистики): 1544–1555. Цитировать журнал требует
| журнал =(помощь) - ^ а б Цвиклбауэр, Стефан; Зейферт, Кристин; Гранитцер, Майкл (2016). «Устойчивое и коллективное устранение неоднозначности сущностей посредством семантических встраиваний». Материалы 39-й Международной конференции ACM SIGIR по исследованиям и разработкам в области информационного поиска. ACM: 425–434. Дои:10.1145/2911451.2911535. ISBN 9781450340694. S2CID 207237647.
- ^ а б Хачи, Бен; Рэдфорд, Уилл; Нотман, Джоэл; Хоннибал, Мэтью; Карран, Джеймс Р. (2013). «Оценка связи объекта с Википедией». Артиф. Intell. 194: 130–150. Дои:10.1016 / j.artint.2012.04.005. ISSN 0004-3702.
- ^ Цзи, Хэн; Нотман, Джоэл; Хачи, Бен; Флориан, Раду (2015). «Обзор TAC-KBP2015 для обнаружения и связывания трехъязычных объектов». TAC.
- ^ а б Кучерсан, Сильвиу. «Крупномасштабное устранение неоднозначности именованных сущностей на основе данных Википедии». Труды Совместной конференции 2007 г. по эмпирическим методам обработки естественного языка и компьютерному изучению естественного языка (EMNLP-CoNLL): 708–716. Цитировать журнал требует
| журнал =(помощь) - ^ а б Вейкум, Герхард; Татер, Стефан; Танева, Биляна; Испанец, Марк; Пинкал, Манфред; Фюрстенау, Хаген; Бордино, Илария; Йосеф, Мохамед Амир; Хоффарт, Йоханнес (2011). «Надежное устранение неоднозначности именованных объектов в тексте». Материалы конференции 2011 г. по эмпирическим методам обработки естественного языка: 782–792.
- ^ а б Кулкарни, Саяли; Сингх, Амит; Рамакришнан, Ганеш; Чакрабарти, Сумен (2009). Коллективная аннотация сущностей Википедии в веб-тексте. Proc. 15-я Международная конференция ACM SIGKDD. по обнаружению знаний и интеллектуальному анализу данных (KDD). Дои:10.1145/1557019.1557073. ISBN 9781605584959.
- ^ Дэвид Милн и Ян Х. Виттен (2008). Учимся связываться с Википедией. Proc. CIKM.
- ^ Чжан, Вэй; Цзянь Су; Чу Лим Тан (2010). «Связывание сущностей с использованием автоматически созданной аннотации». Труды 23-й Международной конференции по компьютерной лингвистике (Coling 2010).
- ^ Джованни Йоко Кристианто; Горан Тема; Акико Айзава; и другие. (2016). «Связывание сущностей для математических выражений в научных документах». Международная конференция по азиатским электронным библиотекам. Конспект лекций по информатике. Springer. 10075: 144–149. Дои:10.1007/978-3-319-49304-6_18. ISBN 978-3-319-49303-9.
- ^ а б Филипп Шарпф; Мориц Шуботц; и другие. (2018). «Представление математических формул в Content MathML с использованием Викиданных».
- ^ Мориц Шуботц; Филипп Шарпф; и другие. (2018). «Представляем MathQA: математическую систему ответов на вопросы». Обнаружение и доставка информации. Изумруд Паблишинг Лимитед. 46 (4): 214–224. arXiv:1907.01642. Дои:10.1108 / IDD-06-2018-0022. S2CID 49484035.
- ^ "Система рекомендаций по аннотациям формул / идентификаторов AnnoMathTeX".
- ^ Филипп Шарпф; Ян Маккерракер; и другие. (17 сентября 2019 г.). «AnnoMathTeX: рекомендательная система аннотаций идентификаторов формул для документов STEM». Материалы 13-й конференции ACM по рекомендательным системам (RecSys 2019): 532–533. Дои:10.1145/3298689.3347042. ISBN 9781450362436. S2CID 202639987.